When we do RL-style training (GRPO/DAPO-family) on reasoning tasks, we usually pay every token the same gradient, even if some tokens are pure fluff. We propose a simple fix: mask one reasoning step at a time and measure how much the model’s probability of the correct answer drops. Steps that “break the answer” get more weight in the policy-gradient loss.
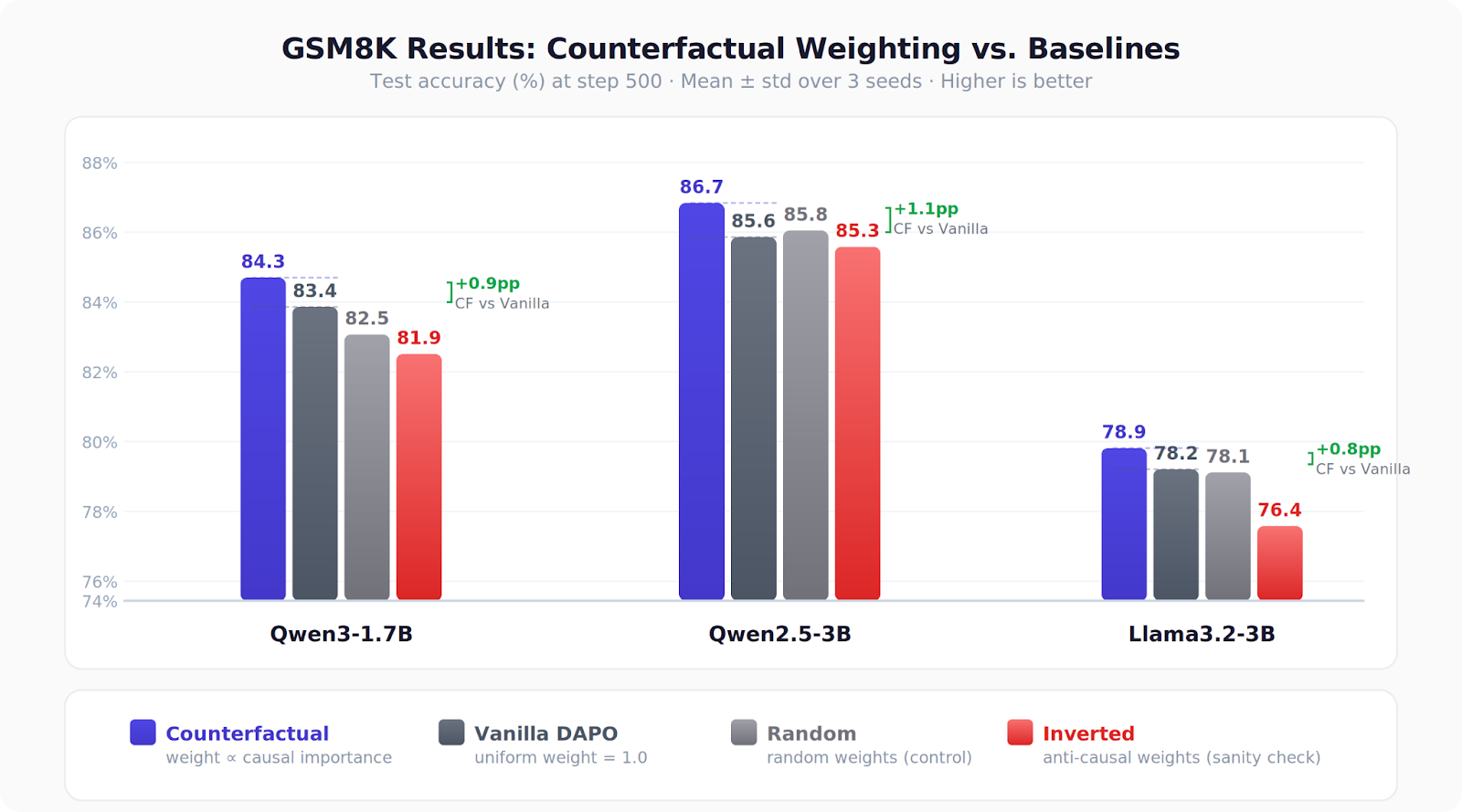
On GSM8K, this yields consistent +0.8 to +1.1 pp gains over vanilla DAPO across three model families, and reaches DAPO’s final accuracy much earlier (as early as step 100 vs 500) . Bonus: we discover that 3.5% of reasoning spans are distractors that hurt answer probability.
