1. Introduction
Large language models (LLMs) achieve strong performance across many tasks, but raw pre-trained models are often misaligned with downstream objectives helpfulness, safety, domain constraints, or product requirements. Post-training alignment via SFT [21], preference optimization [22], and RLHF [5, 20] is therefore a necessary step for real-world deployment.
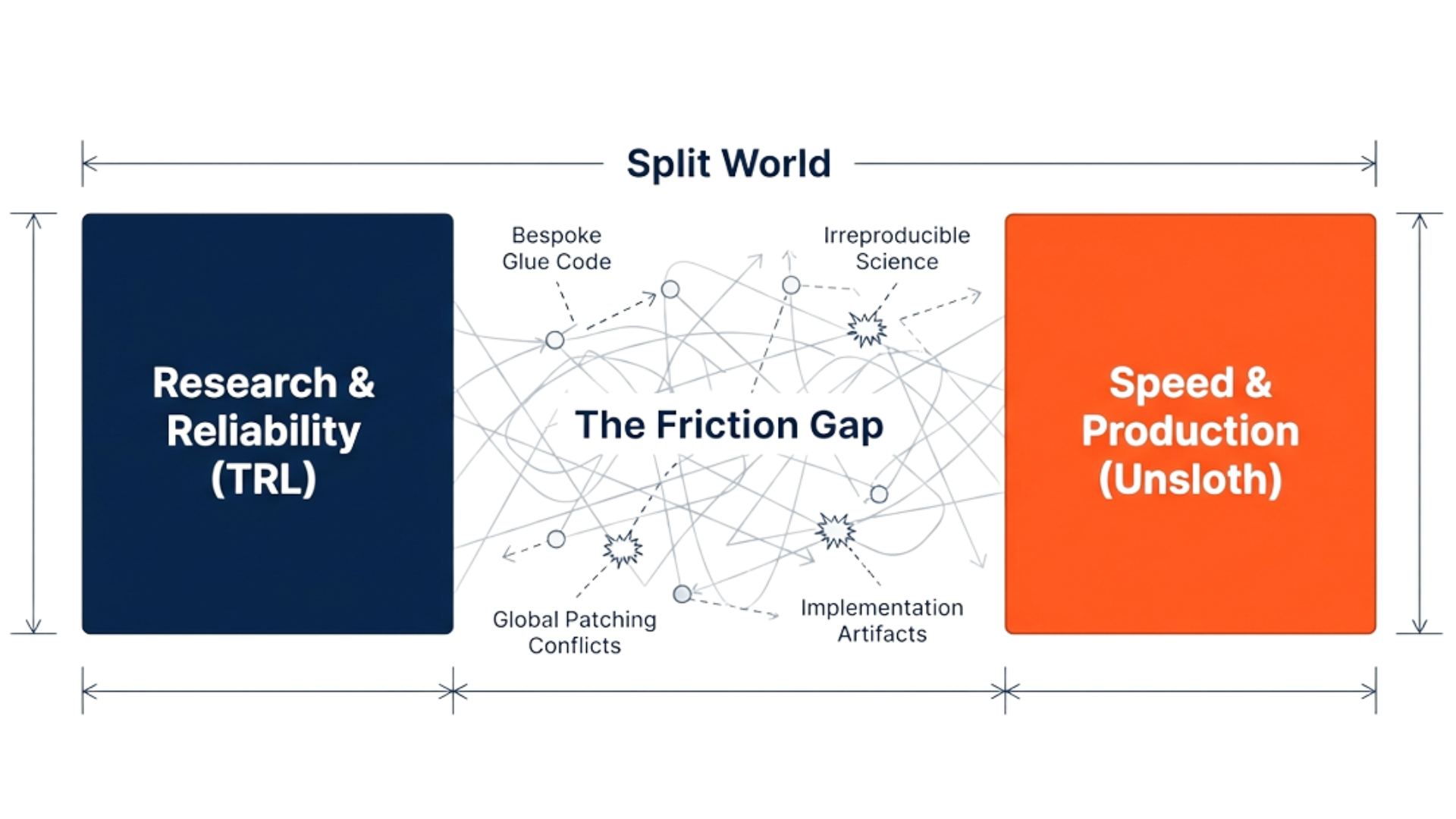
Practitioners today face a fragmented ecosystem. Most codebases target a single algorithm or backend, lack robust error handling, and resist integration into production pipelines. Libraries like TRL [32] provide useful building blocks but expose one backend and a subset of algorithms, leaving users to assemble reward functions, evaluation, and configuration logic themselves. This fragmentation raises engineering overhead and makes it hard to reproduce or fairly compare alignment methods. We argue that backend interference, reward fragmentation, and irreproducible pipelines are first-order obstacles in alignment research. Without standardized infrastructure, it is difficult to distinguish genuine methodological advances from implementation artifacts.
AlignTune unifies supervised fine-tuning and RLHF-style training behind a single interface targeting multiple backends (TRL and Unsloth). A backend factory routes training requests to backend-specific implementations via a common API, while an environment-based isolation mechanism prevents Unsloth from globally patching transformers when TRL is selected. A unified configuration system supports reproducible experiments. AlignTune also provides an extensible reward framework (including domain-oriented reward functions for medical, legal, and financial settings), a reward-model training workflow, evaluation integration for standard benchmarks and custom tasks, and a CLI for end-to-end workflows. Table 1 summarizes supported algorithms; Section 3 gives architectural details.
Contributions. This paper makes the following contributions:
- A modular toolkit, AlignTune, that unifies SFT and RLHF-style training behind a single interface across TRL and Unsloth backends.
- A backend isolation mechanism that prevents Unsloth from patching transformers during pure TRL runs, with experimental validation (Section 5.3).
- Backend benchmarks comparing TRL and Unsloth [30] on throughput, memory, and evaluation metrics, showing backend-agnostic training without code changes (Section 5.1).
- An extensible reward framework with 43 built-in reward functions, domain-specific signals, composable reward APIs, and a reward-model training pipeline (Section 3.6).
- A data management layer supporting Hugging Face Hub, JSON, CSV, Parquet, and directory-based sources.
2. Installation and Getting Started
AlignTune is distributed as a Python package and can be installed from PyPI or from source:
3. Library Structure
3.1 Scope and Definitions
Before describing the architecture, we clarify scope and define key terms. AlignTune is the library presented in this work. A backend is a concrete implementation of the training stack (e.g., TRL-based or Unsloth-accelerated).
The backend factory is the component that selects and instantiates the appropriate backend from user configuration. The reward model pipeline refers to the workflow of deriving training signals from rule-based reward functions, using them to train neural reward models, and then deploying those models within RLHF-style optimization.
