TL;DR: Enterprises pay a “generalist tax” when they use massive models for narrow, regulated workflows. On a benchmark-scoped wealth-management dataset, a compact 4B open model aligned with SFT + DPO outperformed GPT-4o and GPT-5 (2-shot) on BLEU/ROUGE/ChrF and BERTScore (e.g., the specialist reaches ~0.269 BLEU and 0.914 BERTScore vs GPT-5’s 0.122 BLEU and 0.876 BERTScore in this setup). SFT injects domain knowledge; DPO refines tone, compliance, and preference alignment. All training + evaluation runs were executed end-to-end using AlignTune, making the pipeline reproducible and production-oriented.
Every time an enterprise deploys a massive generalist model for a specialized task, they pay a "Generalization Tax." They pay for knowledge about medieval poetry and Python coding when all they need is accurate, compliant financial advice.
Key finding (benchmark-scoped): We demonstrate that a compact a 4B open model aligned with SFT + DPO achieves higher BLEU/ROUGE/chrF and BERTScore than GPT-4o and GPT-5 under the same evaluation protocol (with 2-shot prompting for the generalist baselines) on the Wealth Management benchmark dataset.
Implementation: All training and evaluation runs were executed using AlignTune.
1. The Problem: The "Generalist Tax" in Fintech
When enterprises use large general-purpose models for narrow regulated workflows, they often incur avoidable overhead : latency/cost, governance constraints, and inconsistent domain behavior despite only needing a small slice of capability.
The Forced Tradeoff: Teams face an unnecessary choice: the high intelligence of massive closed models or the privacy/control of weak open-source models.
Result: Specializing a compact model via curated data + preference alignment can materially reduce the usual trade-offs between capability, cost/latency, and control while maintaining strong task performance in this domain setting.
2. Introducing AlignTune
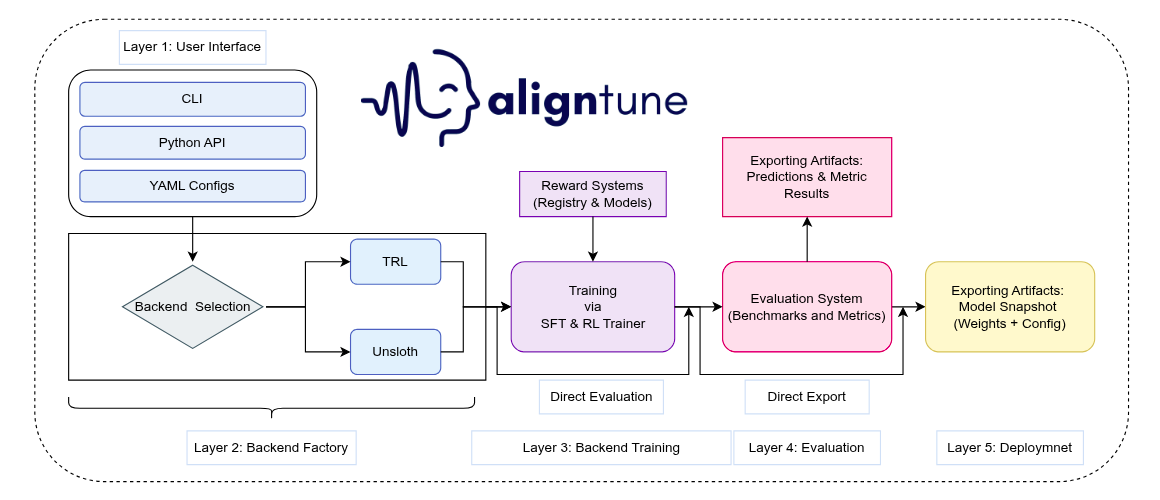
AlignTune is a modular toolkit for post-training alignment of large language models, developed by Lexsi.ai. It provides a unified interface for Supervised Fine-Tuning (SFT) and RLHF-style optimization, with interchangeable TRL and Unsloth backends behind a single factory boundary. This standardizes configuration and training workflows, supports extensible reward and evaluation components, and enables controlled, reproducible alignment experiments.
