TL;DR: Production AI fails less on “capability” and more on reliability: consistent schemas, domain terminology, policy compliance, and stable behavior at scale. Today, teams often patch generalist models with prompts and guardrails, but that gets fragile as requirements tighten. Fine-tuning tools like TRL and Unsloth are strong building blocks, yet scaling post-training still requires stitching together configs, rewards, evals, and reproducibility. AlignTune is the missing operational layer: a unified, config-first post-training workflow across SFT, DPO-style preference optimization, and RL methods, with backend-aware isolation, composable rewards, and standardized evaluation, designed to bridge fast-moving alignment research into production-ready engineering.
Most AI teams aren’t stuck because models can’t do the job.
They’re stuck because production requirements are sharper than “general capability”: outputs must follow a schema, terminology must match the domain, safety and policy boundaries must hold under pressure, and behavior needs to stay stable as specs evolve.
Over the last year, we kept seeing the same pattern: teams reach for the biggest available API model for workflows that demand precision and repeatability, then spend weeks compensating with prompt scaffolding, retries, guardrails, validators, and post-processing. The result is often usable, but it’s also fragile. And when you scale usage, introduce compliance constraints, or tighten templates, the cracks show up fast.
If you’re building business-critical AI, the real challenge isn’t “smarter models.” It’s models that reliably fit your system.
That’s why we’re releasing AlignTune, an open-source library designed to make post-training alignment and fine-tuning practical at scale, with a workflow that feels closer to “calling an API” than assembling a research stack.
The gap between generalists and production systems
Frontier models are excellent generalists. They’re trained to handle a huge range of tasks, styles, and intent. That breadth is valuable, but in production, most teams care about a narrower set of constraints:
- Consistency: same input pattern → same structure, tone, and schema
- Traceability: clear evaluation, repeatable training runs, comparable experiments
- Policy adherence: formatting rules, compliance constraints, safe defaults
- Operational fit: latency/cost ceilings, deployment constraints, data boundaries
When those are your priorities, a smaller task-adapted model can be a better fit. Not because it’s “smarter,” but because it’s easier to shape to a specific workflow and easier to run predictably at scale.
That’s the case for specialization: post-training via SFT, preference optimization, and RLHF-style methods.
But there’s a catch.
Why fine-tuning at scale still feels like research plumbing
TRL gives you solid primitives for SFT and preference optimization, but most teams quickly find they still need a thin “platform layer” around it to scale work cleanly: a consistent experiment harness (configs, runs, tracking, comparisons), reusable reward definitions, and standardized evaluation that doesn’t drift across iterations.
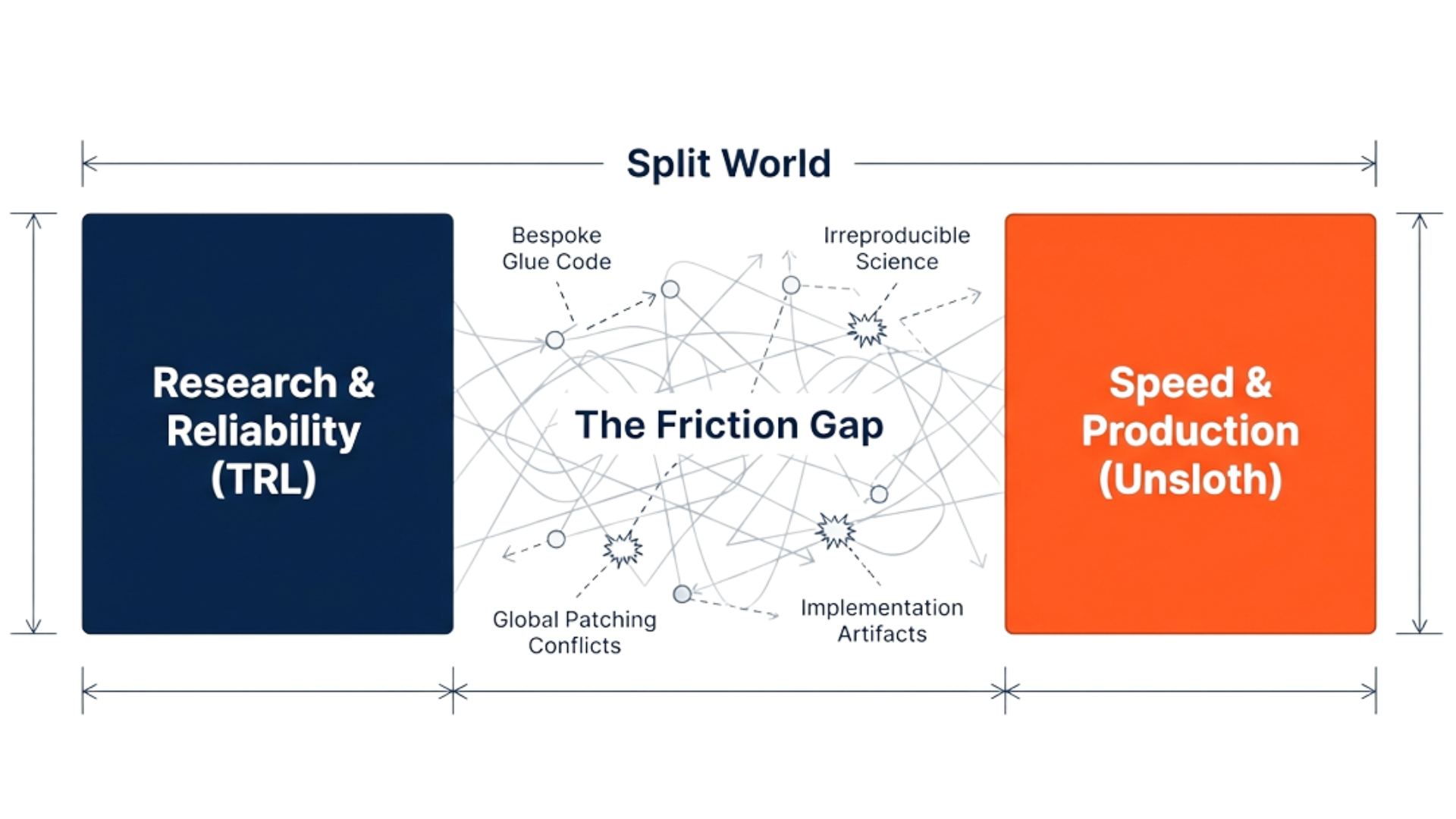
Unsloth, on the other hand, delivers meaningful speed and memory gains, which is exactly what you want when iteration cost matters. The tradeoff is that those optimizations often operate at the framework level, so teams typically add a bit of isolation and process discipline to keep runs reproducible and comparisons fair across environments and backends.