Scope : AlignTune supports: (1) SFT for instruction following and related supervised objectives; (2) preference optimization (DPO [22] and variants); (3) policy optimization (PPO [24], GRPO [38], GSPO [37], and extensions); (4) reward function composition and neural reward model training; (5) evaluation via lm-eval and internal harnesses; (6) YAML and Python API configuration; and (7) a CLI for end-to-end workflows.
Non-goals : AlignTune does not claim: (1) novel RLHF algorithms it standardizes existing methods; (2) universal speedups acceleration depends on GPU and kernel compatibility; (3) perfect feature parity between backends (see Table 1); or (4) support for all model families we target transformer-based LLMs compatible with Hugging Face Transformers [33].
3.2 High-Level Architecture
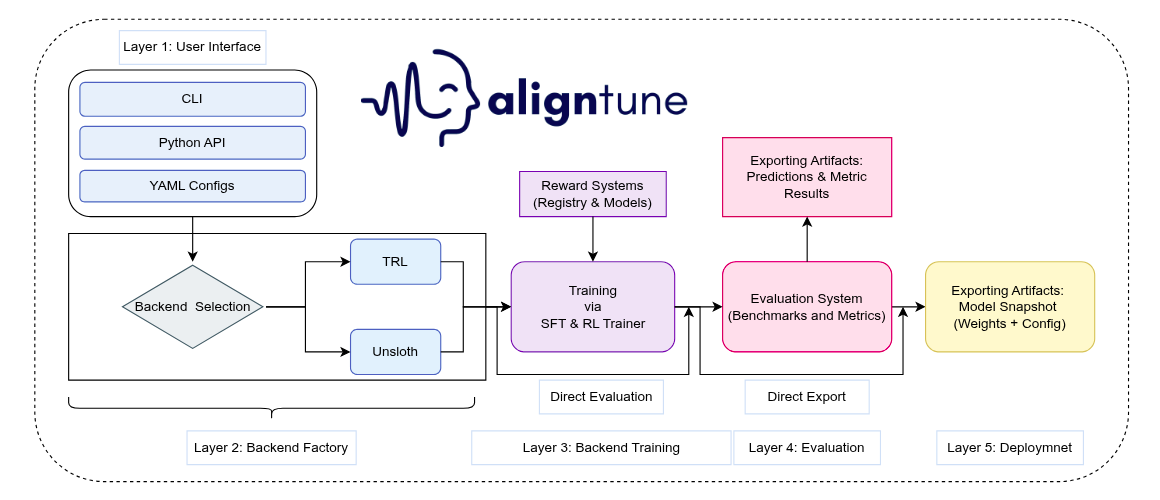
AlignTune organizes the alignment stack into layers: user interfaces (CLI, Python API, YAML configs), a backend factory, backend-specific trainers, and shared reward and evaluation systems. The core package is organized as:
- backends/: backend implementations for TRL and Unsloth, each with sft/ and rl/ submodules.
- core/: shared core functionality, including the backend factory, RL and SFT configuration classes, trainer bases, and registries.
- rewards/: reward function registry, reward-model training utilities, and reward-related types.
- eval/: evaluation framework, including lm-eval [10] integration and custom tasks.
- data/: dataset processor and manager entry points.
- cli/ and cli_commands/: command-line entry points and configuration builders.
- utils/: supporting modules for device management, diagnostics, logging, validation, and model loading.
The design emphasizes modularity (each concern in a dedicated module), extensibility (new backends, algorithms, rewards, and tasks register without modifying core logic), and production readiness (error handling, diagnostics, typed configuration).
3.3 Core API and Class Hierarchy
AlignTune exposes a layered class hierarchy that users interact with at multiple levels of abstraction.
3.3.1 Factory API
The primary entry points are two factory functions in aligntune.core.backend_factory:
- create_sft_trainer(…) creates an SFT trainer for the requested backend and task type.
- create_rl_trainer(…) creates an RL trainer for the requested backend and algorithm.
Both functions accept a uniform set of keyword arguments (model name, dataset, backend, hyperparameters) and return a trainer instance whose .train(), .evaluate(), and .save_model() methods follow a common protocol regardless of backend. Internally, the BackendFactory class dispatches to the correct backend-specific trainer using enums: TrainingType (SFT or RL), BackendType (TRL or Unsloth), and RLAlgorithm (DPO, PPO, GRPO, GSPO, DAPO, Dr. GRPO, GBMPO, Counterfactual GRPO, BOLT, GBMPO). A BackendConfig dataclass stores backend selection, isolation flags, and fallback preferences.
3.3.2 Trainer Class Hierarchy
All trainers derive from one of two abstract base classes:
- TrainerBase (RL): defines the full lifecycle for reinforcement learning style training, including reward integration, rollout generation, policy updates, and checkpoint management. It maintains a TrainingState dataclass that tracks the current step and epoch, the best observed metric, and the active checkpoint path.
- SFTTrainerBase (SFT): defines the lifecycle for supervised fine-tuning, including task-aware data preparation, orchestration of the training loop, and evaluation hooks.
Each backend provides concrete trainer implementations.
TRL backend : TRLSFTTrainer, TRLDPOTrainer, TRLPPOTrainer, TRLGRPOTrainer, TRLGSPOTrainer, TRLDAPOTrainer, TRLDRGRPOTrainer, TRLGBMPOTrainer, TRLCounterFactGRPOTrainer, TRLPACETrainer.
Unsloth backend : mirrors the TRL set using an Unsloth prefix (e.g., UnslothDPOTrainer). GSPO, GBMPO, and Meta-ES are currently TRL-only (see Table 1).
For supervised fine-tuning, an SFTTrainerFactory additionally dispatches requests by TaskType (instruction following, text classification, token classification, text generation, or chat completion). Each task can use specialised data formatting and loss computation (e.g., a ClassificationTrainer for classification objectives).
3.4 Multi-Backend Architecture
AlignTune’s multi-backend architecture lets users choose between:
- TRL: pure TRL implementations optimized for reliability and compatibility.
- Unsloth: accelerated implementations offering speed-ups and memory savings via quantization and optimized kernels.
The backend factory centralizes selection and instantiation. Without it, users must manually configure backend-specific parameters differently for each backend, creating configuration skew that conflates backend effects with setup differences.
