TL;DR: Most GRPO-style post-training methods default to KL divergence as the “stay-close-to-the-base-model” regularizer, but that choice quietly controls the geometry of policy updates and can be a bottleneck. GBMPO swaps KL for flexible Bregman divergences, letting you pick (or learn) the right update geometry per task. A simple ProbL2 regularizer boosts GSM8K from 81.2% → 86.7% (+5.5) with better stability, while Neural Mirror Maps shine on code, matching or improving MBPP while producing 24–36% shorter outputs and reducing training variance (up to ~70% with ES). Bottom line: geometry is a new, practical knob for better accuracy, stability, and token efficiency in LLM post-training.
Policy optimization has become the post-training workhorse for making LLMs better at reasoning after pretraining. GRPO and its variants (Dr. GRPO, GSPO, off-policy GRPO, GTPO, etc.) have improved accuracy, tamed instability, and generally made RL-style post-training much more “production-shaped”.
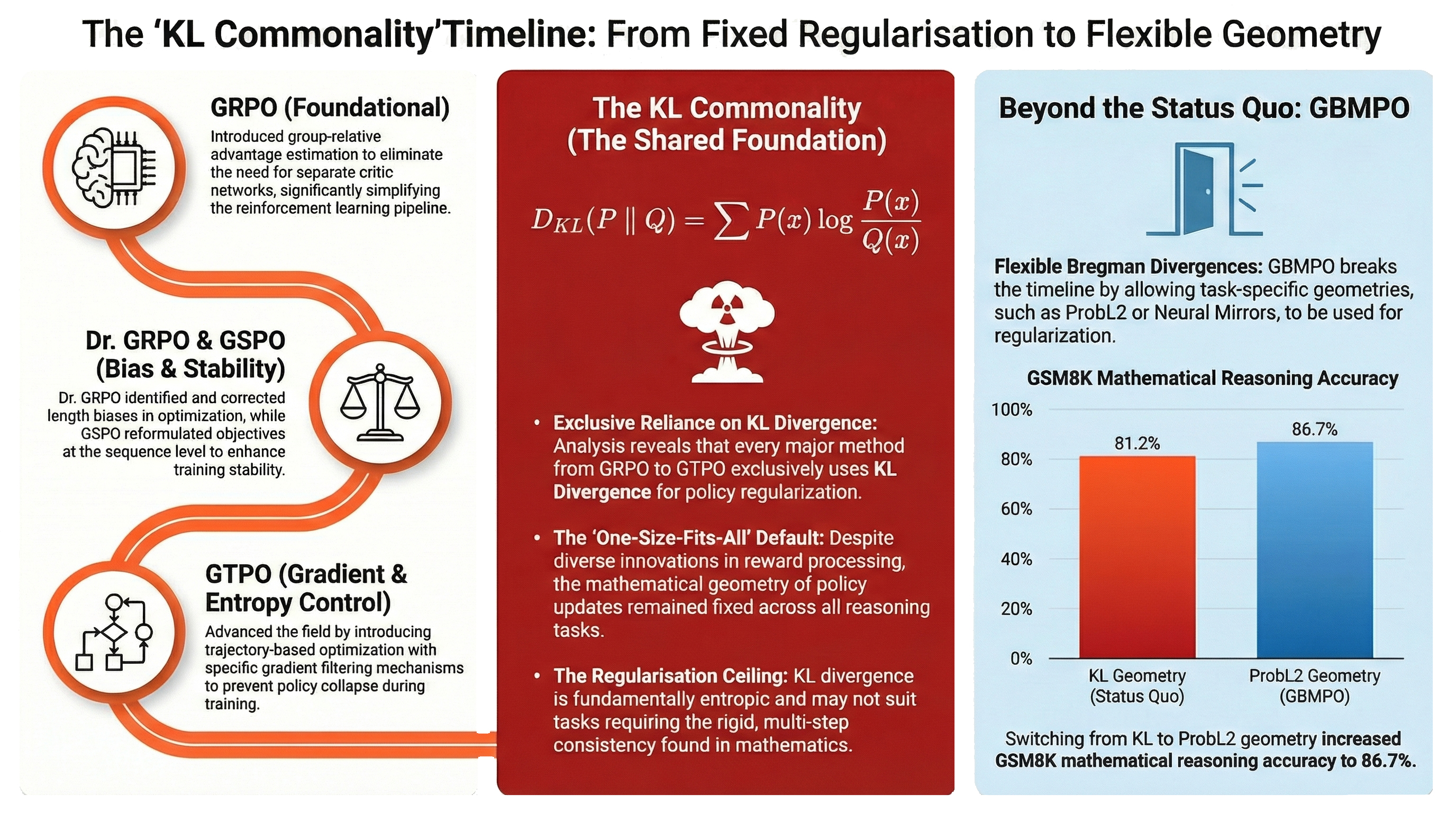
However, across this landscape of algorithmic progress, one fundamental choice has remained largely unchallenged: the use of the Kullback-Leibler (KL) divergence for regularization. Whether you are using Dr. GRPO, GSPO, or G2RPO-A, the model is almost always regularized by its KL distance from a reference policy.
