We created Lexsi Labs to address some of the fundamental challenges in scaling AI for the next generation: alignment, Interpretability, and safety. And the name is derived from ‘Le eXplainable Safe Superintelligence’. It was Lexssi Labs, but then the name was a bit complicated, so we changed it to Lexsi Labs (removed 1 ‘s’).
Why Lexsi Labs
When we started Lexsi Labs (formerly known as AryaXAI Alignment Labs), our mission was clear but ambitious — to make AI interpretable, aligned, and safe at scale. Over the years, we’ve learned the next frontier of AI will not be defined solely by scale. It will be defined by nuanced modifications to core components, such as alignment and interpretability. Systems that can reason deeply, explain their thinking, and improve themselves without drifting from human intent.
Today, we are proud to announce the public launch of Lexsi Labs — our dedicated research and engineering division focused on building the scientific and technical foundations for Safe Superintelligence.
Lexsi Labs exists to make that future possible. Our mission is simple and audacious:
To make alignment and interpretability an inherent property of intelligence itself — and to build the autonomous AI engineer that can build, scale, and maintain it.
This isn’t about another lab chasing benchmarks. It’s about designing the core research and engineering infrastructure of alignment and understanding — so that intelligence, no matter how advanced, remains aligned, comprehensible, corrigible, and controllable.
The Lexsi Research Stack
At Lexsi Labs, we are building an integrated research stack that connects alignment theory, interpretability science, and agentic autonomy into one continuum.