The following examples use DialoGPT [39] with Alpaca [26] for SFT and HH-RLHF [1] for DPO:
3.4.1 Backend Isolation System
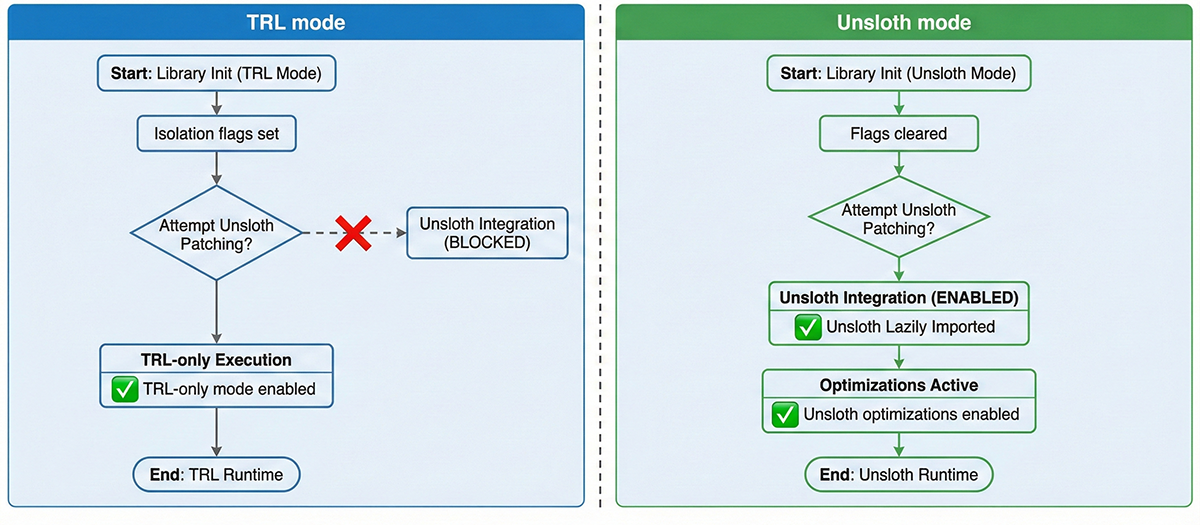
Unsloth patches the transformers stack globally to insert optimized kernels and compression logic (Figure 3). This is desirable when Unsloth [30] is explicitly selected, but can interfere with pure TRL runs in the same environment. Without isolation, identical configs with different import order can produce different training dynamics, invalidating backend comparisons. AlignTune’s isolation system has four components:
- Environment-variable control. When TRL [32] is selected, the factory sets PURE_TRL_MODE, TRL_ONLY_MODE, and DISABLE_UNSLOTH_FOR_TRL to block Unsloth patches. When Unsloth is requested, these flags are cleared and Unsloth is imported lazily.
- Lazy loading. A helper in _imports.py checks Unsloth availability (PyTorch, CUDA versions) but defers the actual import until needed.
- String-based selection. The factory accepts backend names as strings, avoiding enum imports that could trigger Unsloth initialization.
- Automatic fallback. If Unsloth is unavailable or fails compatibility checks, informative errors point users to TRL [32] as a fallback.
3.5 Training Algorithms
AlignTune exposes both supervised and reinforcement-learning-based alignment methods under a unified interface.
Supervised Fine-Tuning (SFT) : SFT covers instruction following, text classification, token classification, and chat-style tasks. The SFT stack supports: (i) task routing configuration-level selection of task type, mapping to the appropriate trainer; (ii) parameter-efficient fine-tuning via LoRA [13] and QLoRA [9], including 4-bit quantization; and (iii) gradient checkpointing, mixed precision (fp16/bf16), and dataset packing. SFT trainers are available for both TRL and Unsloth backends with a common configuration surface.
Reinforcement Learning and RLHF Algorithms : The goal is not to introduce new algorithms, but to show that a single abstraction can host a broad class of alignment methods without backend-specific rewrites.
For each algorithm, AlignTune implements both TRL-based and, where applicable, Unsloth-based trainers that share a common base class. Table 1 summarizes the supported RLHF algorithms and backend coverage. PPO trainers additionally support: (i) reward model integration from the Hugging Face Hub, local checkpoints, or AlignTune’s own reward-model pipeline; (ii) model-family consistency checks (e.g., ensuring compatible policy and reward model families such as Qwen [28], LLaMA [31], Mistral [14]); and (iii) explicit KL penalty control, clipping settings, and multi-task reward configurations.
3.6 Reward System
Table 2: Catalog of built-in reward functions in AlignTune, grouped by category. All reward functions can be combined with configurable weights to form composite rewards. Custom reward functions can be registered via the RewardRegistry API.
3.6.1 Reward Class Hierarchy
The reward subsystem is built on a layered class hierarchy. RewardFunction is the abstract base class; every reward implements a compute(text, **kwargs) -> float method. A RewardType enum (30+ members) categorises each function, and a RewardConfig dataclass stores parameters such as weight, threshold, and normalization mode.
Key infrastructure classes:
- RewardFunctionFactory creates reward function instances from string keys or RewardType values
- CompositeReward combines multiple RewardFunction instances with configurable weights, enabling multi-objective reward signals (e.g., 0.3×length+0.4×sentiment+0.3×safety).
- RewardRegistry central registry that maps string keys to reward types, manages default configurations, and exposes register_custom_reward() and get_reward_function() helpers.
AlignTune ships concrete reward classes implementing the RewardFunction interface, organised into multiple categories (see Table 2). Notable implementations include CodeExecutionReward (sandboxed code execution with test-case validation), MathCorrectnessReward (symbolic and numeric answer grading), (domain-specific scoring), and MBPPReward (code generation benchmark reward).
Without a centralised registry, reward logic scatters across trainer implementations, making it hard to audit which rewards apply in which experiments and leading to inconsistent application across runs.