All models and results reported in this work were produced using AlignTune (Lexsi.ai):
- SFT was used to adapt the base model to the target domain’s instruction format and response style.
- DPO was used to further align the SFT model using preference pairs to improve domain-appropriate tone and response quality.
- The same training/evaluation interfaces and configurations were used across backends, helping reduce tooling-related variability and keeping comparisons consistent.
3. Training Pipeline & Evaluation
We utilized the Bitext Wealth Management Dataset, applying a two-stage alignment process to transform a raw 4B base model into a specialized advisor .
The Two-Step Process
- Step 1: Supervised Fine-Tuning (SFT)
- Goal: Domain Adaptation.
- Mechanism: We trained on a class-balanced split of advisor-client interactions. This teaches the model the vocabulary of wealth management (e.g., "asset allocation," "risk tolerance") which the base model completely lacked.
- Step 2: Direct Preference Optimization (DPO)
- Goal: Persona & Compliance Alignment.
- Mechanism: Using 2,000 preference pairs, we optimized the model to prefer responses that were not just factually correct, but professionally empathetic and concise which are critical traits for a robo-advisor.
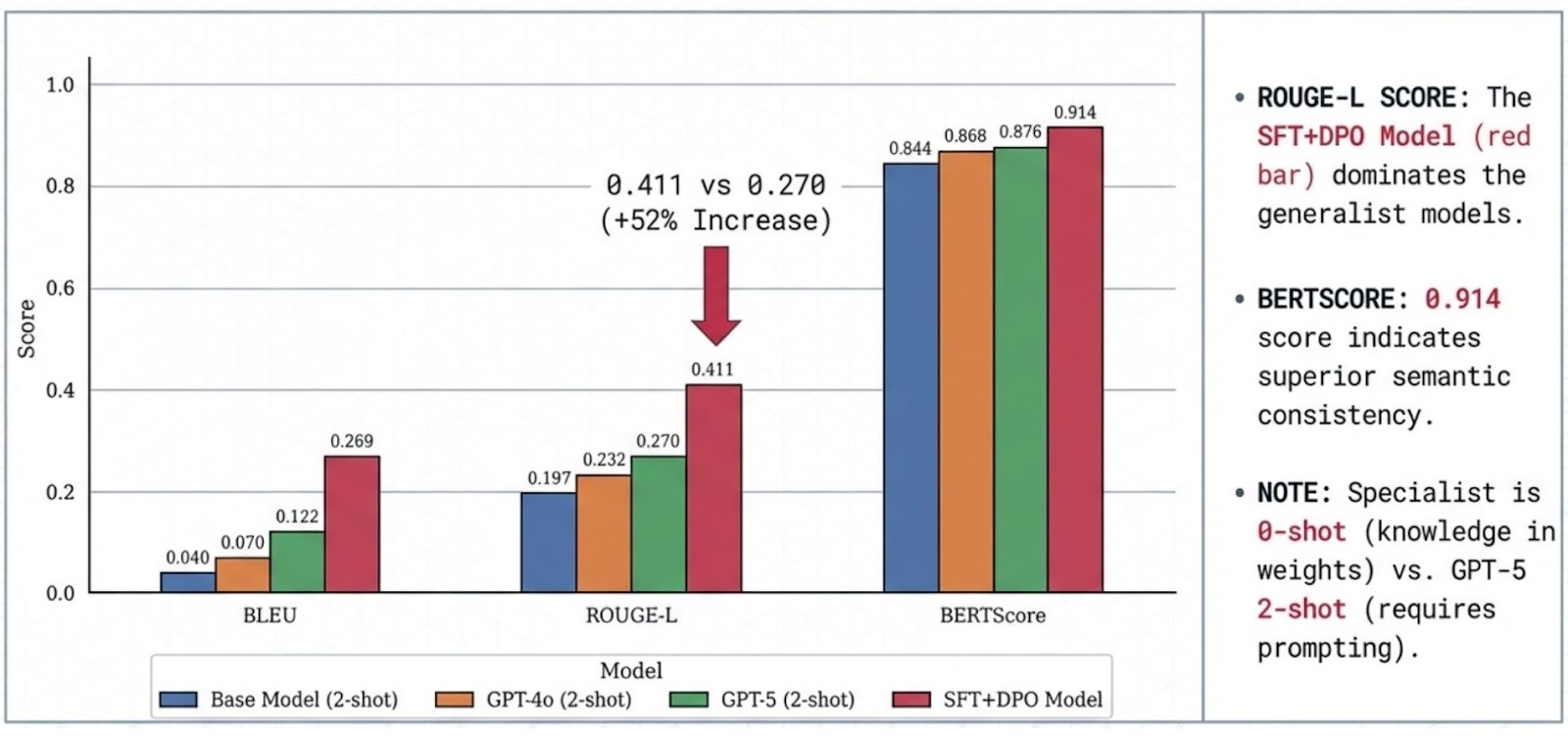
We evaluate the Wealth Specialist with two complementary metric families: lexical overlap (did it say the right words) and semantic similarity (did it convey the right meaning).
