1 Introduction
The advancements in reinforcement learning with verifiable rewards (RLVR) and the GRPO algorithm [1] along with its successors - DAPO [2], Dr. GRPO [3], and others - have enabled rapid improvements in model capabilities on tasks like mathematics and coding. When GRPO proposed eliminating the critic model, it led to substantial savings in computation and VRAM. But this simplification came at a cost: the granularity of credit assignment was reduced. Now all tokens in a generated solution receive exactly the same reward signal, regardless of their actual contribution to the final answer.
There have been attempts to address this problem through various means. Process Reward Models (PRMs) [4, 5] provide step-level supervision by training a separate model to score intermediate reasoning steps - but this requires either expensive human annotation or synthetic labels from a stronger model. Token-level reward methods like TLCR [6] train discriminators to assign per-token rewards, adding architectural complexity. Segment-based approaches like SPO [7] partition sequences at fixed intervals, but this does not adapt to the actual structure of reasoning.
We propose to use the model’s intrinsic signals to determine which parts of the reasoning trace matter most for achieving the correct answer. This is achieved through counterfactual importance: we mask candidate reasoning spans and measure the resulting drop in answer probability. Spans whose removal damages the answer are deemed important and receive higher weight during training. The method requires no auxiliary models and no external annotation. We describe the approach in detail in Section˜3.
Research Question: Can we improve GRPO training by assigning higher credit to tokens that causally contribute to correct answers?
We address this question by introducing counterfactual importance weighting for GRPO-like training algorithms. Our method identifies reasoning spans (arithmetic expressions, intermediate calculations) and measures their causal importance by masking each span and observing the drop in answer probability. Spans whose removal significantly damages the answer receive higher importance scores, which then weight the corresponding tokens during gradient computation.
We focus on mathematical reasoning, where task success is determined by a single verifiable answer. This creates a natural ‘answer sink’ — a concentrated verification signal that makes counterfactual importance estimation well-defined: masking a critical calculation step substantially damages the probability of reaching the correct answer. We hypothesize that domains with more distributed correctness criteria (e.g., code generation, where multiple structural elements must simultaneously be correct) may benefit less from span-level interventions. We test this hypothesis in Section 5.4.
To validate that our importance scores capture meaningful signal rather than noise, we compare four weighting strategies:
- Counterfactual: Weight tokens by their measured causal importance
- Inverted: Weight tokens inversely to importance (control)
- Random: Assign random weights (control)
- Uniform: Standard DAPO with equal weights (baseline)
If counterfactual importance captures genuine signal, we expect: Counterfactual > Uniform => Random > Inverted. Our experiments generally confirm this ordering across multiple models.
Contributions.
- We propose a counterfactual method for measuring token-level importance in reasoning chains, based on answer probability drop under span masking
- We integrate this importance signal into DAPO training through multiplicative token weighting
- We provide systematic experiments across model scales (1.7B–3B parameters) showing consistent improvements of 0.8–1.1 percentage points over baseline DAPO on GSM8K.
- We validate the importance signal through ablations: inverted weighting consistently hurts performance, confirming the method captures genuine causal structure.
- We provide a detailed empirical analysis of what makes reasoning spans important: calculation chains are 11× enriched in critical spans, 3.5% of spans are distractors that hurt performance, and counterfactual weighting concentrates 1.6× more gradient mass on high-importance tokens. These findings characterize the structure of reasoning traces and may inform future credit assignment methods.
We view this work as a proof of concept: demonstrating that counterfactual importance provides consistent, directional signal for credit assignment. The modest but reliable gains (0.8–1.1 pp) and strong ablation results suggest this is a promising direction, with room for future work on stronger interventions, better span detection, and combination with complementary methods.
2 Related Work
Our approach builds on a rich lineage of counterfactual methods in deep learning, which we briefly trace to motivate our contribution.
Foundations and vision origins.