But what if KL divergence isn't actually optimal? What if it's just the mathematical default? Our research introduces Group-Based Mirror Policy Optimization (GBMPO), a framework that establishes divergence choice as a critical, previously unexplored design dimension.
The Geometry Problem: Why Question the Default?
While KL divergence is mathematically convenient, it is not necessarily the best fit for every reasoning task. The choice of divergence function shapes the geometry of policy updates, which in turn influences three critical factors: solution quality, training stability, and generation characteristics.
In the current GRPO landscape, innovations have focused almost entirely on reward processing. By ignoring the regularization geometry, we may be leaving significant performance and efficiency on the table. Different tasks benefit from different optimization geometries. What works for open-ended dialogue may not be optimal for the rigid logic required in mathematical reasoning or code generation.
The Method: Flexible Bregman Divergences
GBMPO generalizes policy optimization by replacing KL with Bregman divergences, derived from a potential function ϕ. Different ϕ induce different mirror maps that define the optimization geometry. KL and L2 are simply special cases: KL corresponds to the entropy function ϕ(p) = Σ pᵢ log pᵢ, while L2 corresponds to the squared norm ϕ(p) = ½‖p‖². By changing ϕ, we can create entirely different optimization geometries.
GBMPO is a general framework: it applies to any group-based policy optimization algorithm, not just GRPO. For instance, the same flexible divergence mechanism can be incorporated into GSPO, immediately enabling sequence-level policy optimization with alternative Bregman regularizers.
We explore two main avenues:
- Hand-Designed Divergences (ProbL2): We use the L2 distance in probability space. This is a simple, interpretable, and theoretically grounded alternative that works exceptionally well for mathematical reasoning.
- Neural Mirror Maps: For tasks where the optimal geometry isn't obvious, we let the model learn it. We parameterize the mirror map using a 126-neuron network with six diverse activation types (cubic, quadratic, square root, cube root, logarithm, exponential) that can discover task-specific geometries. Two variants exist:
