1. Introduction
Tabular data remain the most common form of real-world data, spanning domains such as healthcare, finance, and scientific research. Despite the remarkable progress of deep learning in natural language processing [liu2023pre, yu2024natural] and computer vision [goldblum2023battle], gradient boosted trees (GBTs) remain the predominant state-of-the-art (SOTA) for tabular prediction tasks. In other data modalities, foundation models—particularly Large Language Models (LLMs) [DBLP:conf/nips/00020D24, DBLP:conf/nips/LiZLML0HY24]—have significantly advanced the ability to tackle new tasks and few-shot learning. This is largely due to their remarkable in-context learning (ICL) capabilities [DBLP:conf/iclr/Zhang0YOKZY025, DBLP:conf/uss/CarliniTWJHLRBS21], which enable them to capture patterns directly from prompts without updating their parameters. This success combined with the pervasiveness of tables have spurred interest in tabular foundation models [DBLP:conf/icml/BreugelS24].
Although LLMs are primarily designed to process natural language, recent efforts have explored fine-tuning them for tabular data tasks [tabllm, tmlr]. These approaches typically rely on table serialization, which is the process of converting table rows into text or sentences suitable for tokenization. For instance, [DBLP:conf/nips/0001PS24] fine-tuned a Llama 3-8B model on a large corpus of serialized tables and demonstrated that this strategy can outperform traditional tree-based models in few-shot scenarios. However, such language model–based approaches face inherent challenges. Their limited context windows restrict the number of serialized examples that can be processed simultaneously (e.g., up to 32 or 64 shots in [DBLP:conf/nips/0001PS24]), and it remains uncertain whether LLMs can reliably interpret and reason over numerical values [DBLP:conf/naacl/ThawaniPIS21].
Recently, tabular in-context learning has emerged, adapting the ICL paradigm—central to large language models—to tabular data, enabling pretraining across diverse tables and rapid task adaptation without gradient updates. TabPFN [tabpfn] pioneered this approach by meta-training a transformer on synthetic datasets generated via structural causal models. Its encoder–decoder design lets test samples attend to training examples for zero-shot prediction, but alternating column- and row-wise attentions make large training sets computationally costly. TabDPT [tabdpt] achieves comparable performance using similarity-based retrieval, though its diffusion process adds overhead. TabPFN-v2 [tabpfn2] extended row-based encoding to datasets exceeding 10,000 samples. TabICL [tabicl] further refined this with a table-native transformer comprising column embeddings, row interactions, and an ICL head. Its SetTransformer-based column encoder and label-aware in-context learner achieve state-of-the-art results, but its row encoder (tf_row) applies a single homogeneous attention over all features, ignoring local groupings, multi-scale interactions, and structured aggregation. This limitation is pronounced in high-dimensional, heterogeneous tables where features naturally form semantic groups (e.g., demographics, vitals, labs) and dependencies span multiple scales. Additionally, TabICL treats synthetic tables as individual supervised tasks rather than support/query episodes, producing an implicit few-shot signal that may misalign with test-time objectives.
To address these limitations, we introduce Orion-Bix11 ,which enhances TabICL with two key improvements: (1) a biaxial row encoder replacing tf_row with complementary attention modes—standard cross-feature, grouped, hierarchical, and relational—aggregated via multiple CLS tokens, explicitly modeling local groups, coarse-scale interactions, and global patterns; and (2) a meta-learning training regime that constructs support/query episodes from synthetic tables, optionally using kNN-based support selection, aligning training with few-shot test-time objectives. Orion-Bix preserves TabICL’s strengths in column-wise SetTransformer embeddings and label-aware ICL while addressing its row-level and training limitations.
2. Orion-Bix: Proposed Approach
Orion-Bix retains two core TabICL [tabicl] components: the SetTransformer column encoder and the label-aware in-context learner, while introducing two major changes: (1) a biaxial row encoder that replaces the single-stage tf_row and provides structured multi-scale feature reasoning, and (2) a meta-learning training regime that constructs explicit support/query episodes from synthetic tables, optionally using kNN-based support selection. An overview of the complete architecture is shown in Figure 1.