When you train a language model with reinforcement learning to solve math problems, something wasteful happens at every gradient step. The model generates a solution like:
“Let me solve this step by step. The store has 36 dishes. 1/6 × 36 = 6 dishes have fresh mango. Total mango dishes: 6 + 3 + 1 = 10. So Oliver can eat 36 − 10 + 2 = 28 dishes.”
Standard algorithms like GRPO and DAPO give every token in that response the same credit. The filler phrase “Let me solve this step by step” gets the exact same gradient update as the critical calculation “1/6 × 36 = 6.” That’s like pricing every ingredient in a sandwich equally, even though some carry most of the flavor.
What if we could figure out which tokens actually caused the right answer, and train harder on those?
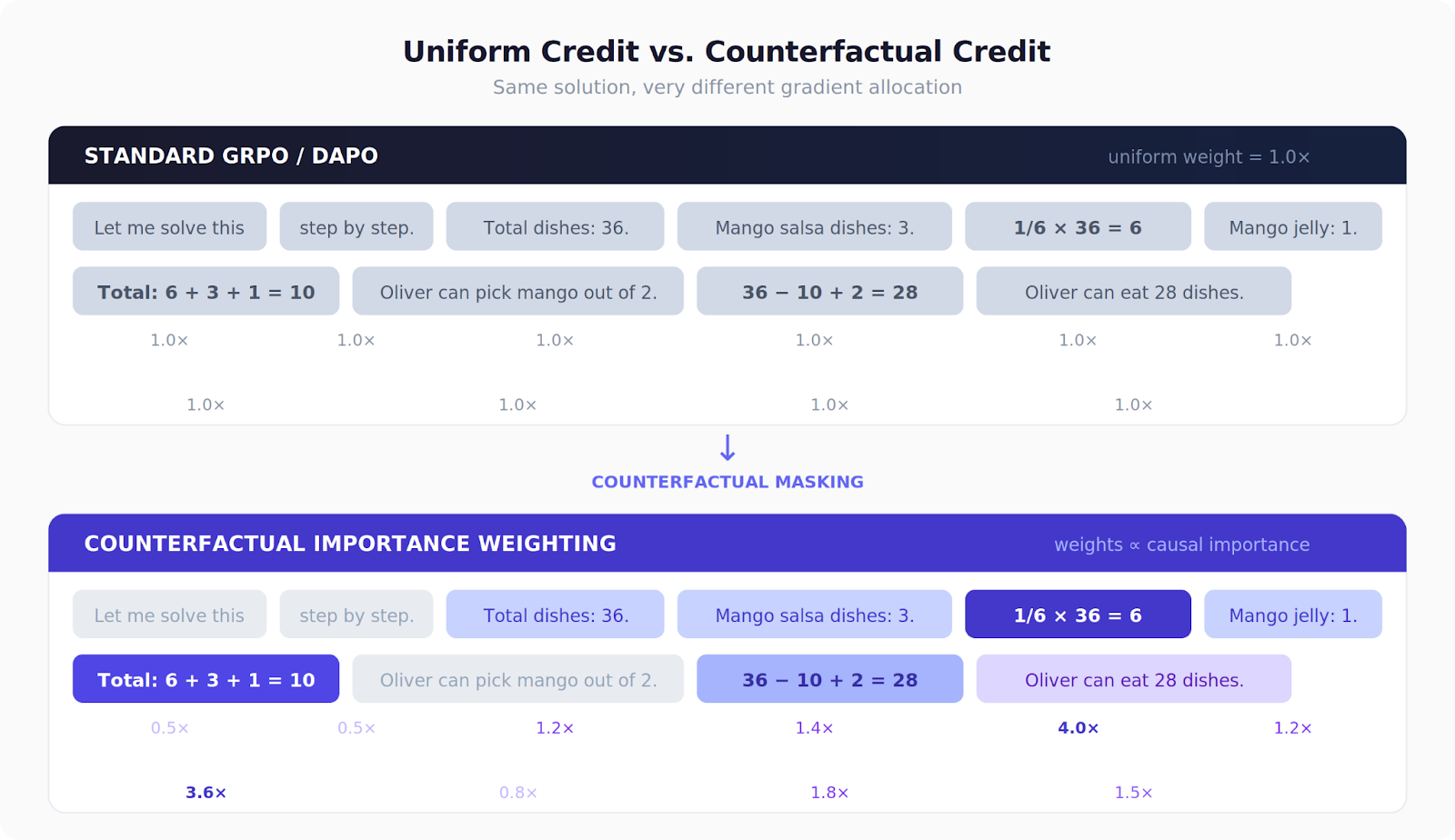
The Idea: Mask It and See What Breaks
The intuition is borrowed from a classic trick in interpretability research: if you want to know whether something matters, remove it and see what happens.