In other words, the building blocks are strong, but the operational workflow still isn’t standardized by default, especially once you’re running multiple methods, backends, and domains in parallel.
So teams trying to scale fine-tuning hit a familiar wall:
- Backend interference: running TRL and Unsloth in the same environment can create cross-contamination unless you isolate imports and execution paths
- Configuration skew: “same experiment” is not actually the same once backend-specific flags and setup differences creep in
- Reward fragmentation: reward functions, heuristics, and constraints live in too many places, so ablations and audits become painful
- Irreproducible pipelines: scripts drift, parameters get lost, and results become hard to compare across time and teams
- The reliability vs speed tax: you choose either stable baselines or fast experiments, and spend cycles bridging the gap
It’s not that the tools are bad. It’s that the workflow is still too piecemeal for teams who want to move from experiment to reliable system.
Introducing AlignTune
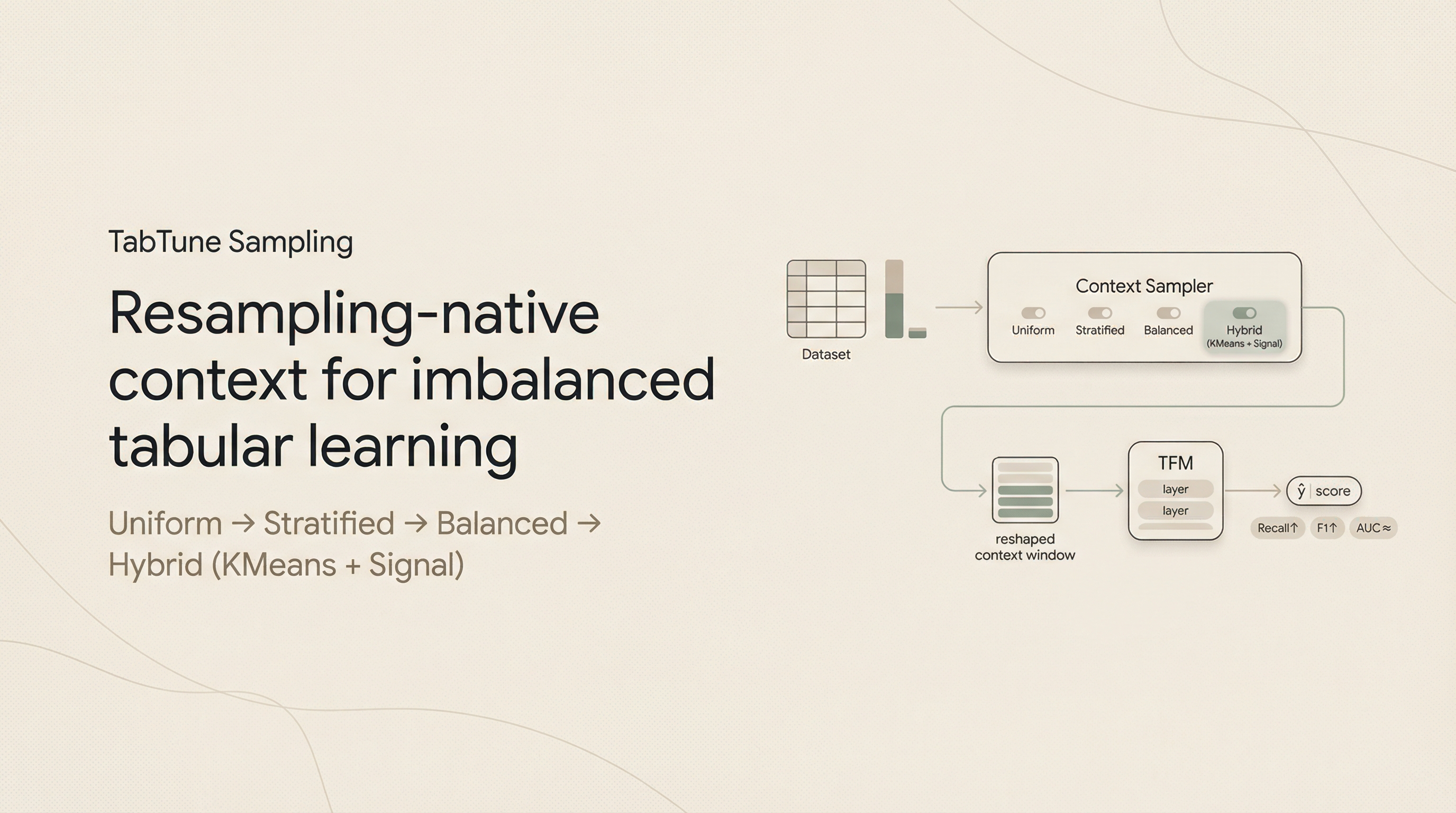
AlignTune is our response to that gap: an open-source library that makes it practical to build and maintain domain-specific language models with a workflow built for repeatability.