Lexical overlap: BLEU, ROUGE, chrF
These compare model outputs to expert references by measuring word/phrase overlap. This matters in wealth management, where precise terminology and mandated phrasing can be important. chrF is slightly more tolerant of inflections and minor wording variations by scoring character n-grams.
Semantic similarity: BERTScore
BERTScore measures whether the output matches the reference in meaning even when wording differs (e.g., “cash out” vs. “withdraw funds”).
Why both: overlap metrics capture adherence to expected phrasing/terminology, while BERTScore captures intent-level correctness when paraphrasing occurs.
For More details refer to <arxiv paper>
4. Experimental Validation
We compare our domain-aligned 4B model against strong general-purpose baselines (GPT-4o and GPT-5). All training and evaluation runs in this study were executed using AlignTune (Lexsi.ai), leveraging its unified SFT/DPO interface and evaluation workflow.
4.1 The SFT Effect
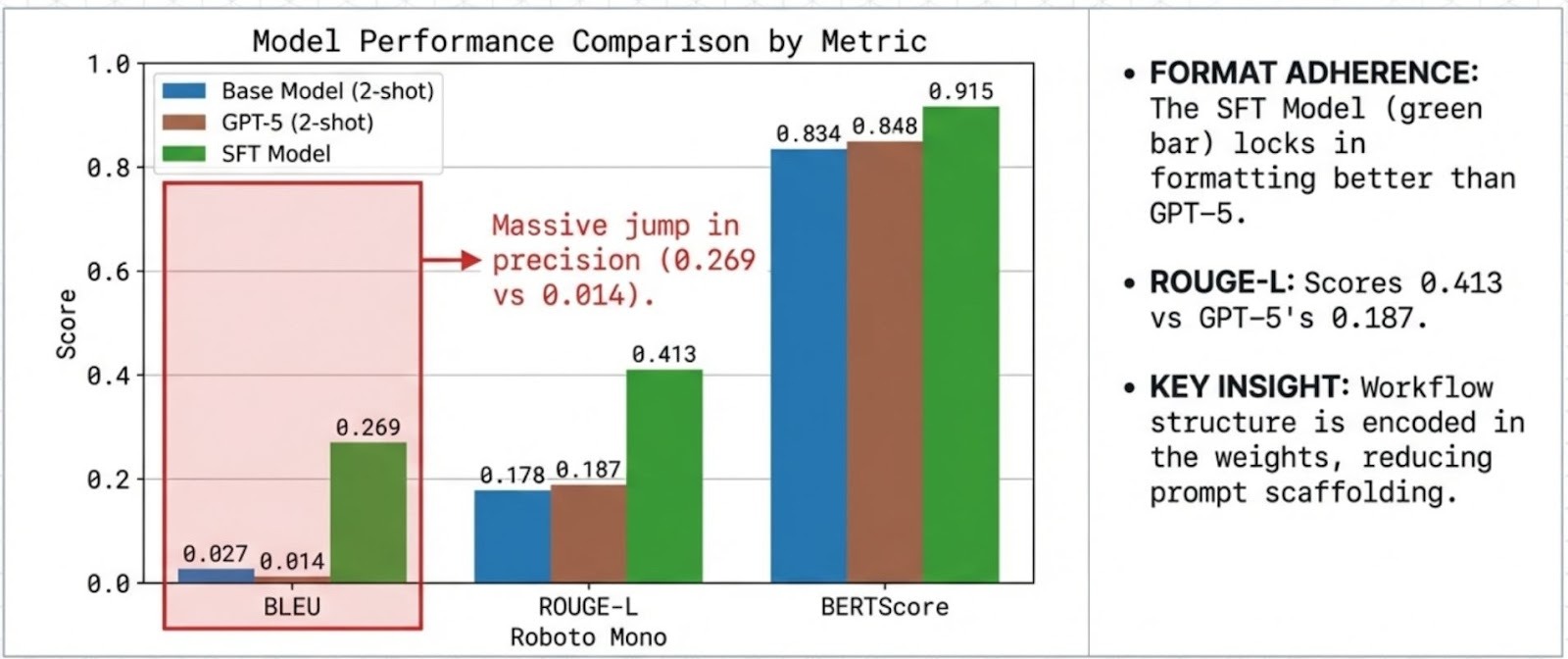
The 4B base model shows low out-of-the-box performance on this dataset (BLEU 0.0286), indicating limited domain grounding prior to adaptation. It cannot speak the language of finance. SFT provides a massive capability injection, raising performance to 0.2690 BLEU.
4.2 Refining Preference and Tone with DPO
While SFT provides the knowledge, DPO refines the delivery. As seen in our results, the DPO Model achieves the highest semantic consistency in the study:
- BERTScore: 0.9142 (Highest across all models)
- ROUGE-L: 0.4113
4.3 Comparison to Closed-Source Baselines (GPT-4o / GPT-5)
In this benchmark and evaluation setup (including 2-shot prompting for the generalist baselines), the domain-aligned DPO model exceeds GPT-5 across the reported metrics (e.g., BLEU 0.2692 vs 0.1218 for GPT-5 2-shot), highlighting the value of specialization for this workflow.
Key Observations:
- Precision over Scale: The DPO model behaves like a specialist. It doesn't need "prompt engineering" or few-shot examples (which acts as noise for fine-tuned models); it simply knows the task.