For each reasoning span in a solution (an equation, a calculation step, a sentence), we:
- Mask it out — replace it with placeholder tokens
- Measure the damage — how much does the probability of the correct answer drop?
- Use that as a training signal — spans whose removal tanks the answer probability get higher weight in the policy gradient
We call this counterfactual importance weighting — “counterfactual” because we’re asking “what would have happened if this span weren’t here?”
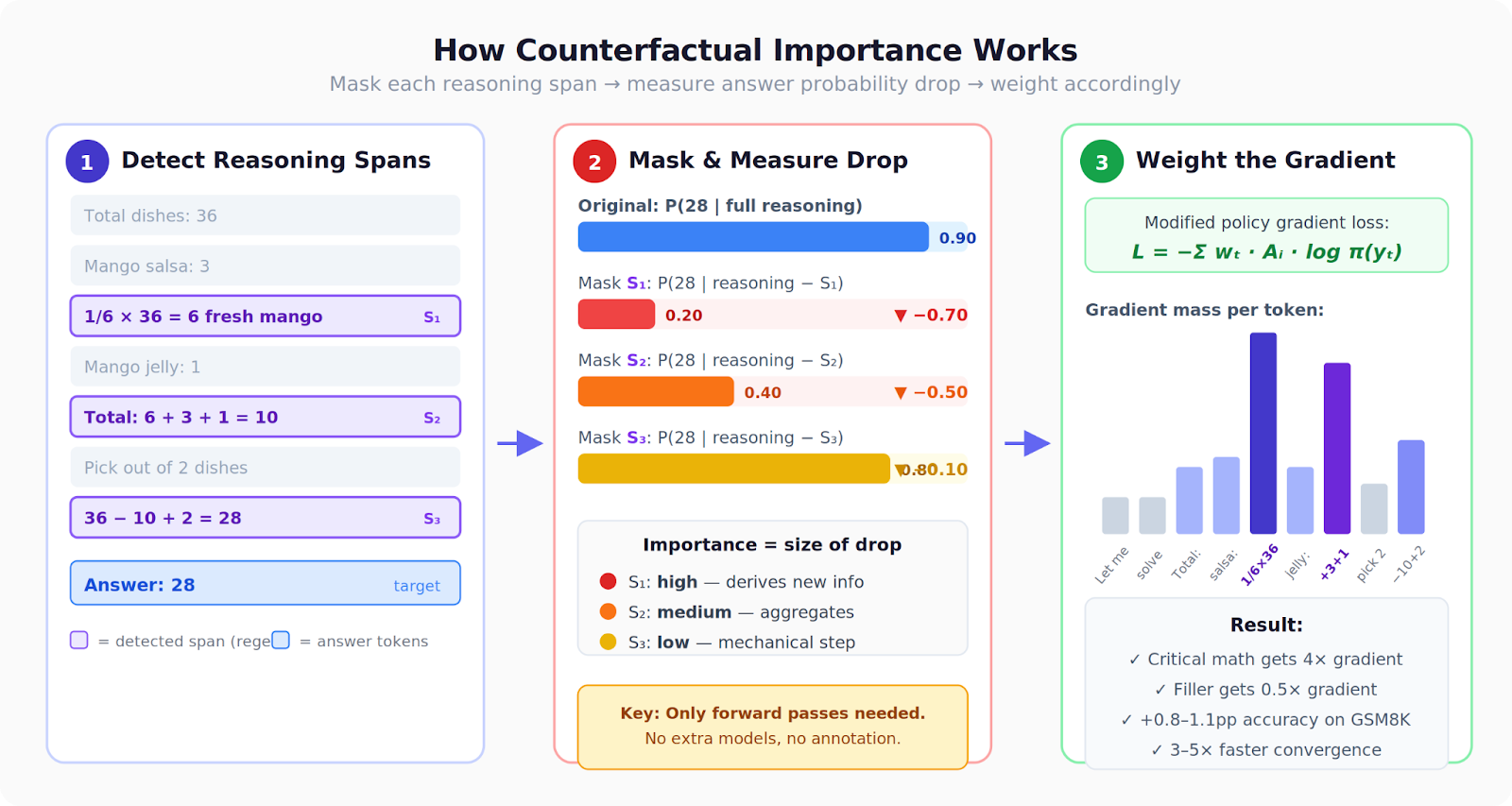
A bit more formally
A model generates a completion that splits into reasoning r followed by a final answer a. For each reasoning span sₖ (an equation, a calculation), we compute the counterfactual drop:
That’s just the change in answer log-probability when you mask out span sₖ. If D is very negative, the span was critical — removing it destroyed the model’s ability to reach the answer. If D is positive, the span was actually a distractor — the model does better without it.