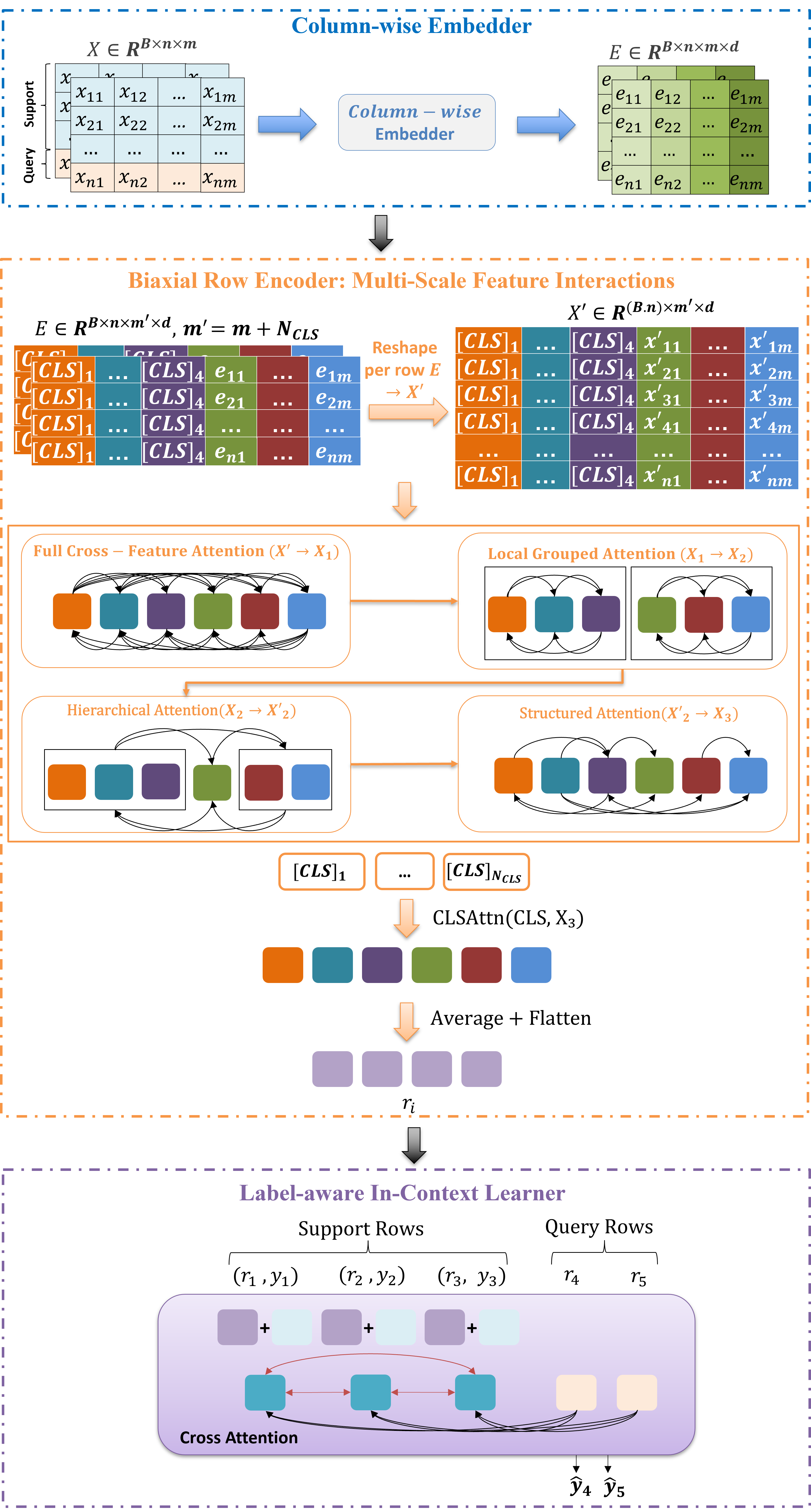
2.1. Problem Setting and Data Representation
2.2. Column-wise Embedding
We adopt the original TabICL [tabicl] column-wise embedder to map each feature to a d-dimensional representation per cell. The embedder uses a Set Transformer, TFcol, that treats each column as a permutation-invariant set of values across all rows.