The theoretical basis for counterfactual reasoning derives from Pearl’s causal hierarchy [8] and Rubin’s potential outcomes framework [9], which formalize the distinction between observational correlation and interventional causation. In deep learning, Zeiler and Fergus [10] introduced occlusion sensitivity - systematically masking image regions and measuring prediction changes - establishing the “mask and measure” paradigm for importance estimation. This directly implements Pearl’s do-operator: importance is revealed not by what correlates with predictions, but by what changes them when removed.
Extension to NLP.
Li et al. [11] adapted occlusion analysis to text through representation erasure, removing words or hidden dimensions and observing output changes. They further introduced reinforcement learning to find minimal erasure sets that flip predictions. Subsequent work formalized these intuitions: Integrated Gradients [12] provided axiomatic foundations for attribution, while the “Attention is not Explanation” debate [13] clarified that attention weights reveal where models look, but only intervention reveals what causally matters.
Causal analysis in transformers.
Vig et al. [14] introduced causal mediation analysis to transformers, distinguishing whether information exists in representations from whether it is used. Their intervention procedure consists in isolating causal contributions via running counterfactual inputs while restoring specific components. Meng et al. [15] extended this to causal tracing, using clean/corrupted/patched forward passes to locate where factual knowledge is stored, enabling targeted model editing. These methods demonstrated that causal understanding of transformers is both achievable and actionable.
Counterfactual credit assignment in RL.
Counterfactual reasoning entered reinforcement learning through COMA [16], which uses baselines marginalizing over alternative actions to isolate each agent’s causal contribution. Mesnard et al. [17] formalized counterfactual credit assignment by conditioning value functions on future outcomes to isolate each action’s causal contribution to returns. For LLMs specifically, VinePPO [18] demonstrated that standard value networks fail at credit assignment in reasoning tasks, proposing Monte Carlo estimation from intermediate states. Their key finding - that most reasoning tokens do not affect problem-solving probability - directly motivates identifying the few that do.
Token-level methods for LLM training.
Recent work has pursued finer-grained credit assignment through various proxies: Process Reward Models [4] provide step-level supervision but evaluate correctness rather than causal contribution; TLCR trains discriminators for token-level rewards; RTO [19] extracts implicit token rewards from DPO probability ratios; SPO [7] partitions sequences into segments with Monte Carlo advantage estimation. SCAR [20] applies Shapley values to distribute rewards among tokens - the closest existing work to explicit counterfactual analysis.
The gap we address.
Despite this convergent trajectory, no existing method directly asks: “What would the outcome be if this token were different?” Current approaches estimate importance through learned discrimination, probability ratios, or game-theoretic values - but not through intervention. Our counterfactual importance method completes this arc: we adapt the mask-and-measure methodology from interpretability to provide training signals for policy optimization, using the same interventional logic that revealed which pixels matter for image classification to identify which tokens matter for reasoning.
Concurrent work.
Concurrent work by Ruan et al. [21] proposes Critical Token Fine-Tuning (CFT), which identifies critical tokens for supervised fine-tuning by checking whether alternative token choices preserve answer correctness. Our work addresses a complementary setting: credit assignment in reinforcement learning with policy gradients. Where CFT produces a binary mask (train or skip), we compute continuous importance weights based on answer probability drop, enabling finer-grained gradient modulation. Where CFT requires full regeneration to verify correctness, our span-level masking requires only forward passes. The convergent finding - that counterfactual reasoning identifies tokens that matter - suggests this is a general principle applicable across training paradigms.
3 Method
3.1 Background: DAPO
Critically, the advantage Ai is uniform across all tokens in completion i.
We implement the DAPO algorithm using HuggingFace TRL’s loss_type="dapo" option, which includes token-level loss normalization and decoupled clipping (Clip-Higher) as described by Yu et al. [2]. Dynamic sampling is not used. For clarity, we present the unclipped token-sum form above. Our contribution is the addition of per-token importance weights wt.
Intuition: Addressing gradient dilution.