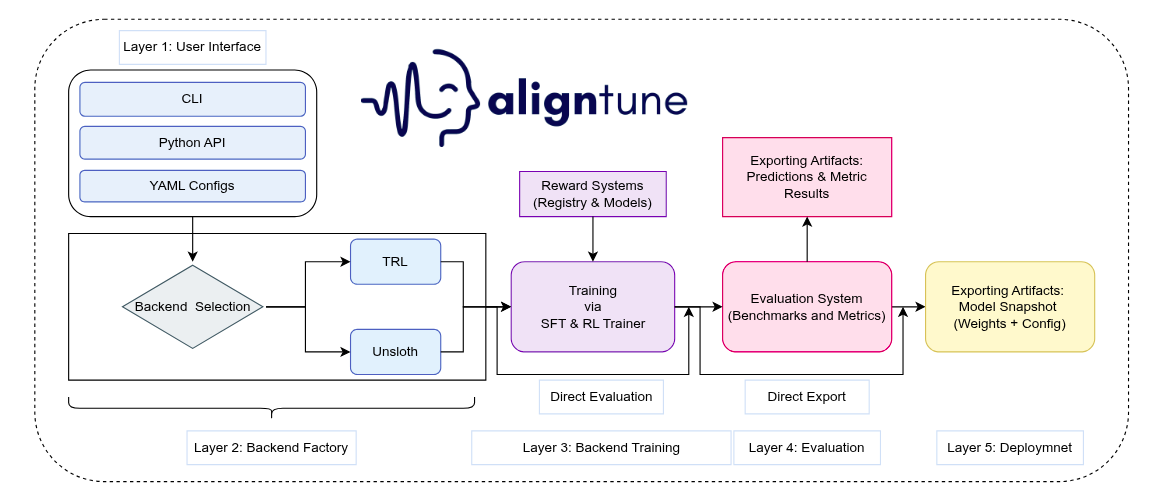
Think of AlignTune as the missing layer between “trainer libraries” and “production fine-tuning systems.”
AlignTune is a pragmatic attempt to standardize what most teams end up building anyway:
- One interface across common fine-tuning and preference-optimization methods
- Config-first runs so experiments are reproducible, reviewable, and comparable
- Backend-aware isolation so TRL and Unsloth can be used without contaminating each other
- Composable rewards so you can define “good” in terms that match your workflow
- Built-in evaluation hooks so you measure what you care about before you deploy
The goal isn’t to replace the ecosystem. It’s to make it operational.
What AlignTune unlocks for real teams
1) A unified post-training interface
AlignTune provides a single, consistent workflow across:
- Supervised fine-tuning (SFT)
- Preference optimization (DPO-style methods)
- RLHF-style variants (PPO/GRPO-family approaches)
Instead of rewriting pipelines when you switch methods, you keep the same structure and swap configs.
2) A research-to-production bridge for alignment
Post-training moves fast. New alignment methods show up constantly, but most teams can’t afford to retool their training stack every time a paper drops. AlignTune is designed to be the consolidation layer that tracks the state of the art while keeping a stable engineering workflow.