- NM-GRPO (random initialization): single training run, captures most of the benefit.
- NM-GRPO-ES (meta-learned via evolutionary strategies): discovers optimal initializations with further stability and efficiency gains.
Experimental Results
We tested GBMPO variants on Qwen3-1.7B across mathematical reasoning (GSM8K) and code generation (MBPP), applying our framework to Dr. GRPO baseline.
Takeaway #1: Optimizing Reasoning in Math and Code
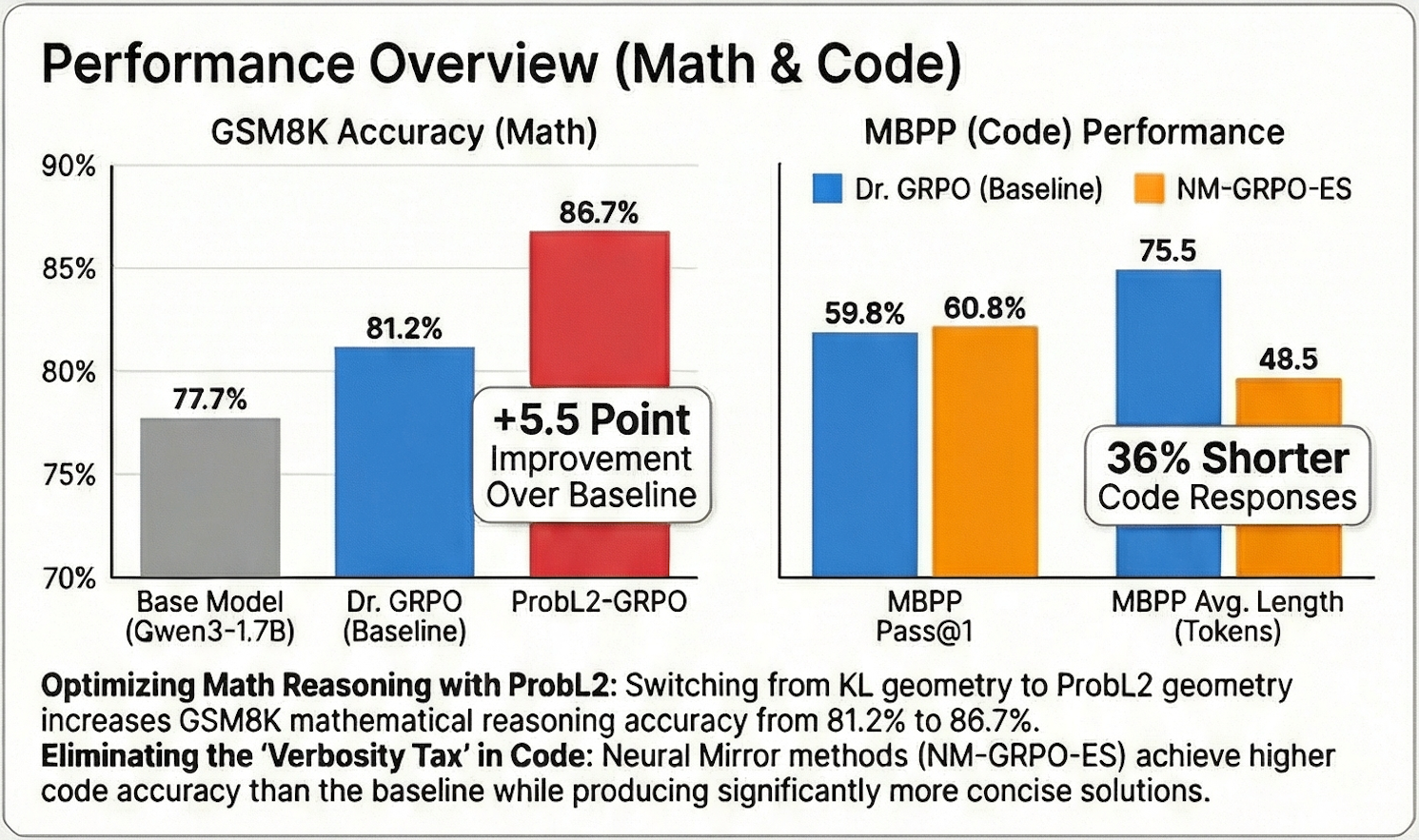
Mathematical Reasoning (GSM8K): The simple ProbL2-GRPO variant achieved 86.7% accuracy, a +5.5 point improvement over the Dr. GRPO baseline (81.2%). This suggests that L2 geometry is better suited for numerical reasoning than the standard KL default, a significant gain from a simple, one-line change to the divergence function.
Code Generation (MBPP): Neural mirror methods excelled here, reaching 60.1–60.8% pass@1. Crucially, they achieved this with 24–36% shorter responses than Dr. GRPO. GBMPO doesn't just improve accuracy; it reduces the verbosity often seen in RL-trained models, making outputs more concise and deployment-ready.
Takeaway #2: Stability is the 'Quiet Revolution' in Training
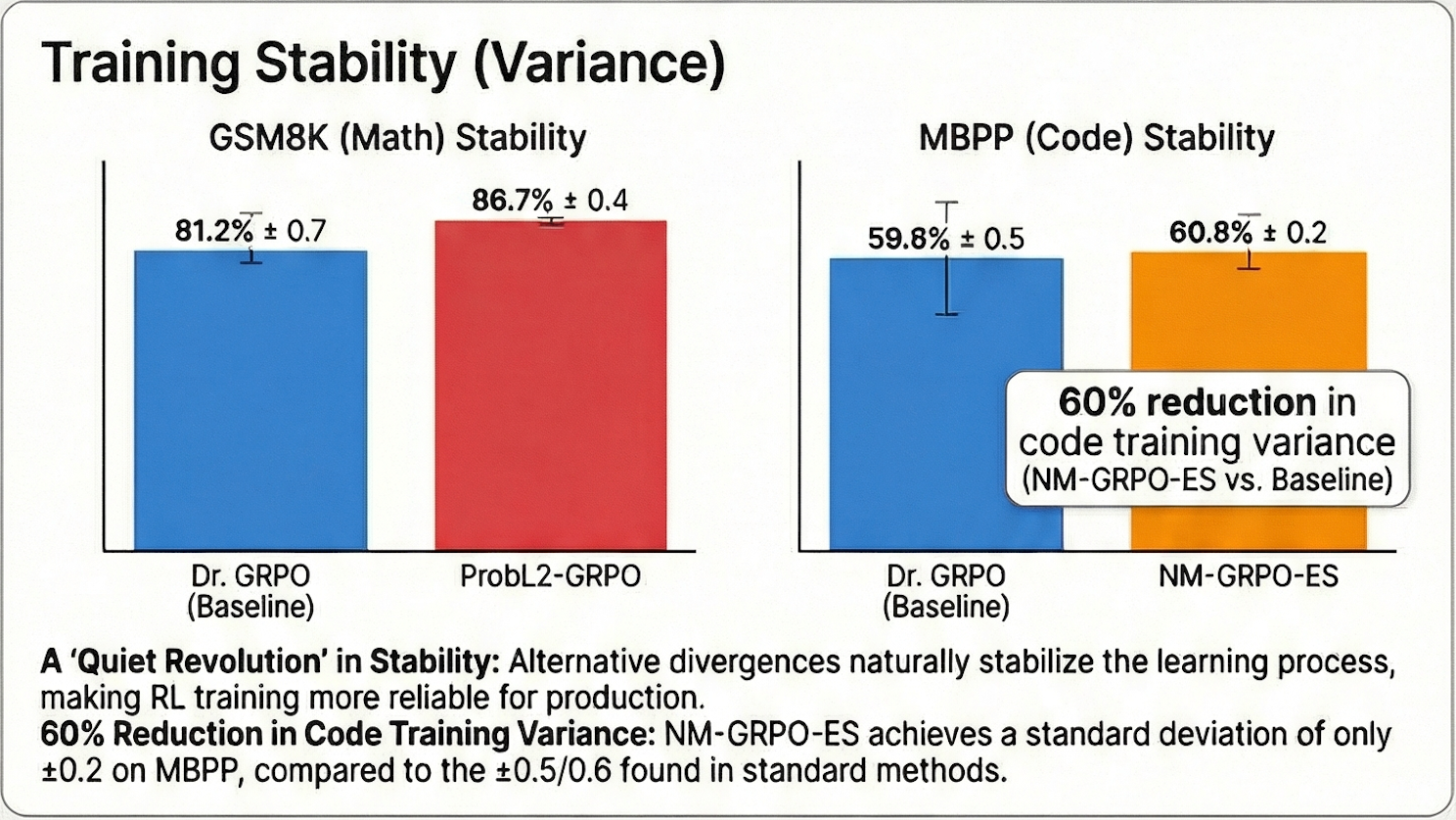
One of the most overlooked aspects of RL training is variance. A method that works once but fails the next three times is difficult to put into production. Bregman regularization significantly stabilizes training:
- ProbL2-GRPO reduced variance on GSM8K from ±0.7 to ±0.4 compared to Dr. GRPO.
- NM-GRPO-ES achieved a 60% reduction in variance on MBPP compared to the Dr. GRPO baseline (±0.2 vs. ±0.5), with further improvement over random initialization (±0.6).
This stability improvement, combined with the accuracy gains, makes GBMPO variants particularly attractive for production deployments where consistency matters.
Takeaway #3: Zero-Shot Transfer — Does It Generalize?
To test whether the model learned robust reasoning rather than task-specific patterns, we evaluated zero-shot transfer from MBPP to HumanEval, a set of 164 hand-written programming problems the model never saw during training.

GRPO-based GBMPO variants transferred effectively: Dr. GRPO and ProbL2-GRPO both reached 62.1% pass@1 on HumanEval (+8.6 points over the base model's 53.5%), while NM-GRPO-ES achieved 60.7% with ~30% fewer tokens than Dr. GRPO. The efficiency gains from neural mirror maps transfer alongside the accuracy, confirming that the learned divergence geometry captures something general about code structure.