2.2.1. Input and CLS Reservation.
2.2.2. Skippable Linear Projection.
2.2.3. SetTransformer Over Rows for Each Column.
2.2.4. Feature-Wise Weight–Bias Parameterization.
2.3. Biaxial Row Encoder: Multi-Scale Feature Interactions
2.3.1 Input Reshaping.
2.3.2. Bi-Axial Attention Block.
2.3.3. Multi-CLS Aggregation.
2.4. In-Context Learner
The final module, denoted ICLearning, performs in-context inference: given row representations and support labels, it predicts labels for the query rows.
2.4.1. Label Injection.
2.4.2. ICL Encoder with Split Attention Mask.
2.4.3. Decoder and Hierarchical Classification.
2.5. Meta-Training with Synthetic Episodic Data
TabICL is trained on synthetic tabular data drawn from a configurable prior, optimizing a global objective that encourages robust in-context behaviour across a wide range of tasks. However, the original training schedule treats each synthetic dataset as a single supervised task, without explicitly structuring the optimization around support/query episodes. This leads to two limitations:
- Implicit few-shot signal: The model learns to infer from sequence prefixes, but the few-shot structure (support vs. query) is only partially enforced by attention masks; it is not the primary unit of optimization.
- Uncontrolled support selection: Support rows are not explicitly chosen to be informative or diverse with respect to query rows; many updates are driven by redundant or suboptimal supports.
Orion-BiX adopts an explicit meta-learning perspective on top of a similar synthetic data prior:
- Synthetic tables are generated from a broad prior over feature counts, label spaces, sequence lengths, and distributions, and treated as a pool of potential tasks.
- Episode Construction: An EpisodeGenerator converts these tables into many small episodes, each defined by a support set, a query set, and a per-task feature-count d. Episodes are formed either by random splits or by kNN-based support selection that explicitly chooses support rows that are both relevant and diverse with respect to queries.
- A MetaLearningDataset yields episodes in manageable chunks, and the MetaLearningTrainer processes thousands of episodes per update via micro-batching, gradient accumulation, mixed precision, and (optionally) distributed data parallelism.
This explicit meta-learning formulation brings several advantages over the original TabICL training:
- Stronger alignment with the test-time objective: The model is always optimized in the exact regime in which it will be evaluated: given a small support set and a query set, infer query labels purely from in-context information.
- Better use of synthetic diversity: Each synthetic table can yield many distinct episodes with different support/query splits. This increases the effective number of tasks seen during training and exposes the model to a broader spectrum of few-shot situations
- Support-set quality control: kNN-based episode construction selects support examples that are both close to and diverse for the query set, reducing the proportion of updates driven by uninformative or redundant supports.
- Stability and scalability: Micro-batching, gradient accumulation, and AMP allow Orion-Bix to train on large episode counts without exhaustively increasing memory usage, while DDP and checkpoint management make multi-GPU training robust.
In summary, Orion-Bix keeps the core strengths of TabICL [tabicl]—column-wise SetTransformer embeddings and a label-aware in-context Transformer—but introduces a biaxial row encoder that better matches the structure of tabular feature spaces and a meta-learning training regime that more directly optimizes for few-shot in-context performance.
2.6. Inference Pipeline and Practical Interface
For practical deployment on real-world tabular datasets, Orion-BiX is wrapped in a scikit-learn–compatible classifier that automates preprocessing and uses an ensemble of transformed views.
2.6.1. Preprocessing and Feature Engineering.
Given an input table X, the wrapper:
- detects numerical and categorical features and converts all columns to numeric form;
- imputes missing numerical values (e.g., with medians) and handles categorical missingness consistently;
- optionally applies one of several normalization schemes (none, power transform, quantile normalization, robust scaling);
- clips outliers beyond a configurable z-score threshold;
- applies feature shuffling strategies (none, circular shift, random, Latin patterns) to build diverse column orders.
2.6.2. Ensemble of Transformed Views.
The preprocessor constructs multiple transformed “views” of the dataset, each corresponding to a choice of normalization method and feature permutation. For each view:
- a support/query split is formed (e.g., using a subset of training points as the support set),
- the transformed table is passed through the Orion-BiX model, which produces logits or probabilities for the query rows.