Tokens outside any detected span get weight 1.0 (unchanged). Answer tokens get a fixed boost.
These weights plug directly into the policy gradient loss. Standard DAPO computes:
That’s the entire change. The advantage Aᵢ is still computed per-completion as in standard DAPO — we just modulate how much each token’s gradient contributes based on its counterfactual importance.
A few practical notes: we operate on spans (like “23 + 45 = 68”) rather than individual tokens, because per-token masking would need hundreds of forward passes per completion while span-level masking needs only 5–10. Spans are detected with regex patterns matching arithmetic expressions and sentence boundaries. All the counterfactual forward passes run under torch.no_grad(), so there’s no memory overhead — just compute.
What We Found in the Reasoning Traces
Before even getting to training results, the importance scores themselves reveal something interesting about how LLMs reason.
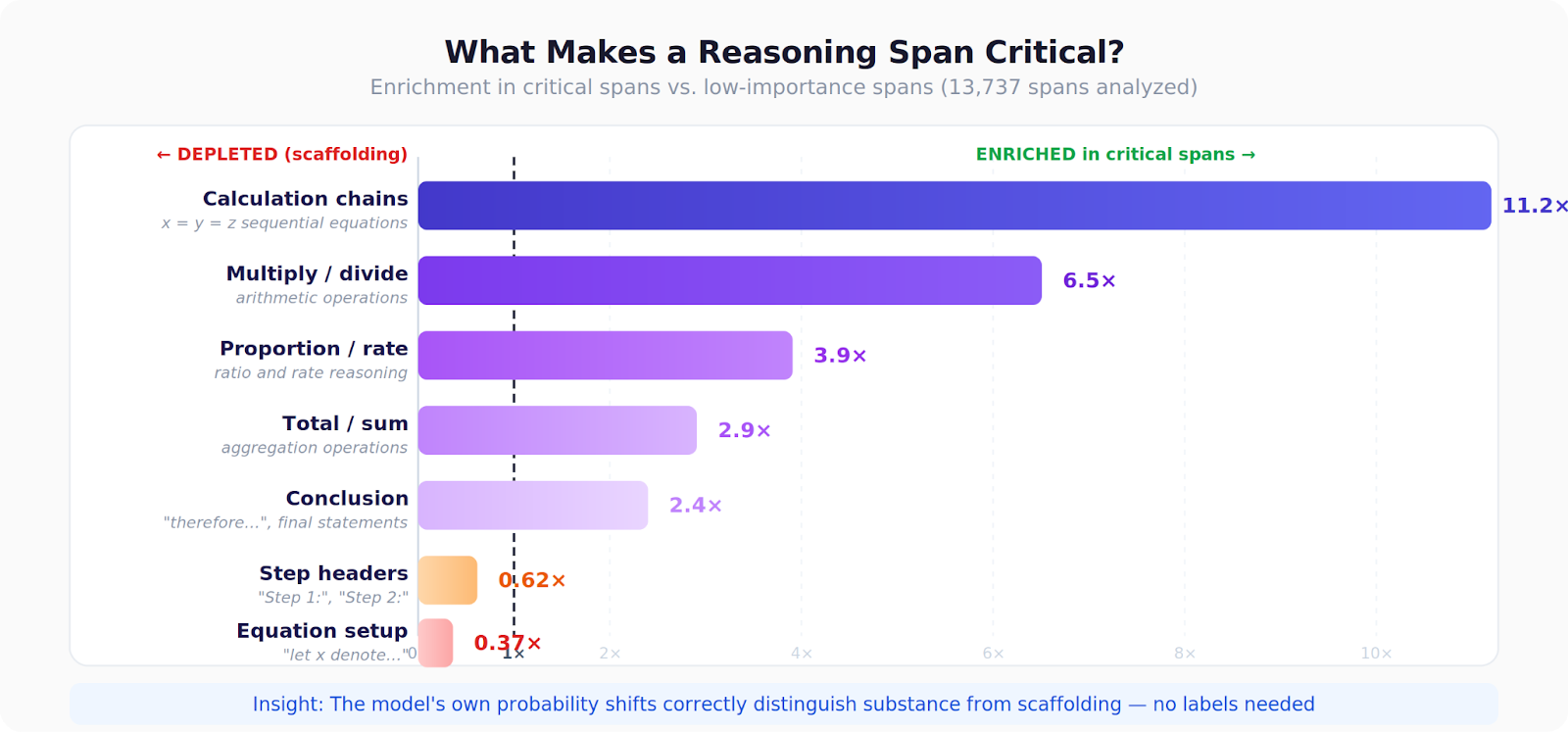
We analyzed ~14,000 spans across ~1,500 completions and found a clear hierarchy:
- Calculation chains (like “x = y = z”) are 11× more likely to be critical than other content
- Multiplication and division steps show 6.5× enrichment in critical spans
- Setup text (“let x denote...”) and step headers (“Step 1:”) are depleted among critical spans — they’re scaffolding, not substance