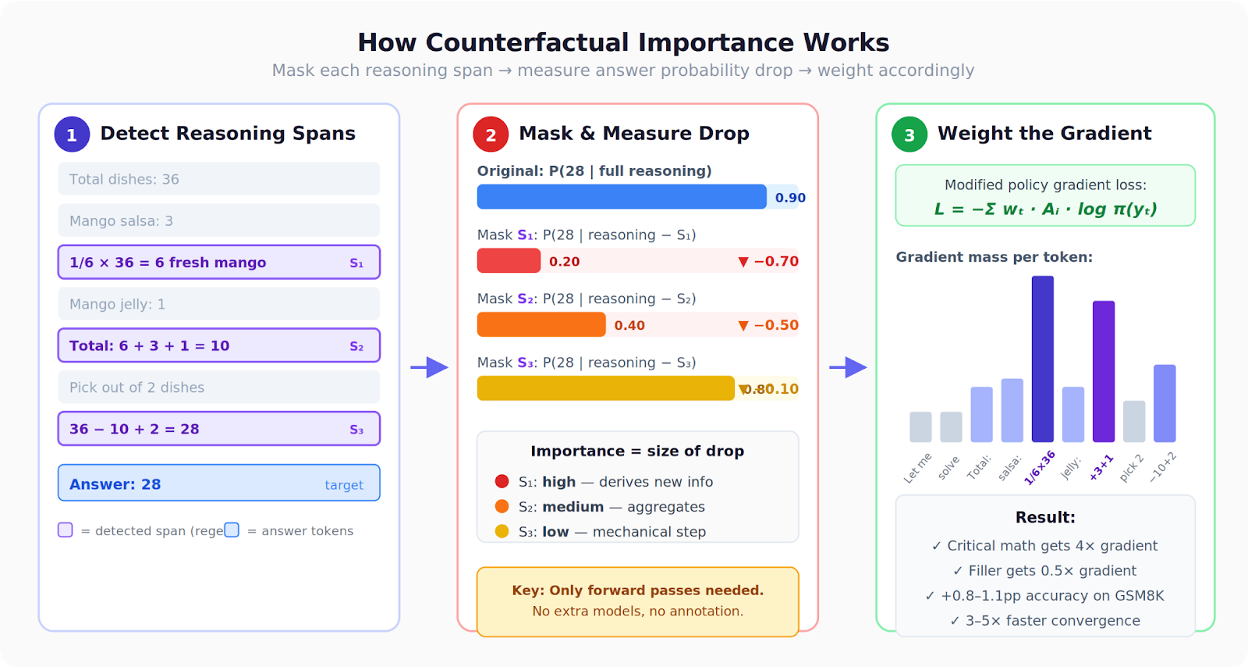
In practice, that means AlignTune becomes a single place where major alignment advances land behind a consistent interface, including newer RL methods like Dr. GRPO, Counterfactual GRPO, PACE, and GBMPO (Lexsi Labs), alongside the standard toolchain.
3) Reproducibility by default
Fine-tuning is engineering, which means:
- Configs should be versionable artifacts
- Runs should be repeatable
- Results should be comparable across methods, backends, and time
AlignTune is built so “how did we train this?” doesn’t turn into archaeology.
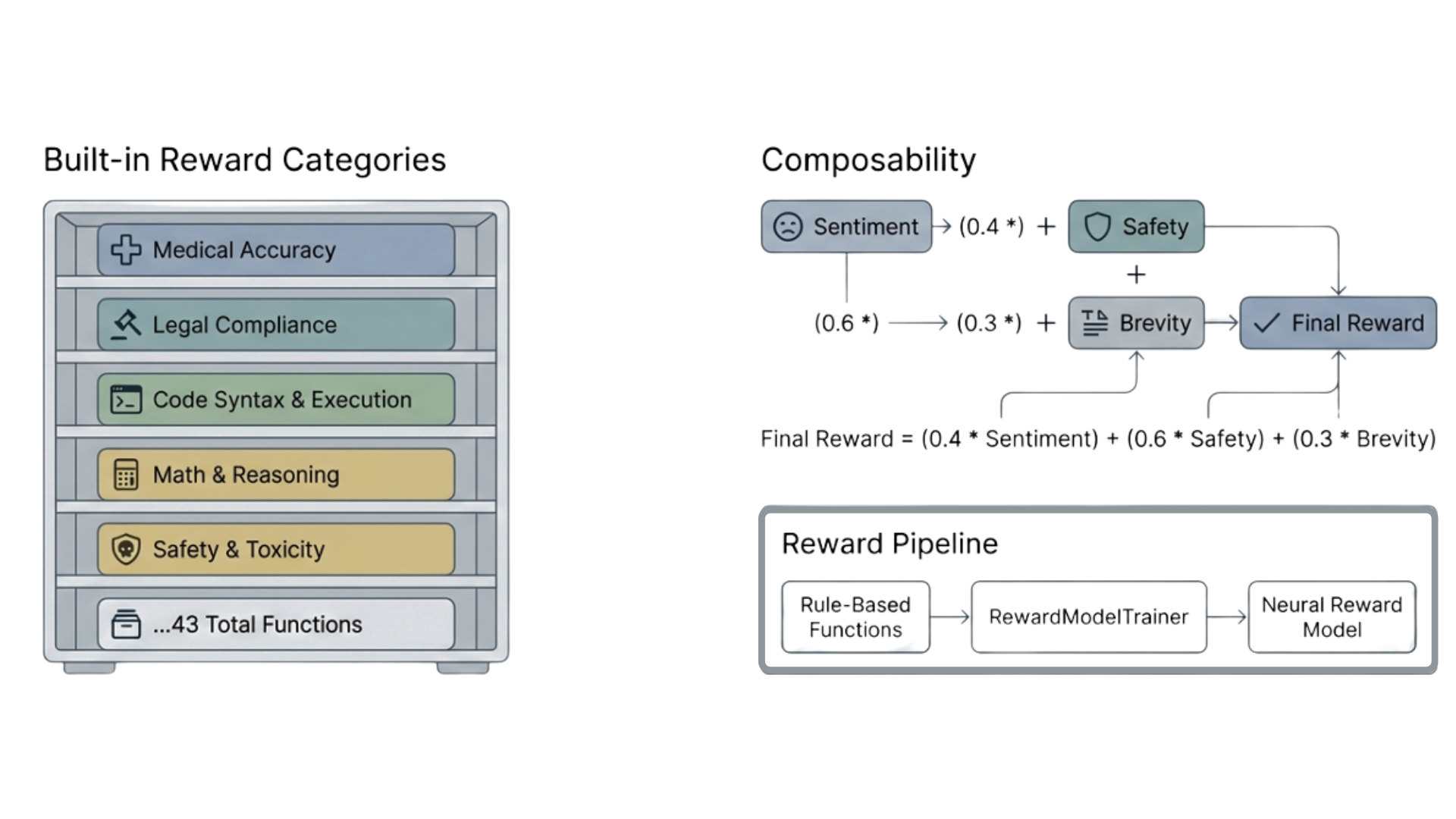
4) Rewards that match production definitions of “good”
Most production failures aren’t “the model is dumb.” They’re “the model is inconsistent,” “it ignores our template,” “it violates policy under edge cases,” or “it uses the wrong terminology.”