Across views:
- logits are re-aligned to correct for any class shifts induced by permutations,
- predictions are averaged over ensemble members,
- an optional temperature-scaled softmax converts logits to probabilities.
This ensemble scheme improves stability and robustness, especially for datasets with skewed distributions or strong feature-order effects.
Summary.
In summary, Orion-BiX combines:
- a column embedder that learns distribution-aware feature embeddings,
- a biaxial row encoder that models feature interactions at several structural scales and compresses them into multiple CLS summaries, and
- a label-aware in-context learner that uses masked attention and hierarchical classification to handle few-shot tasks with arbitrary label spaces,
all trained via episodic meta-learning on diverse synthetic tables and exposed through an inference pipeline that integrates seamlessly with standard tabular workflows.
3. Experimental Evaluation
We evaluate Orion-Bix against TabICL and other baselines to highlight the benefits of biaxial attention and meta-learning. Our experiments focus on three aspects: (i) domain-specific performance on datasets with natural feature structure, (ii) support set quality to assess robustness, and (iii) few-shot learning curves across varying support sizes. These analyses target the improvements motivating Orion-Bix: structured multi-scale feature interactions and enhanced few-shot adaptation.
3.1. Evaluation Setup
3.1.1. Datasets.
We construct domain-specific evaluation suites by grouping datasets from public benchmarks (e.g., TALENT [talent] and OpenML-CC18 [openmlcc18]) according to application domain, allowing assessment in contexts where feature structure and heterogeneity are most relevant. The domains are: Medical Finance. These domains exhibit the high-dimensional, structured, and multi-scale features that Orion-Bix is designed to handle.
3.1.2. Evaluation Metrics.
For each dataset, we report overall classification accuracy (ACC), class-weighted F1 to account for imbalance, and mean rank across datasets within each domain based on accuracy. All models use official train/test splits unless noted.
3.2. Domain-Specific Performance
Table 1:Domain-specific performance for Medical, Finance and Energy datasets from the benchmark suites. Formatting: Bold = 1st place; underlined= 2nd place within each group.
ModelsMedic
Table 1 reports results on Medical, Finance, and Energy domains. Orion-Bix achieves the best mean rank in Medical (4.10) and Finance (5.39), outperforming TabICL and showing competitive performance against gradient-boosted baselines.
- Medical. Orion-Bix attains rank 4.10 (vs. TabICL 5.54), accuracy 0.7893, and F1 0.7759. While TabPFN slightly exceeds accuracy (0.7984), Orion-Bix’s superior ranking indicates more consistent performance across diverse datasets. The gains reflect the benefit of biaxial attention on grouped and hierarchical features typical in medical data.
- Finance. Orion-Bix leads with rank 5.39 (vs. TabICL 6.60), accuracy 0.8206 (vs. 0.8125), and F1 0.8125 (vs. 0.7942). Finance datasets feature strong hierarchies and multi-scale dependencies, where biaxial attention better captures structured relationships, notably improving F1 by +1.83 points over TabICL.
These results highlight two design benefits of Orion-Bix:
- Biaxial attention for structured features: Gains are largest in domains with natural feature groups and hierarchies, confirming that modeling local (grouped), coarse-scale (hierarchical), and global (relational) interactions improves representations over a single attention stack.
- Multi-CLS aggregation: Maintaining multiple CLS tokens preserves distinct feature aspects, capturing both rare patterns and common global signals, leading to more robust predictions.