Perhaps most surprisingly, 3.5% of spans are outright distractors — masking them actually improves the answer probability. These are typically verbose restatements of given information or unnecessary scaffolding. Standard uniform-credit training actively reinforces this noise.
Here’s a concrete example. For a problem about counting dishes at a buffet:
Reasoning Span
Importance
“Fresh mangoes: 1/6 × 36 = 6 dishes”
★★★★★ (highest)
“Total mango: 6 + 3 + 1 = 10 dishes”
★★★★
“Dishes with mango salsa: 3”
★★
“Total number of dishes: 36”
★★
“Final: 36 − 10 + 2 = 28”
★ (lowest)
The fraction calculation scores highest because it derives new information. The final subtraction scores lowest because once you know the mango count, the rest is mechanical. The method gets this right without any notion of “what a calculation is” — it’s purely based on probability shifts.
Training Results: Modest but Real
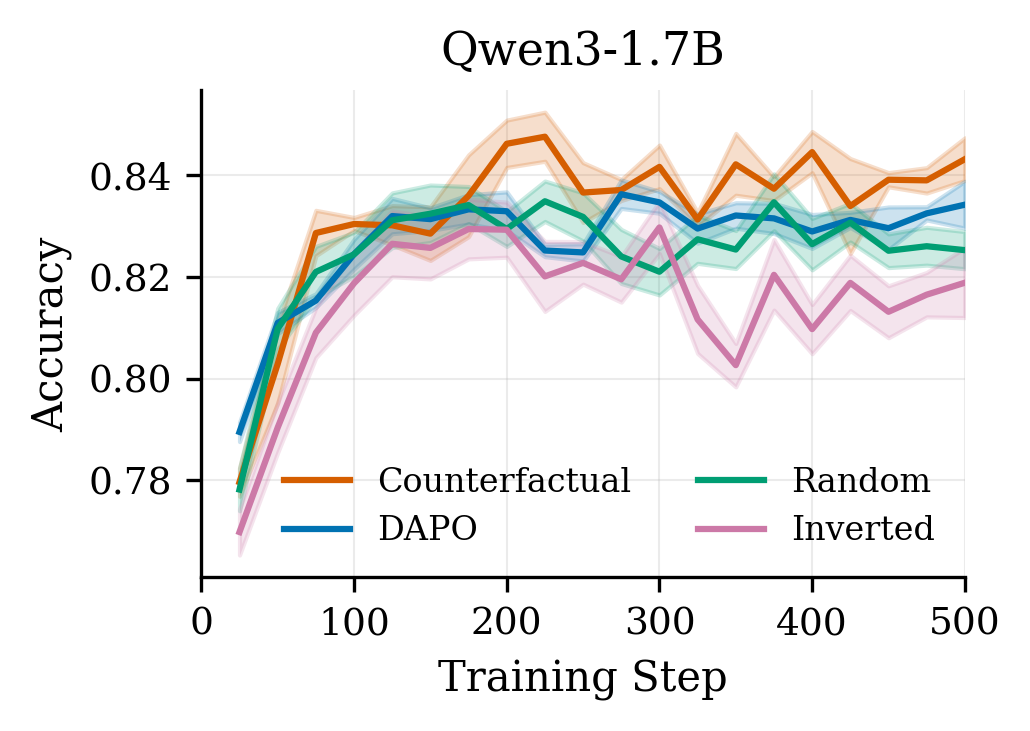
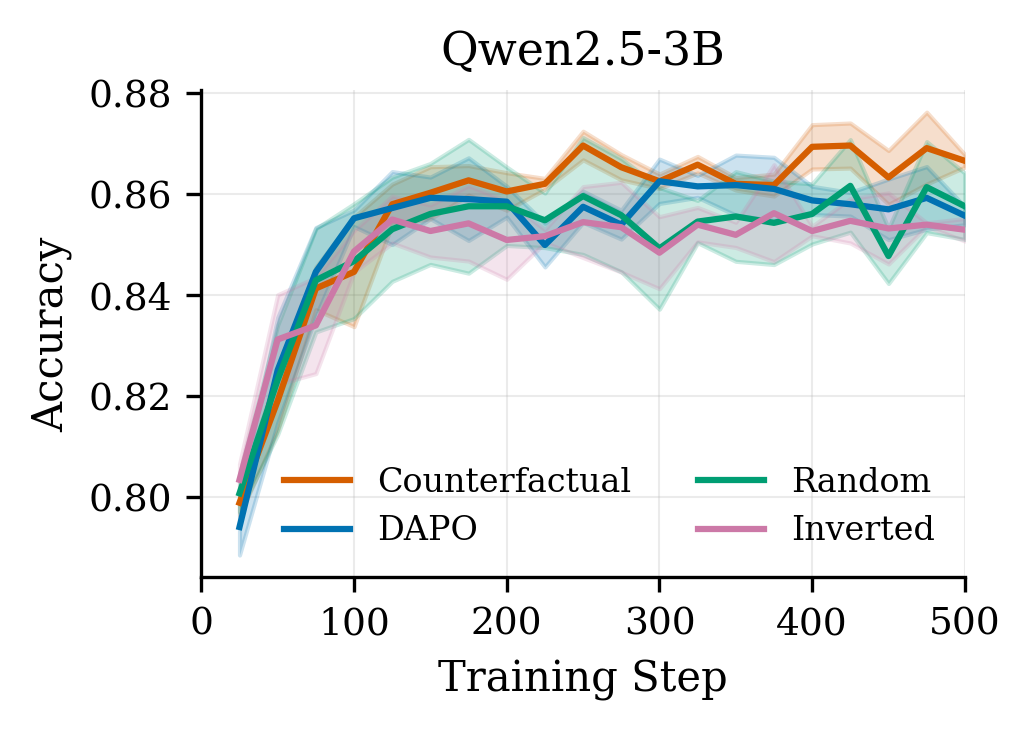
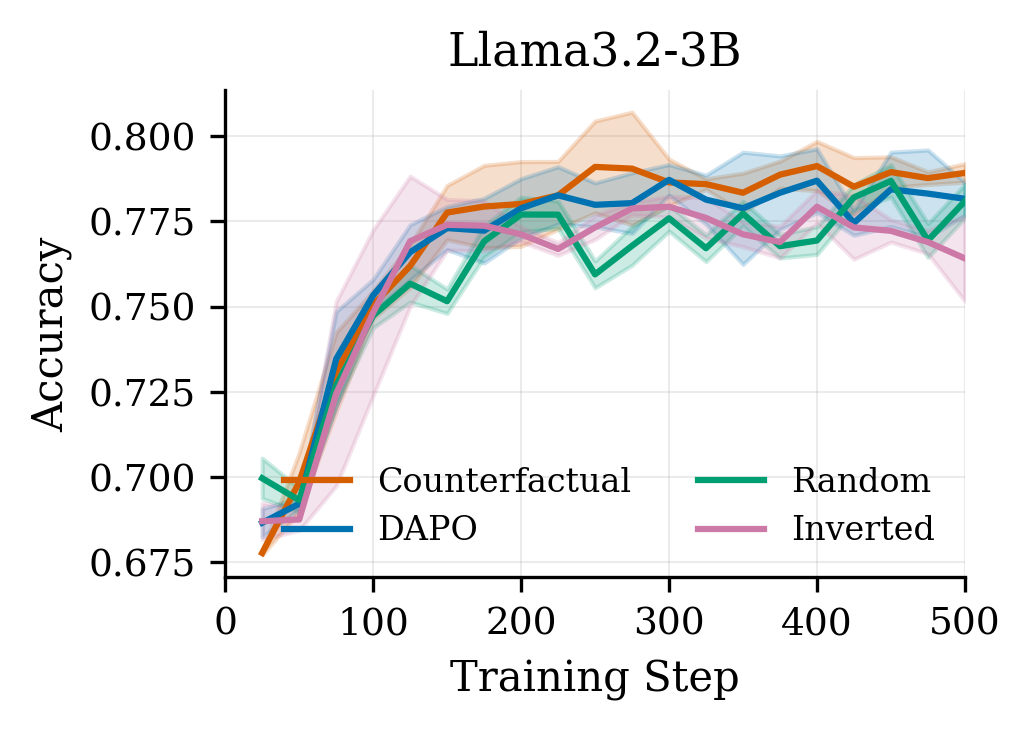
We tested on GSM8K across three models (Qwen3-1.7B, Qwen2.5-3B, Llama3.2-3B) with a clean ablation setup comparing four conditions:
- Counterfactual — weight by measured causal importance
- Vanilla DAPO — uniform weights (the baseline)
- Random — random weights (control)
- Inverted — weight against importance (the key sanity check)
Results across all three models:
Counterfactual > Vanilla ≥ Random > Inverted