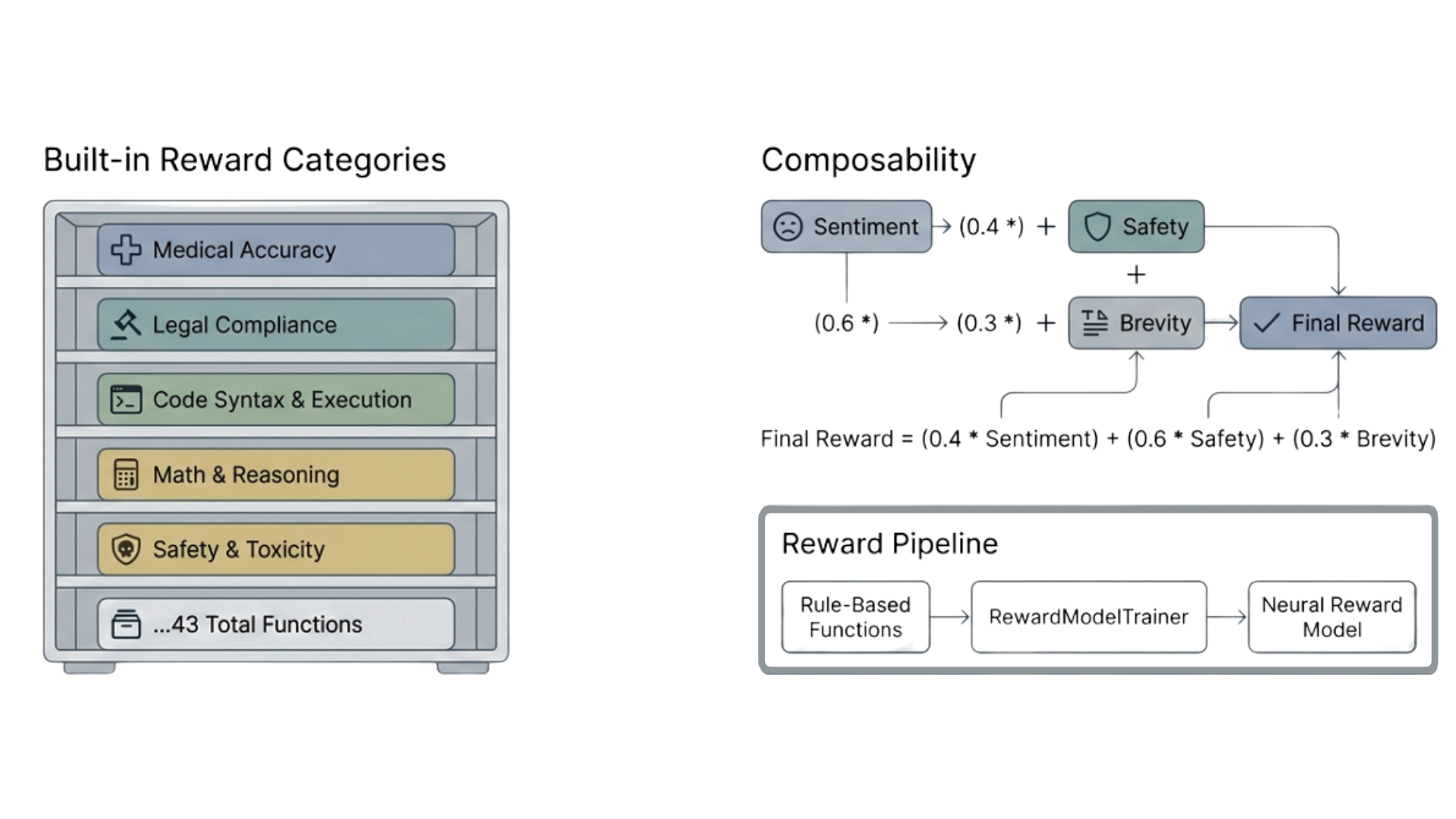
Figure 4:AlignTune reward system: built-in reward categories, weighted composition, and the pipeline from rule-based rewards to neural reward models.
3.6.2 Reward Function Registry
The registry maps string keys to reward types, manages default configurations, and provides helpers to construct composite rewards.
New reward functions can be registered as follows:
3.6.3 Reward-Model Training Pipeline
Beyond rule-based rewards, AlignTune supports training neural [5, 20] reward models from text data labeled by reward functions. The pipeline is implemented by four classes in aligntune.rewards.training:
- RewardModelTrainer orchestrates end-to-end reward model training: generating labeled data from rule-based functions, training a transformer-based reward model, and saving checkpoints.
- RewardModelDataset a PyTorch Dataset that pairs texts with composite reward scores.
- RewardModelValidator evaluates reward model accuracy, calibration, and correlation with ground-truth reward functions.
- RewardModelLoader loads trained reward models for inference, including TRLCompatibleRewardModel for direct integration with TRL PPO trainers.
The typical workflow is:
- Choose a base model architecture for the reward model.
- Define a set of reward functions and associated weights.
- Generate training examples and compute composite rewards.
- Train the reward model via the reward training module.
- Plug the resulting reward model into PPO (or other RL trainers).
By treating rewards as first-class objects, AlignTune also enables controlled experiments over reward structure (e.g., sparse vs. dense, rule-based vs. learned) something difficult when reward logic is coupled to specific trainers. This supports reward ablations, audits, and systematic studies of how reward design affects alignment outcomes.
3.7 Data Management
AlignTune provides a unified data management layer in aligntune.data that abstracts over heterogeneous data sources. The DataManager class coordinates loading, processing, and caching of training and evaluation datasets.
Loaders : A LoaderResolver inspects the data source string and dispatches to the appropriate loader. Several concrete loaders extend the BaseLoader interface:
- HFLoader loads datasets from the Hugging Face Hub via the datasets library, with support for streaming, splits, and column selection.
- JSONLoader, CSVLoader, ParquetLoader load from local files in the corresponding formats.
- DirectoryLoader loads from a local directory of text or structured files, with configurable file-type filtering.
All loaders return a common Dataset object, ensuring that downstream trainers and evaluators are agnostic to the data origin. A DatasetCache accelerates repeated experiments by caching processed datasets.
3.8 Configuration and CLI
Unified Configuration System : AlignTune’s configuration system is centered on strongly-typed dataclasses:
- RLConfig for RL training, with nested sections for algo, model, datasets, train, logging, rewards, and caching.
- SFTConfig for SFT, with analogous model, dataset, train, and logging sections.
Configurations can be authored in YAML, separating code from hyperparameters. Validation logic provides informative errors and estimates memory usage to catch misconfigurations early.
Command-Line Interface and Recipes. The aligntune CLI offers high-level commands:
- aligntune info: environment and backend information
- aligntune train: run SFT or RL training from a config or inline arguments.
- aligntune diagnose: run environment diagnostics
- aligntune recipes: list, show, and copy pre-defined recipes.
Example usage:
Recipes encode best-practice configurations for families such as LLaMA [31] and Qwen [28], handling authentication and model-specific quirks.
3.9 Evaluation System
The evaluation subsystem integrates both standardised benchmarks and custom tasks through a class hierarchy rooted in aligntune.eval.