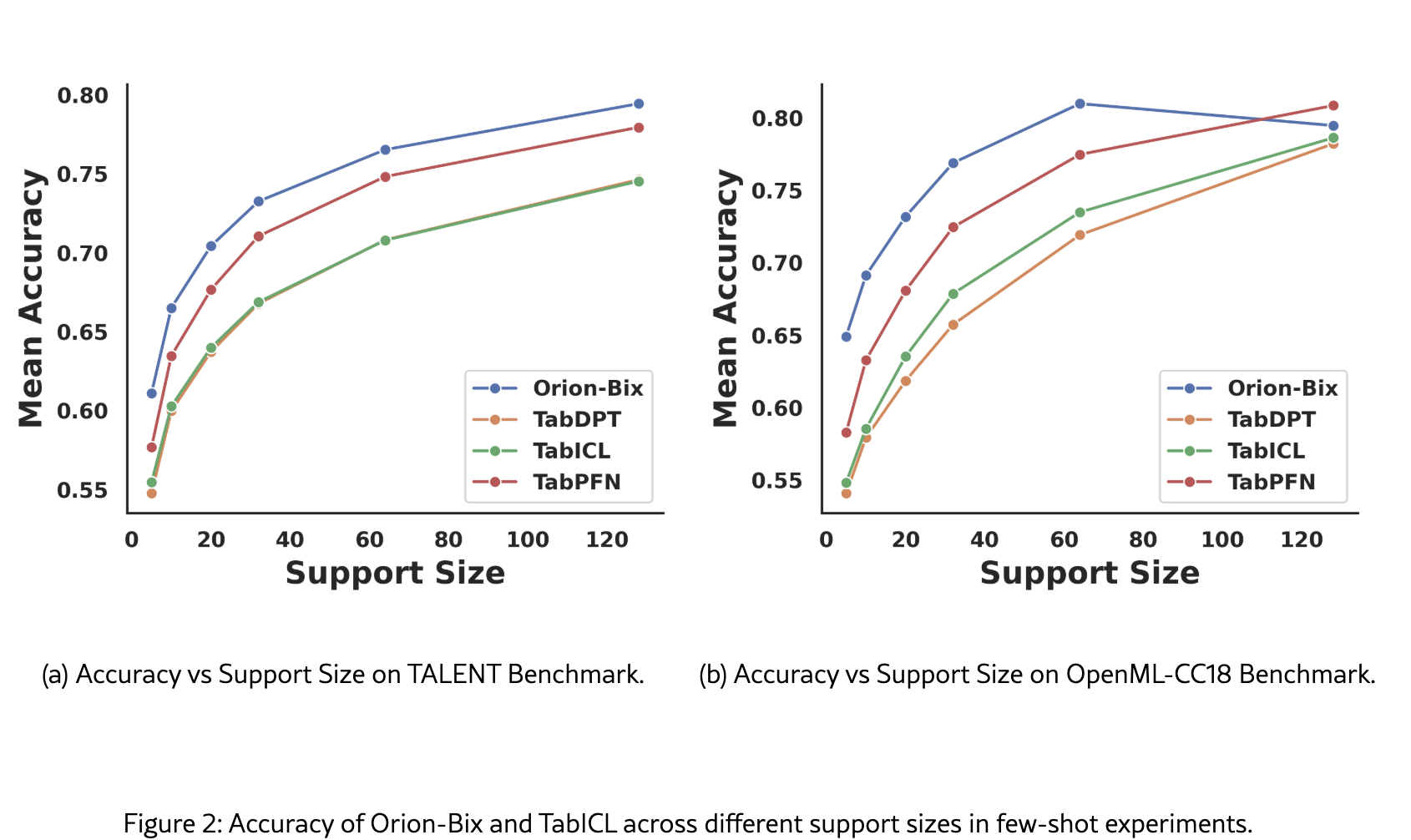
3.3 Few-Shot Performance
Protocol.
Results.
3.4 Support Set Quality Analysis
We study how support set selection affects few-shot performance by comparing random vs. diverse (kNN-based) sampling at inference. This tests whether Orion-Bix’s meta-learning, which constructs diverse support/query episodes during pre-training, improves robustness to support quality.