In standard GRPO-like algorithms, the policy gradient averages over all tokens equally, effectively “diluting” the learning signal with updates from filler phrases, boilerplate setup (“Let me solve this step by step…”), and redundant restatements. Our weighting scheme concentrates gradient mass on tokens with demonstrated causal influence, namely those whose removal damages answer probability. This can be viewed as a non-parametric alternative to Process Reward Models: where PRMs require training an auxiliary value function V(s) to estimate step-wise contributions [4], counterfactual masking provides direct estimates of causal importance using only the policy model itself, with no additional parameters or training data. The connection to Mesnard et al. [17]’s “skill vs. luck” decomposition is direct: by isolating tokens that caused success rather than merely co-occurred with it, we bias gradient updates toward the reasoning steps that actually determined the outcome. Our analysis confirms this intuition: calculation chains receive 11× higher importance than scaffolding tokens (Table˜5), and 3.5% of spans are outright distractors whose removal improves answer probability—content that uniform weighting would incorrectly reinforce.
3.2 Counterfactual Importance Estimation
We measure token importance through causal intervention. Let a completion y be decomposed as y=(r,a), where r is the reasoning prefix and a is the final answer span.
Answer-probability drop.
For each detected reasoning span sk⊂r, we define the counterfactual drop as:
Placeholder design.
We use replacement rather than deletion to preserve positional structure and avoid length-change confounds. The placeholder token is the model’s pad token (or end-of-text token if pad is unavailable), repeated to match the span length.
Why spans, not tokens?
We operate at span granularity rather than per-token for two reasons. First, computational cost: per-token masking would require 200–500 forward passes per completion (one per token), whereas span-level masking requires only 5–10, reducing overhead by 20–50×. Second, semantic coherence: individual tokens lack standalone meaning - “23”, “+”, “45” separately do not constitute a reasoning step, whereas the span “23 + 45 = 68” represents a complete arithmetic operation.
Span detection.
We identify reasoning spans via pattern matching: arithmetic expressions (e.g., 23 + 45 = 68), intermediate calculations, and sentence boundaries. We process up to Kmax=10 spans per completion.
Weight assignment.
3.3 Importance-Weighted Policy Gradient
3.4 Ablation Conditions
To validate that our importance scores capture genuine signal, we compare four weighting modes:
If counterfactual importance captures meaningful signal, we expect: Counterfactual > DAPO ≥ Random > Inverted.
4 Experiments
4.1 Setup
Models.
We evaluate on three base models spanning different architectures and scales: Qwen3-1.7B, Qwen2.5-3B, and Llama3.2-3B. All models are trained with LoRA adapters [22] (r=32, α=32) for parameter efficiency.
Dataset.
We train and evaluate on GSM8K [23], a dataset of 7,473 grade-school math problems requiring multi-step arithmetic reasoning. We evaluate on the standard 1,319-problem test set using exact-match accuracy with numeric parsing.
Training.
We use DAPO with G=8 completions per prompt, learning rate 2.5×10−5, batch size 16 with 4 gradient accumulation steps, for 500 gradient steps. We use temperature 0.6 and top-p 0.95 for generation. Each configuration is run with 3 random seeds.
Reward.
We use binary outcome reward: r=1 if the extracted numeric answer matches the gold answer, r=0 otherwise.
Weighting Hyperparameters.
For counterfactual and ablation conditions, we use weight range [wmin,wmax]=[0.5,4.0], answer boost wans=1.5, and maximum Kmax=10 spans per completion.
4.2 Main Results
Results are summarized in Tables˜1, 2 and 3 and Figure˜1. We observe a consistent pattern across all three model families:
(1) Counterfactual weighting improves over baseline.
Counterfactual importance weighting outperforms vanilla DAPO on all models: +0.9 pp on Qwen3-1.7B, +1.1 pp on Qwen2.5-3B, and +0.8 pp on Llama3.2-3B. The improvement is statistically significant for Qwen2.5-3B (p=0.002) at step 500; AUC improvements are significant for both Qwen models (p<0.05). The effect is consistent throughout training (Figure˜1), not just at convergence.