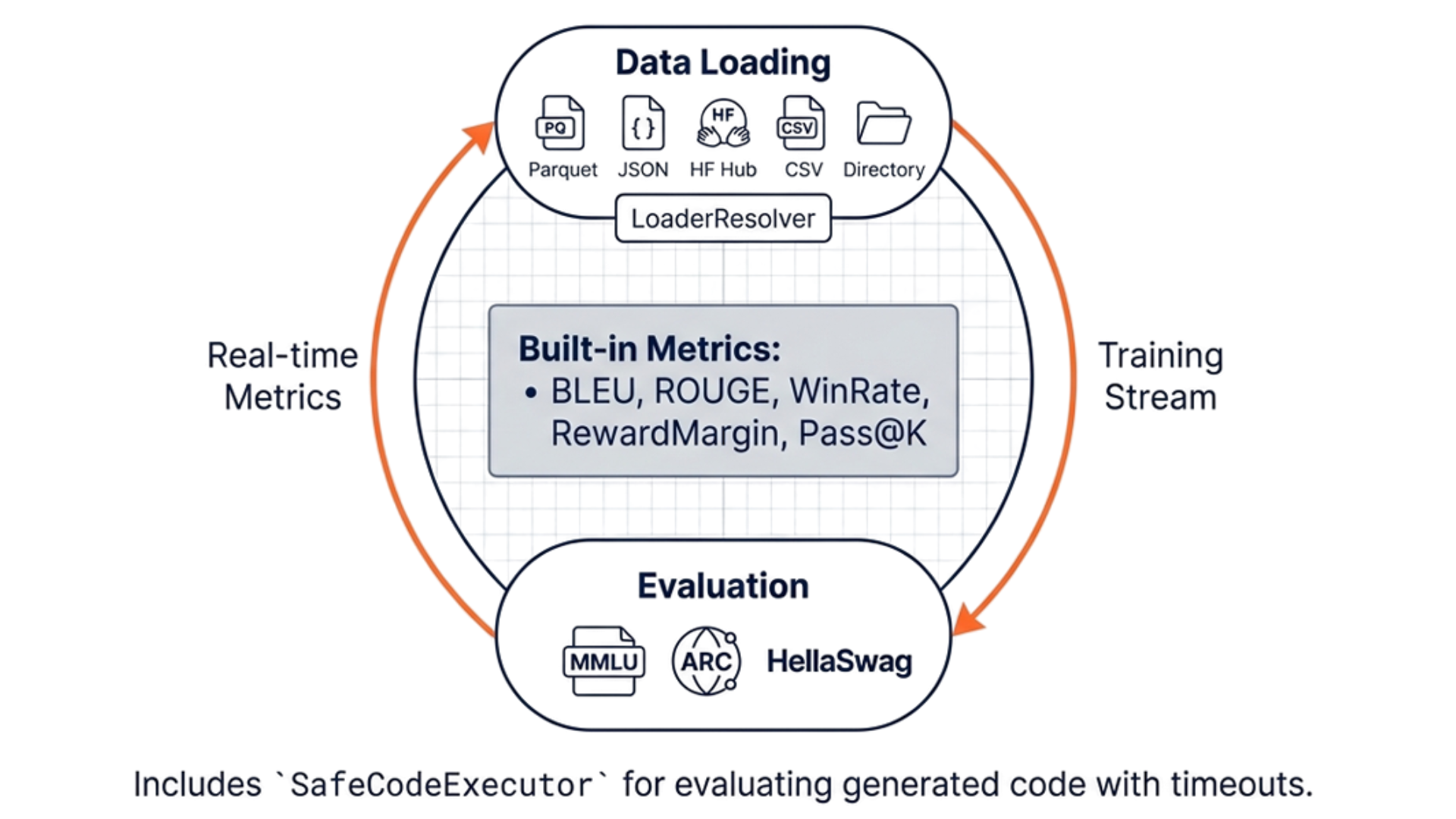
3.9.1 Evaluation Infrastructur
- BaseEvaluator and RLEvaluator abstract base and RL-specific evaluators that orchestrate metric computation over model outputs.
- EvalConfig typed configuration specifying tasks, metrics, sample sizes, and logging options.
- EvalTask and EvalResult represent individual evaluation tasks and their results.
- EvalRunner orchestrates multi-task evaluation runs, dispatching to registered metrics.
- EvalRegistry registry of evaluation functions and tasks, enabling extensibility.
- SafeCodeExecutor sandboxed code execution environment with timeout (TimeoutException) for evaluating generated code safely.
3.9.2 In-Built Metrics
AlignTune provides multiple metric implementations extending an abstract Metric base class: Text metrics: RougeMetric, BleuMetric. Generic metrics: PerplexityMetric, AccuracyMetric. RL-specific metrics: KLDivergenceMetric (policy divergence from reference), RewardAccuracyMetric, PolicyEntropyMetric. DPO-specific metrics: WinRateMetric, RewardMarginMetric, PreferenceAccuracyMetric, LogRatioMetric, ImplicitRewardMetric, CalibrationMetric. Specialised metrics: PassAtKMetric (code generation pass@k), MathAccuracyMetric.
3.9.3 Benchmark Integration
LMEvalRunner and LMEvalConfig wrap the lm-eval-harness [10] for standardised benchmarks such as HellaSwag [36], ARC [6], and MMLU [12]. Custom evaluation tasks for text generation, classification, summarisation, code, and math can be registered via the EvalRegistry. Real-time monitoring: A SampleLogger periodically generates qualitative outputs (e.g., at 50% of training steps) to monitor regressions. Training and evaluation flows follow a simple pattern: models are loaded, evaluation datasets are prepared, inference is run, and metrics are computed and logged.
3.9.4 Evaluation Usage Examples
AlignTune’s evaluation system supports diverse workflows. Here we demonstrate standalone evaluation and integrated training and evaluation pipelines.
Math Task Evaluation : For mathematical reasoning tasks, we can evaluate a trained model on GSM8K [7]:
Text Generation Evaluation. For instruction-following or dialogue tasks, we evaluate on standard text metrics:
3.10 Utilities and Production Features
AlignTune ships a comprehensive utility layer in aligntune.utils designed for production-grade training workflows.
Model and device management : ModelLoader handles quantisation (4-bit/8-bit via bitsandbytes [8]), LoRA [13] adapter injection via PEFT [18], and automatic dtype selection. DeviceManager manages GPU/CPU allocation via Accelerate [11]. CheckpointManager saves and resumes full training state.
Error hierarchy: A structured hierarchy provides actionable diagnostics: AlignTuneError → ConfigurationError, TrainingError, EnvironmentError, ValidationError. Each error carries context and suggested fixes.
Health monitoring : HealthMonitor tracks loss spikes, gradient norms, and memory pressure. TrainingDiagnostics and TrainingMonitor provide real-time metric dashboards. DiagnosticsCollector aggregates GPU utilisation, memory, and disk statistics.