- Semantic Superiority: The higher BERTScore (0.9142 vs 0.8762) indicates that our model captures the meaning of financial queries better than the generalist GPT-5 in this specific context.
5. Qualitative Examples:
- Base Model : The model treats the user like a student or developer. It provides code and external tools instead of pointing to the wealth management platform's own features. In the second example, it focuses on topics out of the scope of wealth management, such as asking questions about tools related to the meeting or drafting invitations.
- GPT-4o : It offers valid general advice but acts as an external consultant. It fails to recognize that the user is already inside a wealth management platform and likely wants to use that platform's tools. The generalist banking answer in the 2nd example also highlights that the model is unable to interpret wealth management as separate from banking tasks.
- GPT-5 : This is the same "Generalist Trap" that GPT-4o fell into as well. GPT-5 is so intelligent that it explains the underlying mathematical theory (Covariance matrices). While factually impressive, it is useless to a client who just wants to click a button to see their risk score.
- SFT + DPO Model : The model understands the context: "The user is on our platform." It doesn't teach math or suggest Excel; it directs the user to the specific feature that solves the problem. The answers from this model are also closest in terms of alignment with the ground truth where the questions directed to the user are specific to the wealth management domain rather than only banking


6. Conclusion:
This work reframes how we should think about enterprise AI deployment: for regulated, domain-specific workflows, a domain-aligned small language model (SLM) can be a better fit than a purely general-purpose frontier model. Using AlignTune (Lexsi.ai), we curated high-quality domain data and applied DPO to align a compact model suitable for on-prem deployment. The result is a purpose-built on-prem model that matches or exceeds larger generalist baselines on our wealth-management benchmark.