AlignTune makes reward design and composition a first-class concern, so you can encode what you actually care about:
- Format adherence
- Terminology fidelity
- Safety/policy compliance
- Style consistency
- Task-specific validators
5) Backends without chaos
AlignTune explicitly handles the reality that teams want both:
- TRL’s widely used training surface area
- Unsloth’s acceleration and memory efficiency
But without accidentally mixing or contaminating experiments. AlignTune’s backend selection and isolation mechanisms are designed to keep runs comparable and reproducible.
Who AlignTune is for
AlignTune is for teams building AI systems where owning behavior matters as much as model capability. If “generally helpful” isn’t enough, and you need models that are predictable, auditable, and upgradeable, AlignTune is built for you.
- Enterprises building and owning AI assets on OSS: For organizations investing in open models as long-term assets, AlignTune provides a structured way to build domain specialists you can own end-to-end: training recipes, reward definitions, eval suites, and reproducible runs. This is especially relevant when AI needs to live inside your environment, under your governance, with behavior that can be explained and maintained like any other critical system.
- AI engineers shipping product-grade LLM workflows: If you’re an AI engineer responsible for reliability, latency, cost, and integration constraints, AlignTune helps turn post-training into an engineering loop: train → evaluate → compare → deploy, without rewriting pipelines across methods. It’s designed for teams who want the model to carry more of the workflow structure in the weights, reducing prompt scaffolding and downstream patchwork.