We’re exploring:
- Efficient Reinforcement Learning (RL) — to make scalable reasoning efficient and adaptive without excessive resource consumption.
- MI-Pruning — mutual information–driven pruning to identify and retain the most semantically meaningful neurons and pathways in deep networks.
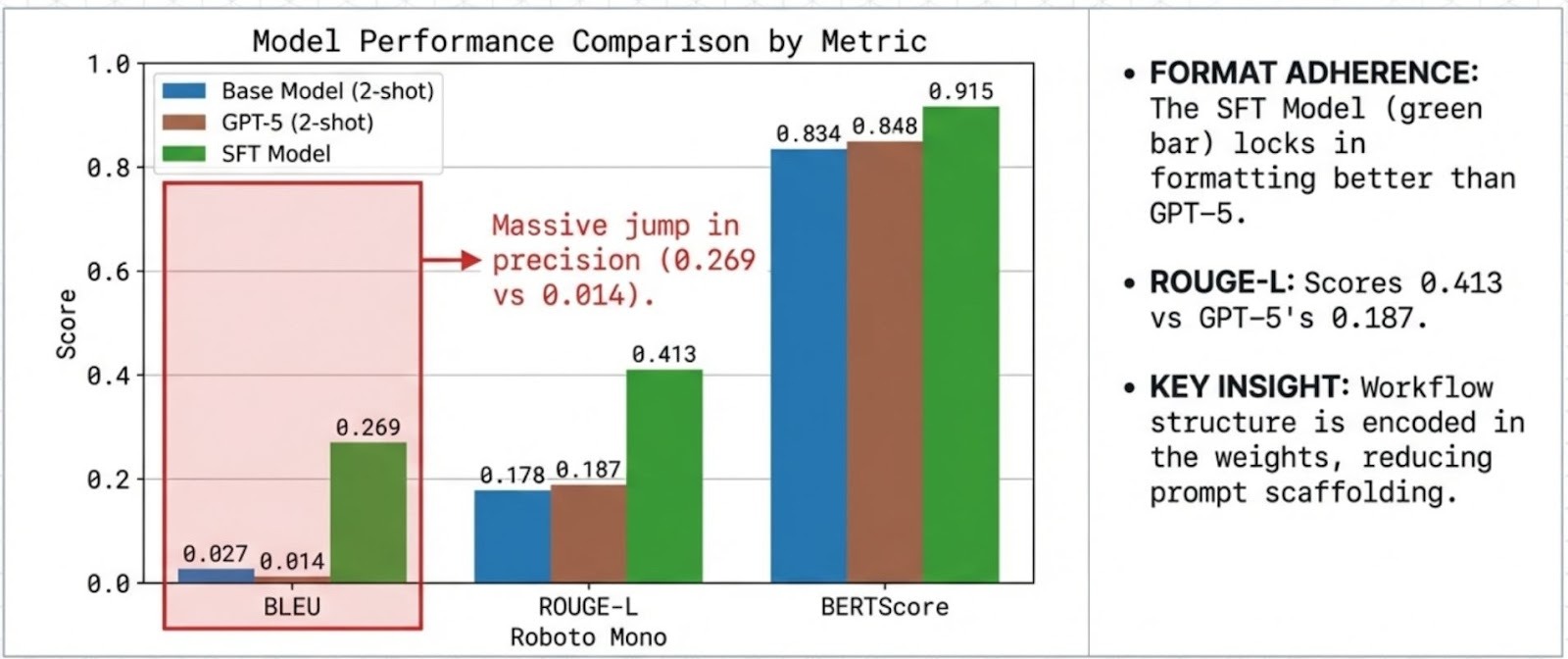
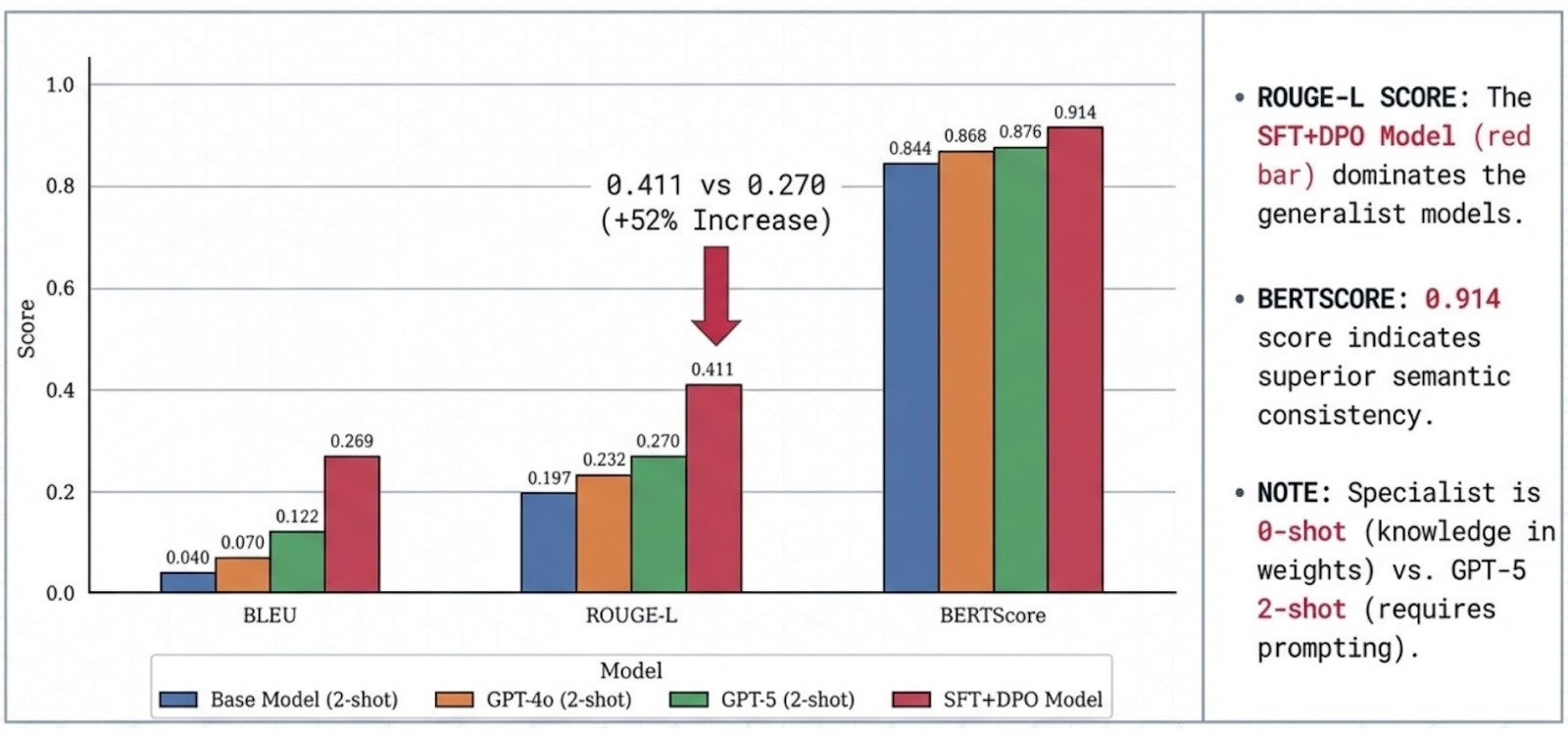
- Safety-Aware Fine-Tuning & Unlearning — developing mechanisms to remove harmful or outdated behaviors while preserving performance.
- Interpretable Telemetry — turning model activations, gradients, and behaviors into live signals that can be visualized and understood.
- AI Engineer Loop — creating the feedback-driven loop where the AI itself can propose, test, and deploy improvements under human supervision.