Configuration validation : ConfigValidator checks typed configs against schemas, validates required fields, estimates peak GPU memory, and warns about misconfigurations before training starts.
4. Illustrative Examples
A typical example follows this pattern:
AlignTune also supports end-to-end training and evaluation pipelines for supervised fine-tuning:
5. Case Studies
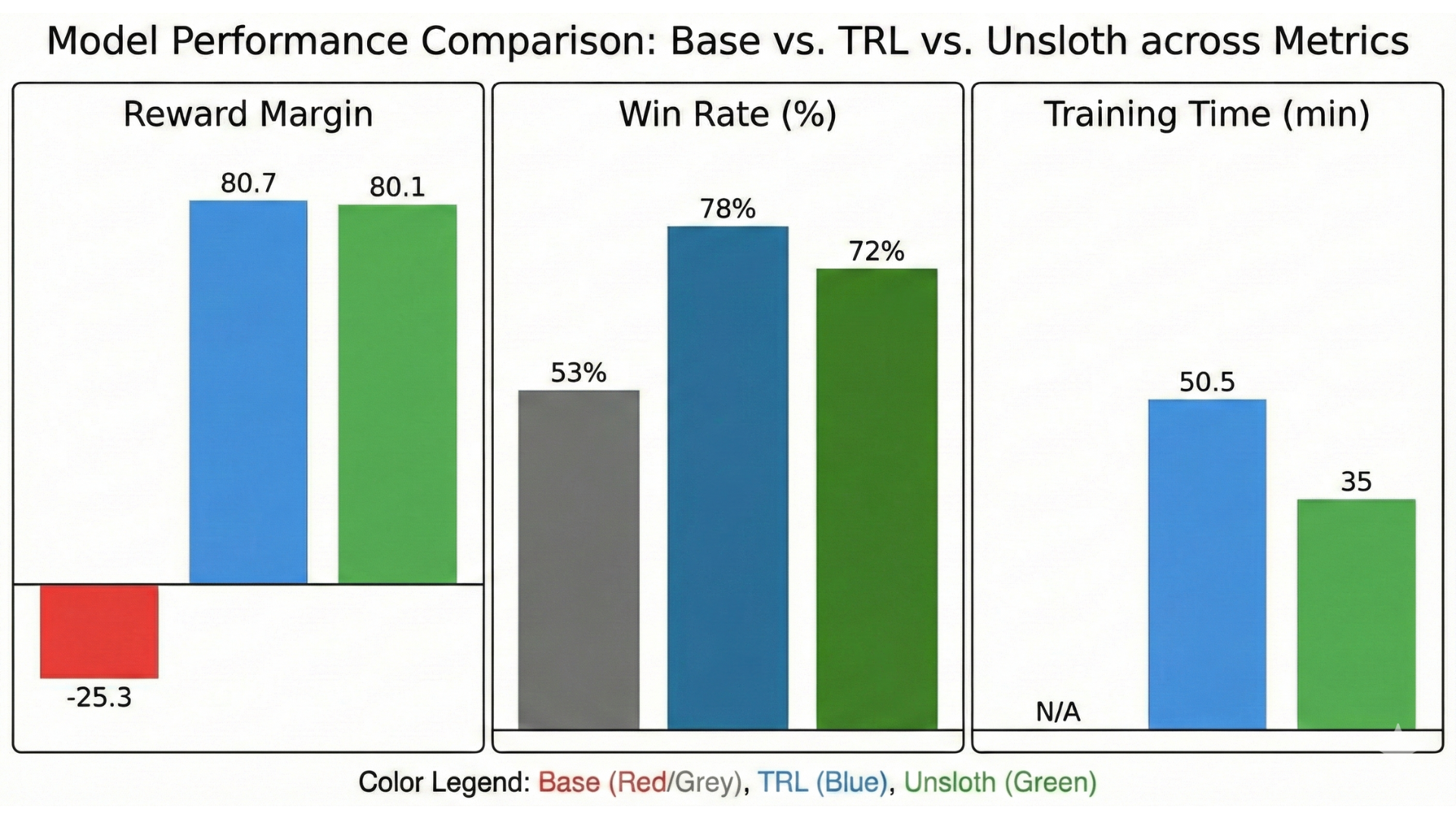
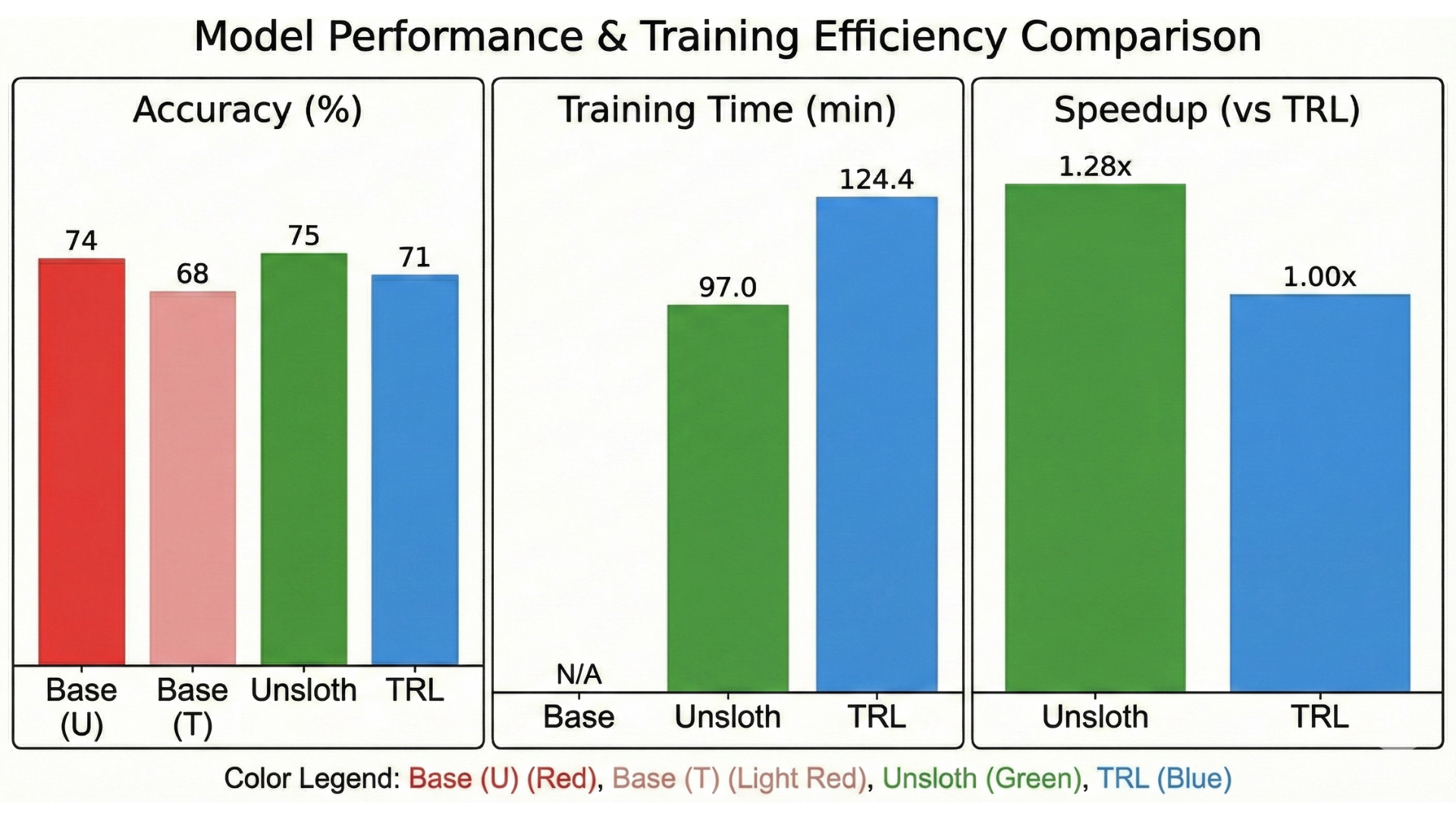
This section presents experimental evidence for AlignTune’s core claims. We provide benchmark results comparing TRL and Unsloth [30] backends, demonstrate backend isolation, and outline reproducibility artifacts. All experiments use the same model, dataset, and objective across backends to enable fair comparison.