- Regulated and compliance-heavy teams: Teams in finance, healthcare, insurance, and other regulated domains often need tighter guarantees: policy adherence, controlled templates, safer defaults, and clear audit trails. AlignTune supports building specialists that behave consistently under constraints and can be evaluated against compliance-specific criteria before deployment.
- Platform and ML infrastructure teams: If you support multiple product lines or business units, you need a standard workflow that scales across domains: shared training pipelines, reusable reward components, comparable evaluation, and reproducible configs. AlignTune gives you a consistent interface and a consolidation layer that can absorb new alignment methods without forcing a redesign every quarter.
- Product teams: When you’re building a narrow workflow and iteration speed matters, specialization is often the shortest path to reliability. AlignTune is built to help you get from dataset to a specialist model quickly, while keeping the loop clean enough to iterate without chaos.
If you’ve ever said: “We can’t ship this because the output format is unstable,” or “We need to own this behavior, not babysit it,” AlignTune is for you.
Case studies (benchmark-scoped)
To ground AlignTune in real workflows, we ran two benchmark-scoped case studies where a compact 4B open model was specialized for regulated support tasks. In both, the specialist models were trained and evaluated through AlignTune’s unified training + evaluation workflow.
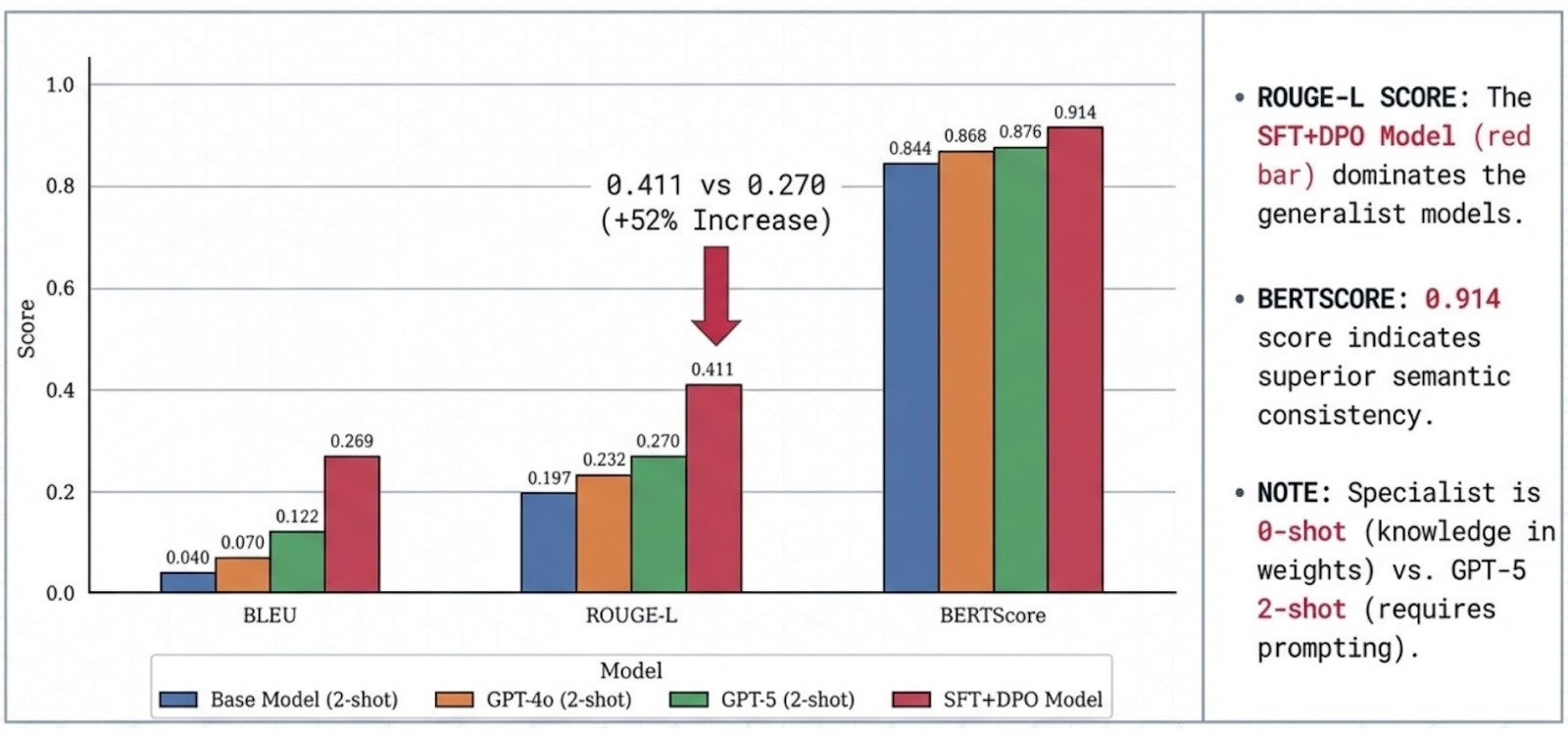
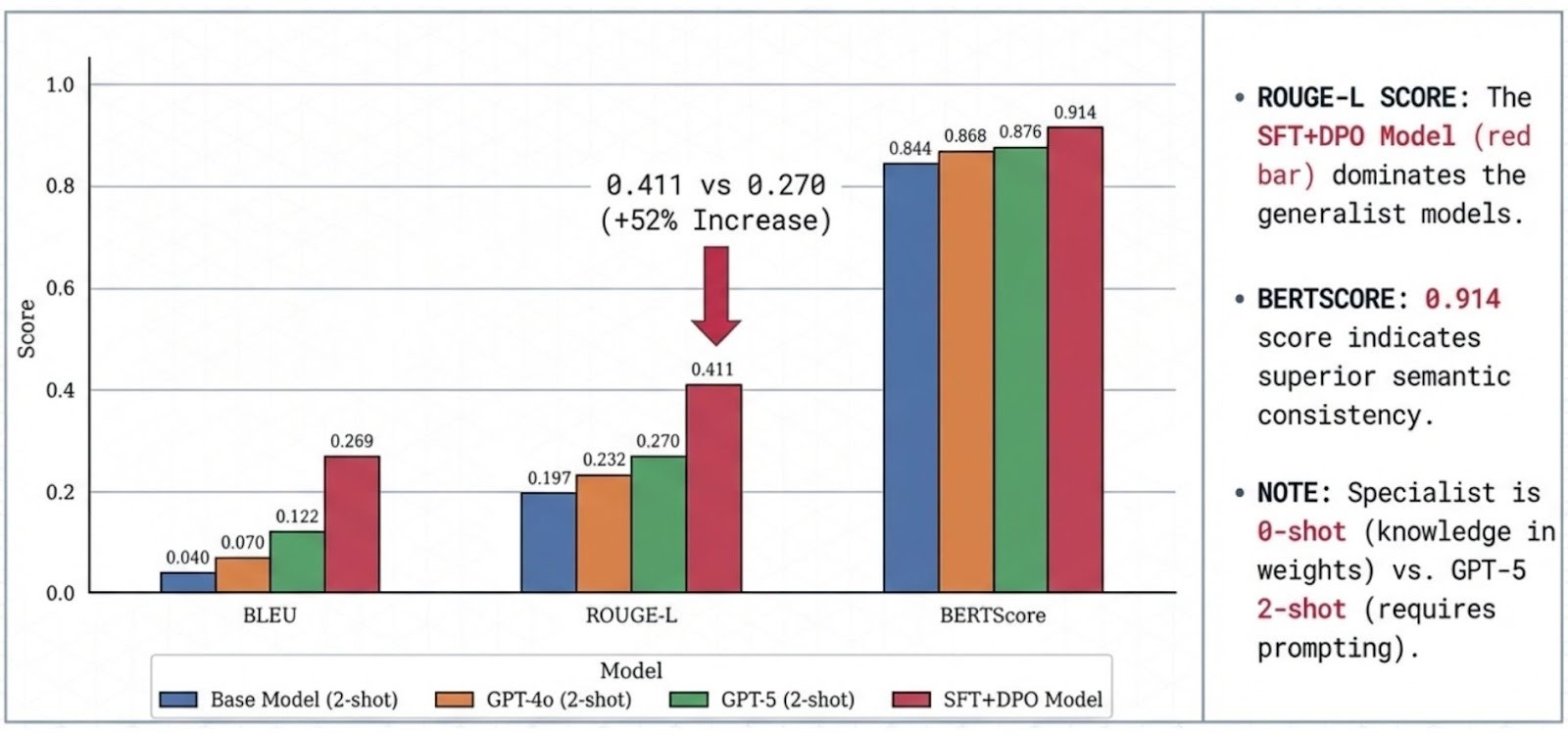
Case Study 1: Wealth Management Specialist (4B, SFT + DPO)
A domain-aligned advisor model tuned for precise terminology, professional tone, and platform-aware responses.