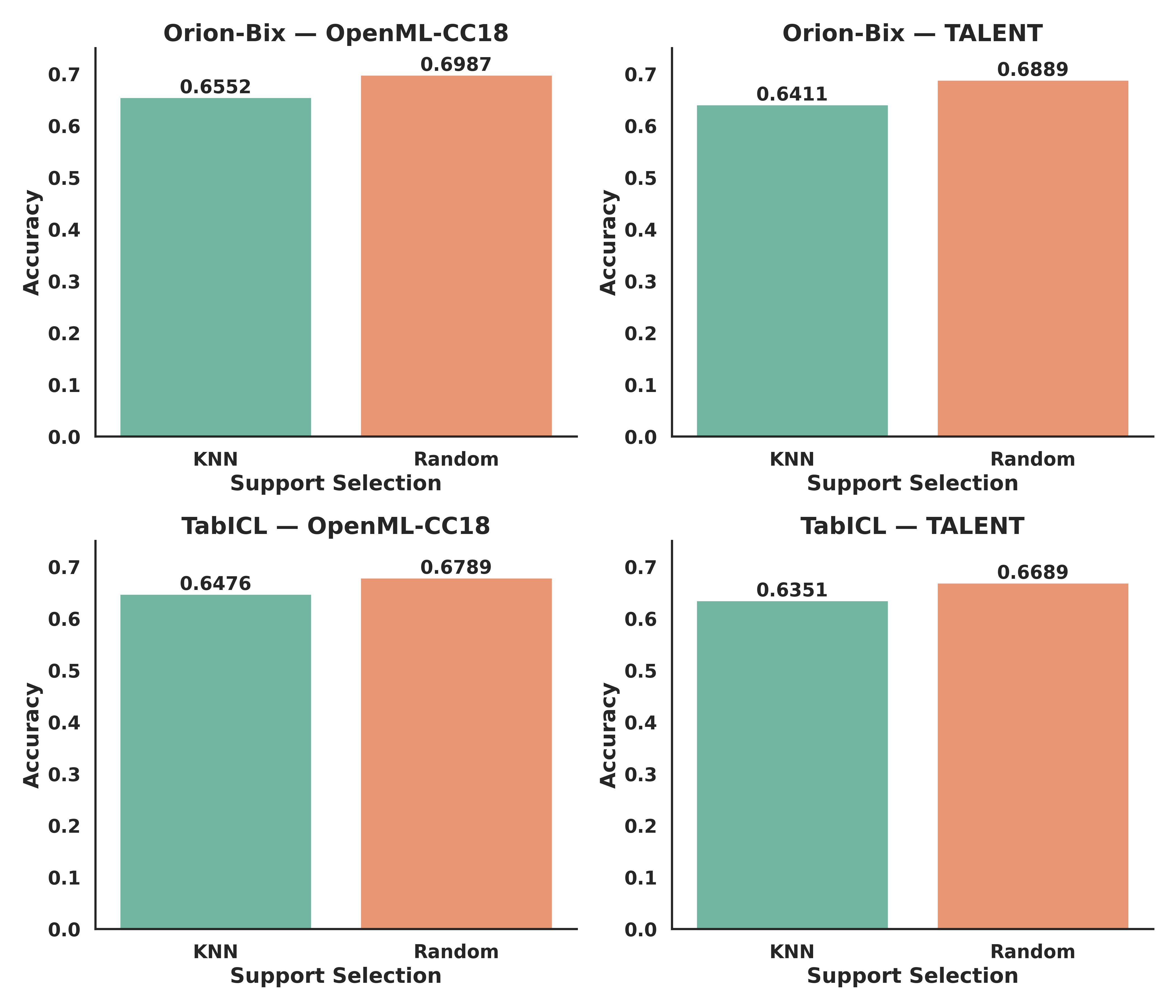
Figure 3:Accuracy of Orion-Bix and TabICL on OpenML and TALENT benchmarks. Bars indicate support selection strategies, averaged over datasets for each model.
Protocol.
Each test dataset is split 80/20 into train/test sets. A support set of size k=32 is drawn using: (i) Uniform sampling, ensuring all classes are represented, and (ii) Diverse (kNN-based), selecting examples close to test queries and maximally diverse. Models are evaluated with standard ICL on the same support/query splits, repeated across multiple seeds for statistical significance.
Motivation.
This protocol measures inference-time robustness: diverse selection simulates a scenario where practitioners can actively choose informative support examples, while random selection represents default, arbitrary support sampling.
Results.
Figure 3 shows that: (1) Uniform sampling slightly outperforms kNN-based selection (by 3–5 points), indicating few-shot performance is not highly sensitive to support curation; (2) Orion-Bix consistently exceeds TabICL under both schemes, with relative ordering unchanged, suggesting meta-training improves overall in-context generalization rather than depending on a specific support selection heuristic.
4 Conclusion
In summary, Orion-Bix preserves the core strengths of TabICL while adding a biaxial row encoder and an episodic meta-learning schedule that directly targets few-shot in-context performance.
Read the paper: https://arxiv.org/abs/2512.00181