(2) Inverted weighting underperforms.
Inverting the importance signal - upweighting tokens that don’t matter and downweighting those that do - consistently yields worse performance. On Qwen3-1.7B, inverted underperforms DAPO by 1.5 pp; on Llama3.2-3B the gap widens to 1.8 pp. This directional validation confirms the importance signal captures genuine causal structure rather than acting as arbitrary regularization.
(3) Random weighting is broadly neutral.
Random weights perform comparably to or slightly below vanilla baseline, confirming that non-uniform weighting alone is insufficient - the direction of importance matters. Counterfactual weighting, which assigns high weights to causally important spans, yields consistent gains across all seeds and models.
(4) Results hold across architectures.
Counterfactual weighting consistently outperforms all baselines across both Qwen and Llama model families, suggesting the method generalizes beyond a single architecture.
(5) Improved sample efficiency.
Beyond final accuracy, counterfactual weighting accelerates learning throughout training. On average, CF reaches DAPO’s final accuracy (at step 500) substantially earlier: at step 100 for Qwen3-1.7B, step 125 for Qwen2.5-3B, and step 225 for Llama3.2-3B. This improved sample efficiency can offset the 32–74% per-step overhead: to reach a given target accuracy, CF often requires comparable or less total wall-clock time than vanilla DAPO.
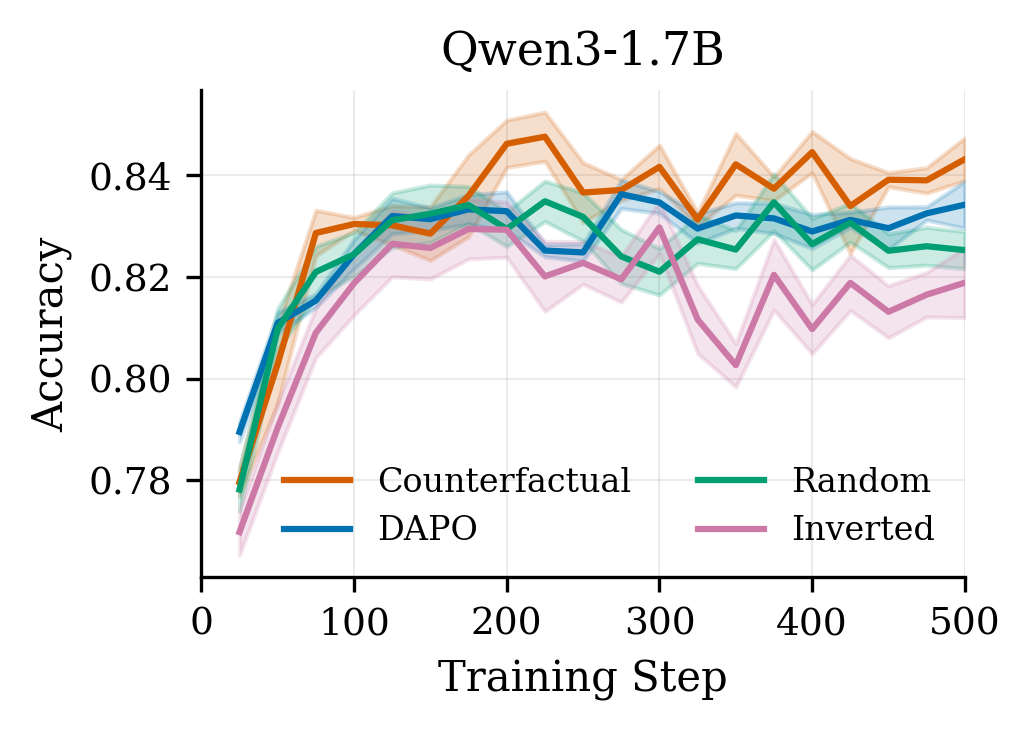
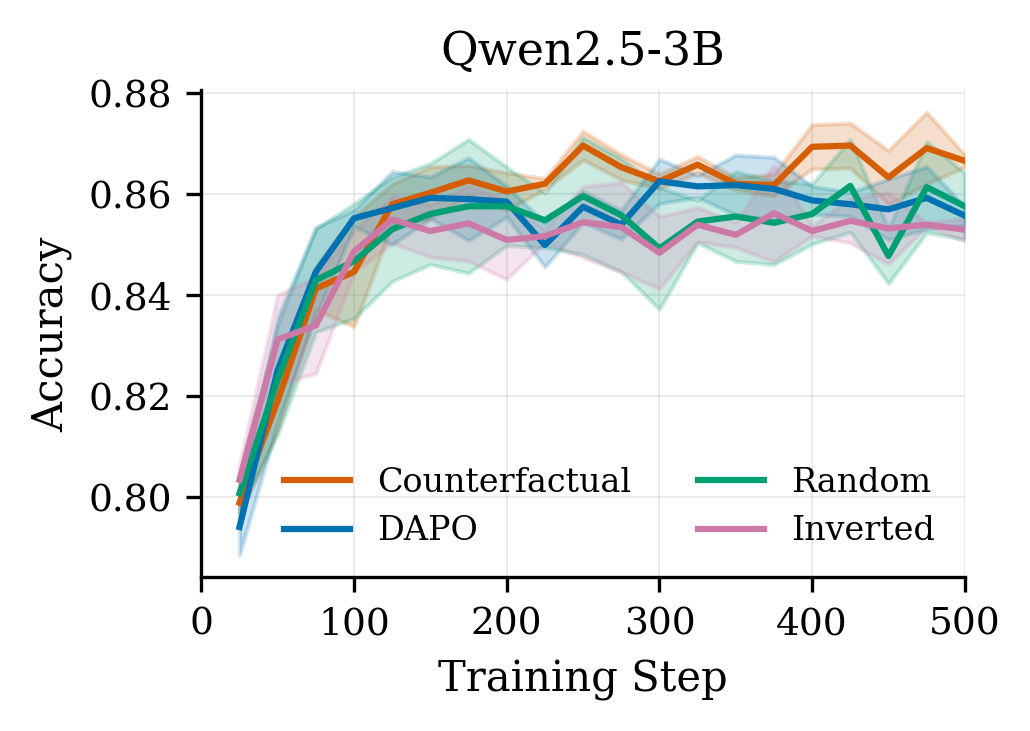
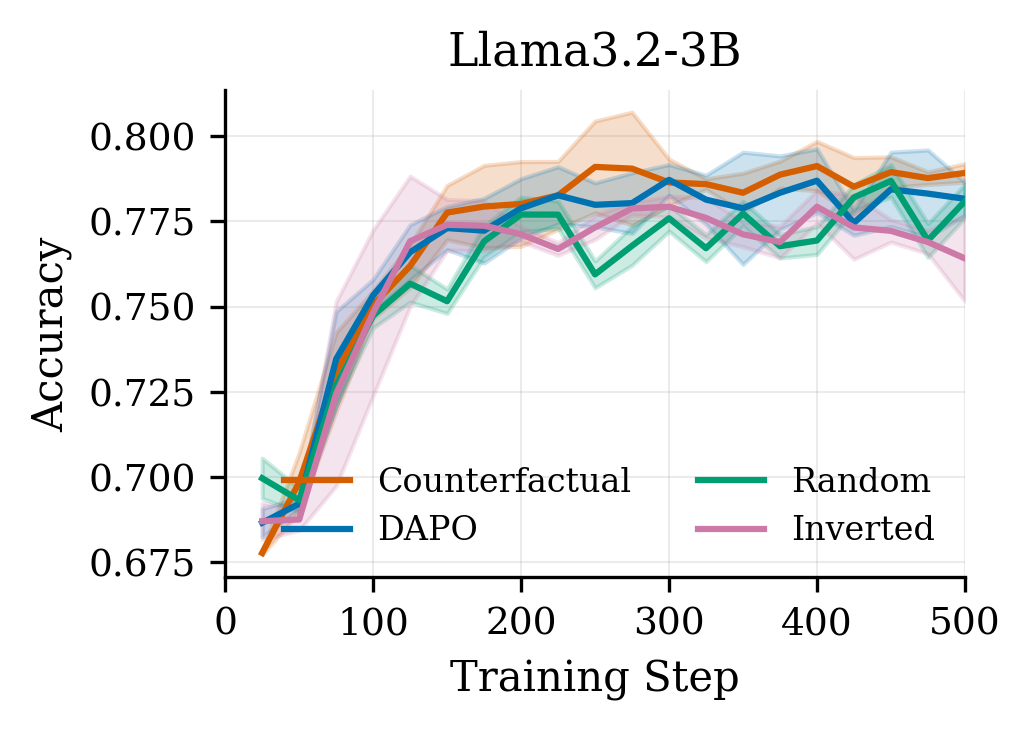
Figure 1:Training curves on GSM8K. Counterfactual weighting (red) consistently outperforms vanilla DAPO (blue) throughout training. Inverted weighting (purple) underperforms, validating that importance direction matters. Shaded regions show ±1 std across seeds.