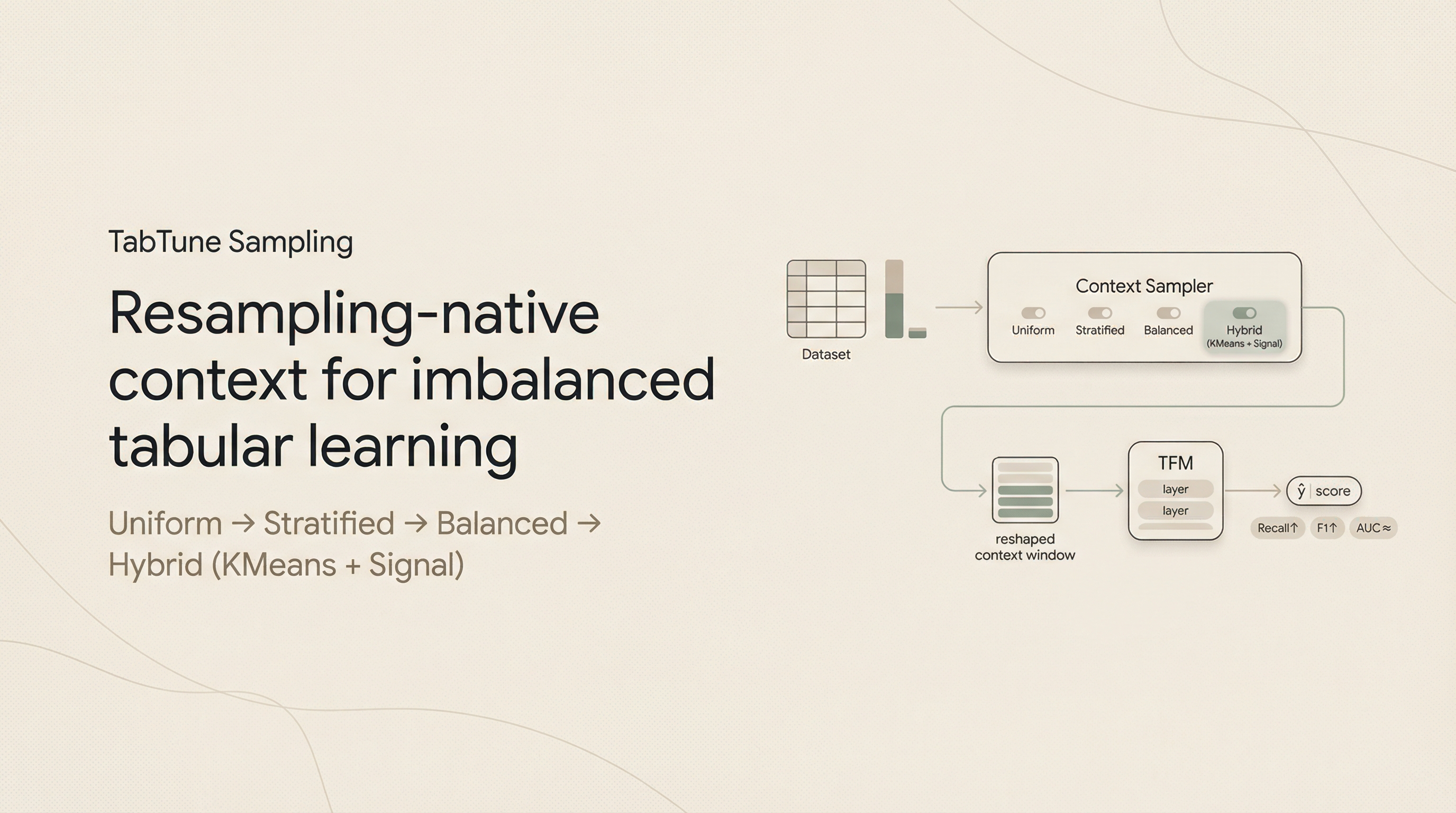
- Specialized foundationla models - models that are specially designed to solve more intrinsic and nuanced proiblems at scale, which eventually will add-up to the capabilities of the system.
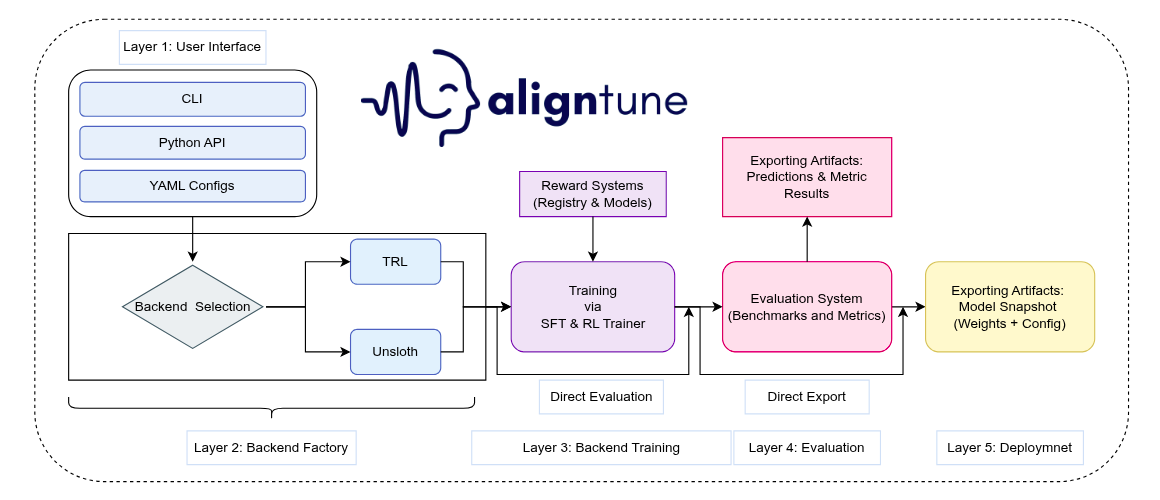
All of this will be directly translated into Lexsi.ai, our AI Engineering platform for developers and enterprises. We will open-source all these components and build the platform using these components.
The Path Forward
This is the beginning of a long journey. We will publish our findings, open-source key components, and work with the broader AI safety community to make interpretability and alignment universal standards — not optional layers.
Lexsi Labs is our commitment to that vision: to make the deepest intelligence the most aligned and trustworthy.
Welcome to Lexsi Labs.