Scaling with Evolutionary Strategies
For users with parallel compute, GBMPO offers a further upgrade through evolutionary strategies (ES) meta-learning. ES searches over neural mirror map initializations by running a population of N training runs and evaluating their performance on a validation set.
The key insight for scaling: ES is trivially parallelizable. Each of the N training runs is fully independent and can be executed simultaneously. With N GPUs, the wall-clock time for meta-learning equals a single training run. This makes GBMPO particularly relevant for large-scale post-training pipelines where parallel compute is available.
For those with limited parallel compute, random initialization (NM-GRPO) remains a highly effective alternative, capturing nearly all the accuracy gains with only a single training run. The primary added value of ES is variance reduction and efficiency, not accuracy.
Conclusion: Geometry as a Design Dimension
The key takeaway from GBMPO is that KL divergence is not universally optimal. By treating the divergence function as a critical design dimension, we unlock significant gains in accuracy, stability, and token efficiency:
- Geometry Matters: Simple L2-based divergences can outperform KL by over 5 points in math with no additional complexity.
- Neural Mirrors Automate Discovery: Learned geometries excel at code generation and improve response efficiency by up to 36%.
- Stability is a Core Benefit: Alternative divergences naturally reduce training variance by up to 70%, making RL training more reliable.
- Task Structure is Actionable: Math thrives with ProbL2, code with neural mirrors. Knowing your task type lets you choose the right divergence upfront without any meta-learning overhead.
- It Scales: With parallel compute, ES meta-learning discovers optimal geometries at the cost of a single training run in wall-clock time.
As we scale to larger models and more complex reasoning tasks, challenging the "KL-only" default will be essential for building the next generation of efficient, reliable AI.
Better reasoning doesn't always require more complex algorithms — sometimes it just requires the right geometry.