4.3 Analysis
We analyze counterfactual importance scores across 13,737 spans from 1,467 completions. Beyond validating our method, this analysis reveals structural properties of reasoning traces—what content is critical, what is scaffolding, and what is actively harmful—that may inform credit assignment methods beyond our specific approach.
Importance distribution.
The distribution of importance drops is heavily left-skewed (skewness =−2.19, kurtosis =7.73), indicating that most spans have moderate importance while a minority are critical. Table˜4 shows the breakdown: only 10.9% of spans are “critical” (drop <−500), while 45.4% fall in the “moderate” range. Notably, 3.5% of spans (481 total) are distractors: masking them actually improves answer probability, suggesting they add noise rather than signal.
What content is critical?
We analyze textual patterns that distinguish critical spans (drop <−500, N=1,500) from low-importance spans (−50< drop <0, N=1,349). Table˜5 reveals striking differences: calculation chains (spans containing sequential equations like “x=y=z”) are 11.2× more prevalent in critical spans than low-importance ones. Multiplication and division operations show 6.5× enrichment, while proportion and rate reasoning shows 3.9× enrichment. Conversely, equation setup (“let x denote…”) is depleted in critical spans (0.37×) - such spans are necessary scaffolding but not causally important for reaching the answer.
Span position matters.
We partition spans into early (first third), middle, and late (last third) positions within each completion. Middle spans are most important (mean drop =−270), followed by late (−233) and early (−201). All pairwise differences are highly significant (p<10−10). This aligns with typical solution structure: early spans restate the problem, middle spans contain core derivations, and late spans state conclusions.
Span length correlates with importance.
Longer spans receive higher importance scores (r=−0.56, p<10−100). This is expected: longer spans contain more reasoning content and their removal causes greater disruption. However, the moderate correlation indicates length alone does not determine importance - a verbose restatement can be long but unimportant.
Correct vs. incorrect completions.
Importance distributions differ slightly between correct (N=2,353 spans, mean =−221) and incorrect (N=11,384 spans, mean =−235) completions, with incorrect completions showing marginally higher importance scores (p=0.012). However, this small difference (6%) suggests our method primarily measures structural importance - which spans are causally connected to the answer - rather than correctness. A span can be critically important for producing a wrong answer.
Distractor spans.
The 481 spans with positive importance drops (3.5%) represent content that hurts answer probability when present. Of these, 76.1% occur in incorrect completions, suggesting verbose or redundant reasoning correlates with failure. Manual inspection reveals distractors are typically step headers (“Step 1: Calculate the total miles…”), redundant restatements of given information (“Humans have 2 legs”), or verbose setup without computational content. The strongest distractor (drop =+633) is the span “Step 1: Calculate the total miles Jerome plans to ride in the first 12 days” - pure scaffolding that the model navigates better without.