Highlights (benchmark-scoped):
- ~52% higher ROUGE-L than GPT-5 (2-shot) under the same evaluation protocol
- Higher semantic consistency (BERTScore) and stronger template/terminology overlap metrics
Read the full case study:
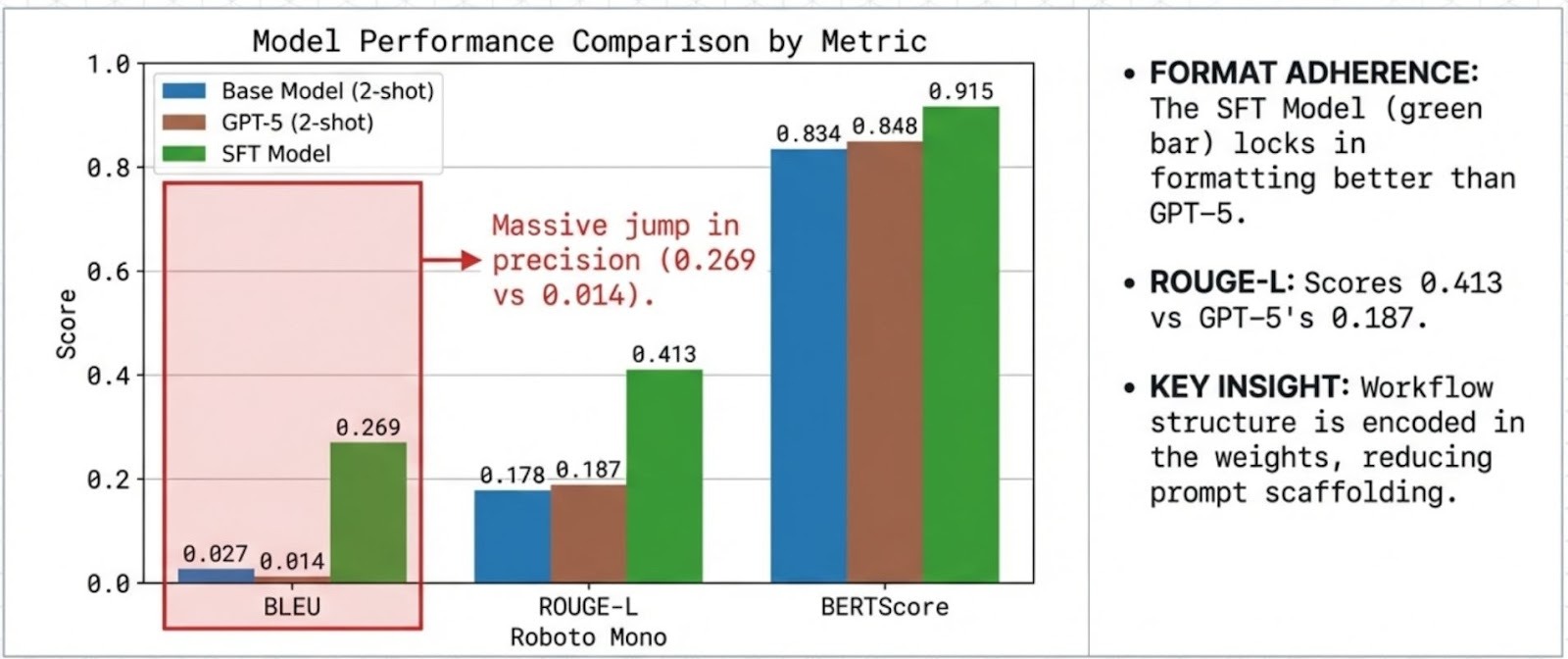
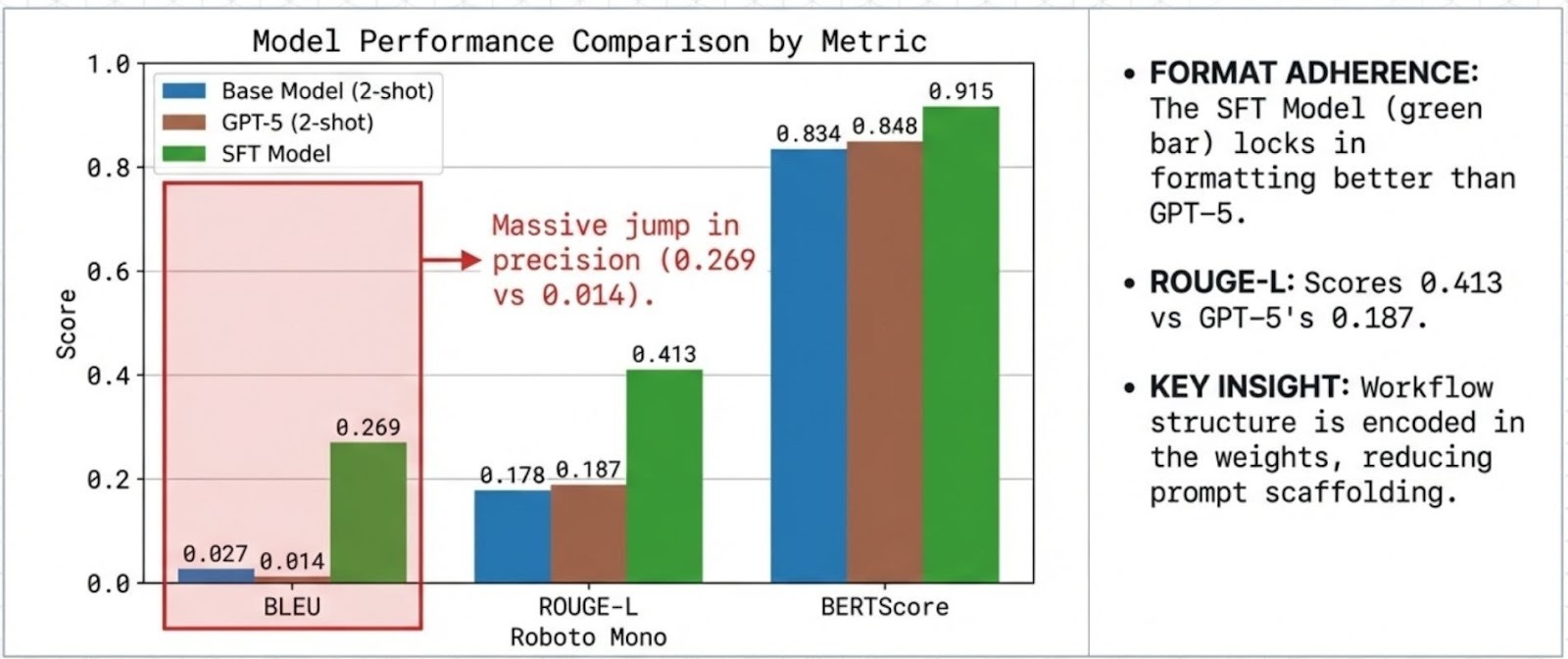
Case Study 2: Retail Banking Specialist (4B, SFT)
A procedural banking assistant optimized for strict templates (activation, limits, verification, blocking) and predictable formatting.
Highlights (benchmark-scoped):
- Stronger format/lexical adherence than GPT-5 (2-shot) on the standardized task setup
- Designed to reduce prompt scaffolding by encoding workflow structure directly into the model
Note: In these evaluations, GPT-5 is prompted with 2-shot examples, while the specialist is evaluated 0-shot because the task format is encoded in the weights.