5.1 Backend Comparison Benchmark
To validate that AlignTune enables controlled backend comparisons, we run identical training configurations on both TRL and Unsloth [30] backends and measure throughput, peak memory usage, and final evaluation metrics.
5.1.1 Experimental Setup
To validate our library’s performance and cross-backend consistency, we conduct two primary alignment experiments: Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO).
DPO Benchmark: We compare the TRL and Unsloth backends by fine-tuning a phi-2 model on preference pairs. This setup is designed to measure whether backend-specific optimizations (like Unsloth’s kernel patching) impact the final model alignment or if they remain mathematically equivalent to the TRL baseline.
GRPO Benchmark: We evaluate our unified GRPO implementation using a Llama-3.2-3B model on the GSM8K mathematical reasoning dataset. This configuration tests the library’s ability to handle complex reward functions and reinforcement learning loops across different scales.
Full hyperparameter configurations, dataset and hardware specifications for both setups are detailed in Appendix A.
5.1.2 Results
Discussion. Three findings emerge: (1) Unsloth delivers faster throughput and lower memory on compatible hardware; (2) final evaluation metrics are similar across backends, confirming that backend choice does not compromise quality; and (3) the unified interface enables these comparisons without code changes. Each configuration specifies model, dataset, hyperparameters, and training duration for exact reproducibility.
5.2 Effect of Backend Choice on Alignment Outcome Variance
A key question is whether backend selection introduces variance that could confound algorithm comparisons. Our experiments show that final evaluation metrics (reward margins, preference accuracy) are comparable between TRL and Unsloth when configurations are identical (Figures 7 and 8). Backend selection can therefore be based on computational efficiency without introducing confounding variance, letting researchers attribute performance differences to algorithms rather than implementation artifacts.
5.3 Backend Isolation Test
We run paired experiments differing only in backend selection and isolation flags. In TRL-only runs, isolation mode prevents Unsloth from being imported; throughput, memory, and metrics match a baseline TRL environment without Unsloth installed. In Unsloth-enabled runs, isolation flags are cleared and Unsloth patches the transformers stack, yielding the expected speed and memory gains with comparable final metrics. These pairs confirm that both backends coexist in a single environment without cross-backend interference.
6 . Illustrative Use Case
To validate the efficacy and versatility of our alignment pipeline, we applied it to two distinct financial domains representing contrasting enterprise requirements. First, we developed a Specialized Wealth Management Assistant, designed for high-value, advisory-centric interactions that demand professional nuance and complex reasoning. Second, we engineered a Retail Banking Support Agent, targeting high-volume, transactional workflows where strict procedural adherence and precision are paramount. In this section, we detail the dataset curation, training methodologies, and comparative analysis against state-of-the-art closed-source models for both use cases.
6.1 Specialized Wealth Management Assistant
6.1.1 Task and Dataset Curation
We utilized the Bitext Wealth Management LLM Chatbot Training Dataset [3], a specialized corpus designed to train agents capable of handling complex financial queries. To ensure a robust evaluation, we curated the dataset using a class-balanced splitting strategy
- SFT Split: We constructed a balanced training set ensuring equal representation of complex intents (e.g., portfolio performance inquiry, investment strategy change, advisor scheduling) to prevent the class imbalance biases often found in raw financial logs.
- Preference Dataset: To facilitate Direct Preference Optimization (DPO), we isolated a subset of 2,000 samples from the training data. For each user query, we generated pairs of responses from our sft trained policy model, (chosen vs. rejected) to explicitly model the nuance, professional empathy, and compliance-aware tone required in wealth management interactions. GPT-5 LLM as a Judge was used for this task.
- Evaluation Split: A separate, unseen test set was reserved to benchmark performance.
6.1.2 Experimental Setup
We evaluated the performance of Qwen3-4B-Instruct-2507 [29] across three stages of evolution:
- Base: The pretrained checkpoint without specific financial domain adaptation
- SFT: The model fine-tuned on the wealth management instructions.
- DPO: The SFT model further aligned using the domain-specific preference pairs.
These were compared against two leading closed-source models: GPT-4o [19] and GPT-5 [25]. To ensure a fair and rigorous comparison, the closed-source models were evaluated in both 0-shot and 2-shot settings. The full experimental configurations and the prompt details are added to the Appendix B
6.1.3 Comparative Analysis
Table 3 presents the comprehensive evaluation results. We employed a suite of metrics including BLEU, ROUGE (1/2/L), ChrF, and BERTScore to capture both the lexical precision and semantic validity of the financial advice.
Domain Adaptation and Alignment.