Token-level weight distribution.
Across 858,798 non-padding tokens, the weight range [0.5,4.0] is fully utilized: 1.2% of tokens receive minimum weight (0.5×) while 21.8% receive maximum weight (4.0×, including answer tokens). This confirms the method produces substantial differentiation rather than near-uniform weights.
Gradient concentration.
We quantify how counterfactual weighting redistributes gradient mass compared to uniform weighting. Across 858,798 tokens, we categorize by normalized importance: high (I^>0.8), medium (0.5<I^≤0.8), and low (I^≤0.5). Under uniform weighting, gradient contribution is proportional to token count. Under CF weighting, high-importance tokens (26.3% of tokens) receive 42.5% of gradient mass - a 1.6× concentration. Conversely, low-importance tokens (53.9% of tokens) receive only 32.2% of gradient mass - a 0.6× dilution. This represents a 2.7× shift in relative gradient allocation from filler tokens to causally important reasoning steps, empirically validating the “gradient dilution” intuition: CF weighting focuses parameter updates on the tokens that actually determine task success.
Qualitative example.
Table˜6 shows importance scores for a GSM8K problem where Oliver avoids mango dishes at a buffet. The problem requires computing which dishes contain mango (via fractions and sums) then subtracting from the total.
The method clearly differentiates critical reasoning from scaffolding. The fraction calculation “16×36=6” receives highest importance (|Δ|=806) because it derives a quantity not given in the problem. The sum of mango dishes (|Δ|=646) aggregates this result. In contrast, restatements of given information (“Total dishes: 36”, “Mango jelly: 1”) receive 4–5× lower importance. Notably, the final arithmetic “36−10+2=28” scores lowest (|Δ|=102)—once the mango count is established, the subtraction is mechanical.
Summary.
Our analysis reveals that counterfactual importance successfully identifies reasoning structure: calculation chains and arithmetic operations are critical (11× and 6.5× enriched); setup and headers are scaffolding (0.4–0.6× depleted); and 3.5% of spans are actively harmful distractors. The method captures causal importance rather than surface features, though length and position correlate as expected. These findings support using counterfactual importance to focus gradient updates on the spans that actually determine task success.
4.4 Code Generation: A Negative Result
We evaluated counterfactual weighting on MBPP+ code generation to test whether the method generalizes beyond mathematical reasoning. Table˜7 shows results across training checkpoints.
We find no significant improvement over baseline DAPO - at the best checkpoint, vanilla slightly outperforms CF (54.2% vs 53.7%). Early training shows a small CF advantage, but vanilla takes over from step 150 onward. Results are largely within noise (±1–2%).
We hypothesize this null result stems from the distributed nature of code correctness. In math, a single numeric answer serves as the verification target: masking a calculation chain destroys the unique path to that “answer sink,” producing a strong counterfactual signal. In code, correctness requires multiple structural elements - control flow, variable bindings, return statements - to be simultaneously correct. No single span’s removal catastrophically damages output probability in the same way. Additionally, our arithmetic-focused span detection (equations, calculations) fails to capture code-relevant structure such as conditionals, loops, and function calls.
This negative result clarifies the method’s scope: counterfactual importance weighting is effective when task success depends on a small number of critical reasoning steps with a concentrated verification signal, as in mathematical problem-solving.
5 Limitations
Computational overhead.
The method requires additional forward passes to estimate span importance, adding 32–74% overhead depending on the number of spans per completion. While the optimizations in Appendix˜A (batched masking, caching, early termination) mitigate this cost, the overhead remains substantial for large-scale training. The improved sample efficiency can offset this cost, but practitioners must weigh per-step overhead against convergence benefits.
Domain specificity.
Our span detection relies on regex patterns tuned for arithmetic reasoning: equations, calculations, and sentence boundaries. This works well for GSM8K but fails to capture domain-relevant structure in other settings. The null results on MBPP+ (Section˜4.4) demonstrate this limitation—conditionals, loops, and function definitions are not detected as spans. Extending the method to new domains requires designing appropriate span detectors, which may require domain expertise.