The vision: specialists as a normal engineering workflow
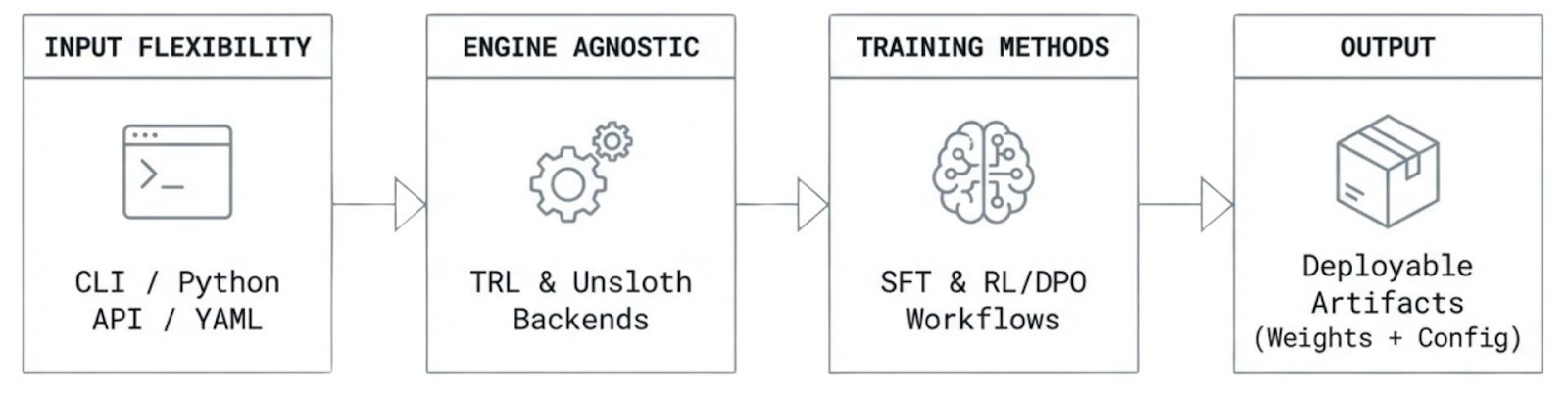
Our long-term view is simple: training and aligning specialists should feel like software engineering, not research plumbing.
Over the next iterations, we want AlignTune to become a practical “control plane” for specialization:
- Better dataset ergonomics (common formats, validators, data quality checks)
- Stronger evaluation (domain-specific test suites)
- Reproducibility by default (configs, seeds, standardized reporting)
- Continued support for newer, more efficient state-of-the-art alignment algorithms as they emerge, without forcing teams to redesign pipelines
Just as importantly, we want AlignTune to stay open and extensible so teams can bring their own reward functions, checks, and domain validators without forking the library.