The gains are +0.8 to +1.1 percentage points — not earth-shattering, but consistent across every model family and seed. More importantly, the inverted condition consistently hurts performance (up to −1.8pp vs. vanilla), confirming we’re capturing real signal, not just benefiting from weight noise.
The convergence speedup is arguably more compelling: counterfactual weighting reaches vanilla’s final accuracy 3–5× faster in training steps. On Qwen3-1.7B, CF hits vanilla’s step-500 accuracy by step 100.
Where It Doesn’t Work
Transparency about negative results: this doesn’t help for code generation. We tested on MBPP+ and found no benefit over vanilla DAPO.
The reason is intuitive. In math, there’s a single numeric answer — an “answer sink” that creates a clean counterfactual signal. Mask a key calculation and the answer probability collapses. In code, correctness is distributed across control flow, variable bindings, return statements, and more. No single span’s removal is catastrophic in the same way.
This tells us something about when token-level credit assignment matters most: tasks with concentrated verification signals, where a small number of reasoning steps disproportionately determine success.
Why This Matters Beyond Our Specific Method
We see this work less as “use this exact technique” and more as evidence for a broader principle: the model already knows which of its tokens matter — you just have to ask it the right way.
The counterfactual framing is a natural one: don’t look at what correlates with correct answers, look at what causes them. This is the same shift from attention-based to intervention-based interpretability that transformed mechanistic analysis of transformers — applied to training signals instead.
A few things that excite us about future directions:
- Combining with process reward models: Our importance scores are complementary to PRMs — we measure causal contribution, they measure step correctness. Using both could be powerful.
- Better span detection: We used regex for arithmetic patterns. LLM-based or syntactic span detection could capture more nuanced reasoning structure.
- Scaling: We tested up to 3B parameters. Whether larger models internalize credit assignment better (reducing the benefit) or have more tokens to differentiate (increasing it) is an open question.
- The distractor finding: The fact that 3.5% of reasoning spans actively hurt answer probability suggests a data-filtering or curriculum learning angle — remove the noise before training, not just downweight it during.
The Practical Takeaway
If you’re training models with GRPO/DAPO on math or similar tasks with verifiable answers:
- Not all tokens contribute equally to task success — the gap is dramatic (11× between critical and scaffolding spans)
- You can measure this with just forward passes — no extra models needed
- Weighting by this signal gives small but consistent gains and notably faster convergence
- The overhead (32–74% more compute per step) is offset by needing fewer steps to reach target accuracy