Imperfect causal intervention.
Span masking is an approximation to true counterfactual reasoning. Replacing tokens with placeholders may introduce distributional shift: the model has never seen padding tokens mid-sequence during pretraining, so its behavior under masking may not reflect “what would happen if this information were absent.” Alternative interventions (e.g., resampling from the model’s own distribution, or activation patching) could provide cleaner causal estimates but at higher computational cost.
Answer-centric importance.
Our importance metric measures contribution to the final answer probability. This captures causal importance for outcome but may miss spans that improve reasoning quality without directly affecting the answer (e.g., clear explanations, error checking). For tasks where intermediate reasoning quality matters beyond final accuracy, alternative importance definitions may be needed.
Limited scale.
We evaluated on models up to 3B parameters. Whether counterfactual weighting provides similar benefits at larger scales (7B+) remains untested. Larger models may have more robust credit assignment internally, potentially reducing the benefit of explicit importance weighting.
6 Conclusion
We introduced counterfactual importance weighting for GRPO-like family of algorithms. The method identifies causally important reasoning spans by measuring answer probability drop under masking, then uses this signal to reweight token-level policy gradients. Experiments across three model families demonstrate consistent improvements of 0.8–1.1 percentage points over baseline DAPO, with faster convergence to equivalent accuracy. While these gains are modest, they are consistent across architectures, validated by ablations, and achieved with no auxiliary models—suggesting that counterfactual signal is both real and usable. Analysis of 13,737 spans reveals the method correctly identifies calculation chains as critical (11× enriched) while deprioritizing scaffolding tokens, concentrating 1.6× more gradient mass on high-importance reasoning steps.
Beyond the training improvements, our analysis reveals structural properties of reasoning traces that may be independently useful. The finding that 3.5% of spans are outright distractors—content whose removal improves answer probability—suggests that standard uniform-credit training actively reinforces harmful content. The 11× enrichment of calculation chains in critical spans, versus 0.37× depletion of equation setup, quantifies the intuition that “not all tokens matter equally” and provides a basis for future work on adaptive curricula or data filtering.
The approach requires no auxiliary models, no external annotation, and adds only forward-pass overhead - providing a non-parametric alternative to Process Reward Models that extracts credit assignment signal directly from the policy model’s own probability estimates. The key validation is directional: inverting the importance signal hurts performance, confirming that the method captures genuine causal structure rather than acting as arbitrary regularization.
However, the method does not transfer to code generation (Section˜4.4), where correctness is distributed across multiple structural elements rather than concentrated in a single answer. Future work should explore domain-specific span detection for code (e.g., control flow, function boundaries) and the computational optimizations discussed in Appendix˜A.
Impact Statement
This paper presents work whose goal is to advance the field of Machine Learning by improving credit assignment in reinforcement learning for language models.
Potential benefits.
Our method improves training efficiency, potentially reducing the computational resources and energy required to achieve a given capability level. The analysis of reasoning traces—identifying which content helps versus hurts answer probability—may contribute to more interpretable training processes. Understanding what makes reasoning steps causally important could inform curriculum design, data filtering, and debugging of model failures.
Potential risks.
As with any work that improves language model training, our method could accelerate the development of more capable models, which carries dual-use concerns. However, we note that our improvements are modest (0.8–1.1 pp) and focused on mathematical reasoning rather than general capabilities. The method’s reliance on verifiable answers limits its applicability to domains with clear correctness criteria, reducing concerns about training models on subjective or potentially harmful content.
Broader considerations.
The finding that 3.5% of reasoning spans are “distractors” whose removal improves performance suggests that current training methods may inadvertently reinforce unhelpful or misleading content. While we use this observation to improve training, it also highlights a potential failure mode of uniform credit assignment that the research community should be aware of. We do not foresee specific negative societal consequences beyond those generally associated with improved language model capabilities.