The Base Model (0-shot) failed to generate coherent advice (BLEU 0.0286), underscoring the necessity of domain adaptation in such sensitive domains. Supervised Fine-Tuning (SFT) raised BLEU to 0.2690 and BERTScore to 0.9134. This indicates that the model has successfully learned the specific lexicon and structural requirements of the wealth management domain. Direct Preference Optimization (DPO) further refined semantic alignment; while lexical metrics remained stable, DPO achieved the highest BERTScore (0.9142), indicating superior adherence to the professional tone and accuracy required in wealth management.
Comparison with Closed-Source Models.
The closed-source models show competent but inferior performance compared to the fine-tuned specialist. GPT-4o (0-shot) achieves a BLEU of 0.0850, and even the more advanced GPT-5 (2-shot) only reaches 0.1218. Our DPO Model outperforms the strongest closed-source baseline (GPT-5 2-shot) by a significant margin across all metrics (e.g., 0.2692 vs. 0.1218 in BLEU). This validates the hypothesis that a small, domain-specialized model can significantly outperform larger, generalist models in high-compliance verticals like wealth management and is another step forward towards more accessible AI for the general public.
Evaluation Protocol.
We evaluated SFT and DPO models exclusively in a 0-shot setting, unlike the baselines which utilized 2-shot prompting. Since our models underwent instruction fine-tuning, the task format is parameterized into the weights. Introducing few-shot examples at inference creates distribution shift ("prompt noise") rather than useful context, degrading performance. Thus, 0-shot represents the optimal evaluation regime for the fine-tuned variants.
6.2 Domain Specific Banking Assistant
We further tested the pipeline on a high-volume, transactional domain to contrast with the advisory nature of wealth management. While the previous use case required the nuance of preference optimization, this task prioritizes strict adherence to standard banking protocols (e.g., account verification, transfer limits), making it an ideal test bed for the precision of Supervised Fine-Tuning (SFT).
6.2.1 Task and Dataset Curation
We utilized the Bitext Retail Banking LLM Chatbot Splits, employing the same class-balanced splitting strategy detailed in Section 4.3.1. We focused our evaluation on comparing the 4B parameter SFT model against the best-performing baseline from the previous experiment, GPT-5 (2-shot), to test if generalist frontier models could adapt to rigid transactional formats via in-context learning.
6.2.2 Comparative Analysis
Table 4 presents the results. Unlike the wealth management task, where the gap was significant but competitive, here we observe a fundamental divergence in model capability.
SFT Precision vs. Generalist Collapse.
The SFT Model (0-shot) achieved a BLEU score of 0.2685 and a BERTScore of 0.9146, effectively mastering the specific output templates required for banking transactions. In stark contrast, GPT-5 (2-shot) suffered a catastrophic drop in performance (BLEU 0.0137, ROUGE-L 0.1869). This anomaly highlights a known vulnerability in massive generalist models: despite their reasoning capabilities, they struggle to suppress conversational "chattiness" in favor of the concise, rigid formatting required for automated banking, resulting in near-zero lexical overlap with the ground truth.
Verification of Evaluation Protocol.
Consistent with the wealth management findings, the SFT model performed optimally in the 0-shot setting (BLEU 0.2685) compared to the 2-shot setting (BLEU 0.2549). This reinforces our broader conclusion that for rigorously fine-tuned specialist models, few-shot prompting acts as distribution noise rather than helpful context.
7. Discussion and Related Work
7.1 Related Work
Why not TRL [32] plus custom scripts? TRL provides strong building blocks, but using it directly forces users to (1) commit to a single backend, making controlled comparisons difficult; (2) manually manage environment variables and import order to prevent Unsloth interference; (3) implement reward composition, reward model training, and evaluation from scratch; and (4) write boilerplate for configuration and reproducibility. AlignTune addresses these gaps with a unified abstraction that automates backend selection and isolation, integrates reward and evaluation pipelines, and standardizes configuration.
TRL is widely adopted for RLHF algorithms (PPO [24], DPO [22], GRPO [38]) on top of Hugging Face Transformers [33]. AlignTune builds on TRL [32] while adding backend abstraction, isolation, unified configuration, and integrated reward and evaluation pipelines. Unsloth [30] provides speed and memory improvements via kernel optimizations and quantization. AlignTune integrates Unsloth as an alternative backend, isolating its effects through environment controls and lazy loading so users can leverage its benefits without compromising clean TRL baselines. Other RLHF stacks trlx [4], RL4LM [23], OpenRLHF [27] tend to focus on specific algorithms or research setups. AlignTune differs by offering multi-backend abstraction, first-class reward modeling, production-grade diagnostics, and broad algorithm coverage under one interface.
7.2 Design Decisions
AlignTune’s architecture reflects four design principles:
- Backend purity over implicit speedups. Isolation ensures backend selection is explicit and free of hidden side effects. Supporting both TRL and Unsloth lets users trade off reliability and speed without switching toolchains.
- Reward logic as a first-class object. Treating rewards as composable, auditable entities rather than embedded trainer logic enables systematic reward studies, ablations, and complex alignment objectives.
- Configuration as an experimental artifact. Typed configuration classes make hyperparameters version-controlled, validated, and reproducible.
- Isolation before optimization. Backend isolation is enforced before performance optimizations, ensuring speed gains do not compromise experimental validity.
8. Conclusion
We presented AlignTune, a modular toolkit for post-training alignment of LLMs. Its core contributions are: (1) a unified interface over TRL and Unsloth backends enabling controlled comparisons without code changes; (2) a backend isolation mechanism preventing cross-backend interference (Section 5.3); and (3) benchmarks showing backend selection does not compromise training quality (Section 5.1). AlignTune also integrates multiple reward functions, reward model training, and evaluation under a unified configuration and CLI layer.
The library is open-sourced at https://github.com/Lexsi-Labs/aligntune .
Documentation for the library available at https://aligntune.lexsi.ai/ .
9. Future Work
Future work spans two tracks. On infrastructure, we plan stronger CI/CD with GPU runners, modular code reorganization, standardized speed/memory profiling, improved dataset caching, and better documentation. On capabilities, we aim to support safety-aware fine-tuning, mechanistic-interpretability-informed fine-tuning, and agentic fine-tuning for tool use and long-horizon behavior.
10. Ethical Concerns
Alignment toolkits can make models safer, but custom reward functions also risk encoding biases, optimizing harmful behaviors, or favoring deceptive strategies. Practitioners should audit reward functions, incorporate fairness and safety checks into reward modeling and evaluation, and adopt conservative deployment practices. Transparency around reward design, datasets, and evaluation criteria is essential, as is respecting data privacy in sensitive domains (healthcare, finance, legal).