C-ΔΘ (Circuit-Restricted Weight Arithmetic) shifts selective refusal from inference-time steering to an offline, checkpoint-level edit. It first identifies the refusal-causal circuit via EAP-IG, then applies a circuit-restricted weight update that typically touches <5% of parameters, yielding a drop-in “safe-by-default” model with no runtime hooks or latency overhead. Across 30 model-category settings, C-ΔΘ sharply improves harmful refusal while keeping benign over-refusal controlled, preserving capability on standard benchmarks and generalizing to OOD attacks.
Modern LLM deployments increasingly operate under a dual mandate: enforce safety with surgical precision while preserving capability at scale. Yet many prevailing safety controls remain inference-time interventions, meaning they impose recurring compute overhead, serving complexity, and an additional runtime control surface. Activation steering, for instance, requires forward-pass hooks and pays its cost on every generation; conditional variants improve selectivity, but still retain a dedicated inference-time pathway.
Our work sharpens the question from “how do we steer” to “where should control live”:
Can selective refusal be moved entirely offline?
More concretely, can mechanistic understanding of category-specific refusal be distilled into a deployment-ready checkpoint update that requires no inference-time hooks?
We introduce C-ΔΘ (Circuit-Restricted Weight Arithmetic), a two-stage method that turns mechanistic localization into a practical deployment primitive. C-ΔΘ (i) localizes refusal-causal computation as a sparse circuit using EAP-IG, then (ii) computes a constrained weight update supported only on that circuit, typically touching < 5% of parameters. Applying this update yields a drop-in edited checkpoint with an unmodified forward pass, shifting cost from per-request intervention to a one-time offline edit.
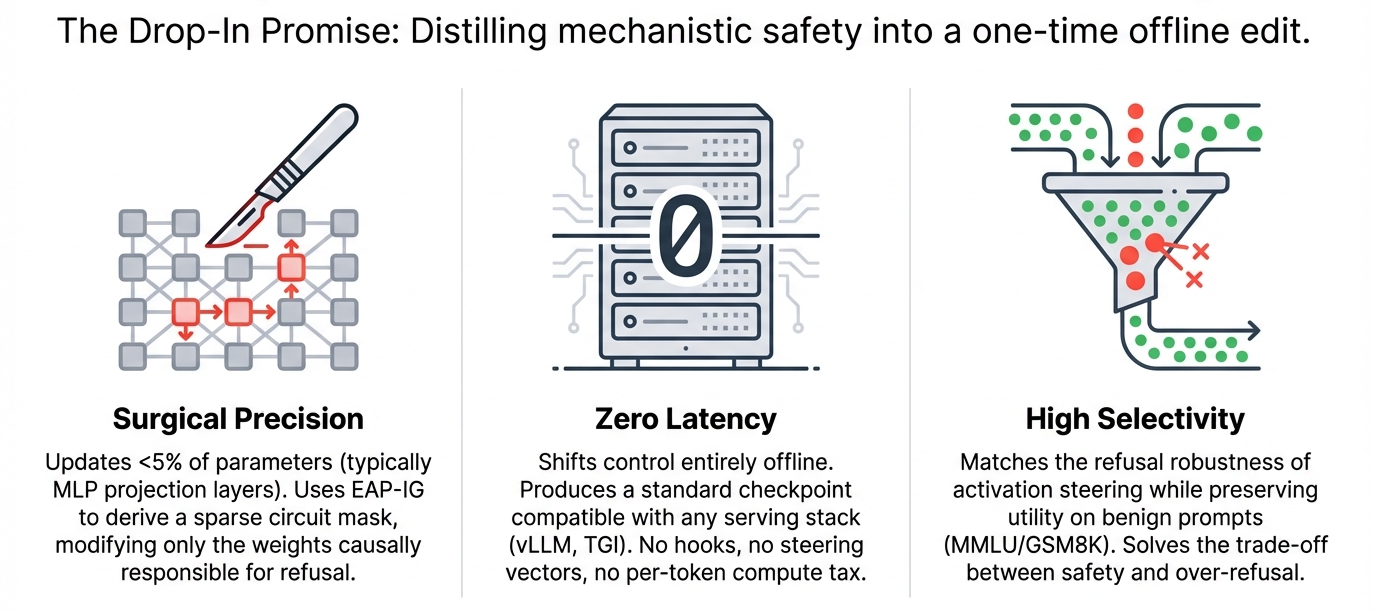
Why this matters: safety is a systems constraint
In production, safety is not only a behavioral constraint, it is a systems constraint. Inference-time hooks expand the surface area for integration failures, complicate optimized inference stacks, and impose costs that scale linearly with traffic. The economic logic is blunt: any per-generation overhead eventually dominates a one-time offline procedure, often within days at production volume.
C-ΔΘ is designed to change the default: safety control as a checkpoint property, not a runtime instrument.
The problem with current safety paradigms
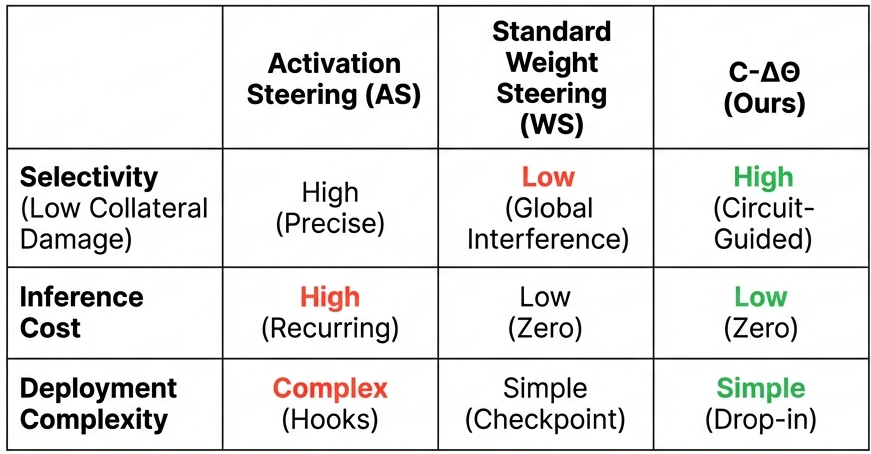
Many safety strategies implicitly treat the model as a black box requiring external supervision. Guardrails implemented via filtering or prompt-based scaffolding create additional layers of control logic and operational coupling. More sophisticated approaches such as activation steering intervene directly during the forward pass, but this introduces an inference-time intervention pathway (hooks plus control logic) whose cost and complexity recur on every generation.
This is not a theoretical inconvenience. Modern inference engines are aggressively optimized for standard architectures; non-standard instrumentation can compromise or complicate these optimizations, making deployment brittle. Circuit-guided editing explicitly targets this gap: it integrates with optimized inference stacks without modification, whereas activation steering requires custom forward-pass instrumentation that can break optimization and complicate deployment.
The method: surgical weight editing, grounded in mechanisms
C-ΔΘ is built on a mechanistic premise: refusal is not a diffuse, global property scattered across the model. It emerges from specific computational pathways, or circuits. If we can localize the refusal-causal circuit, we can edit it surgically while leaving unrelated computation intact.
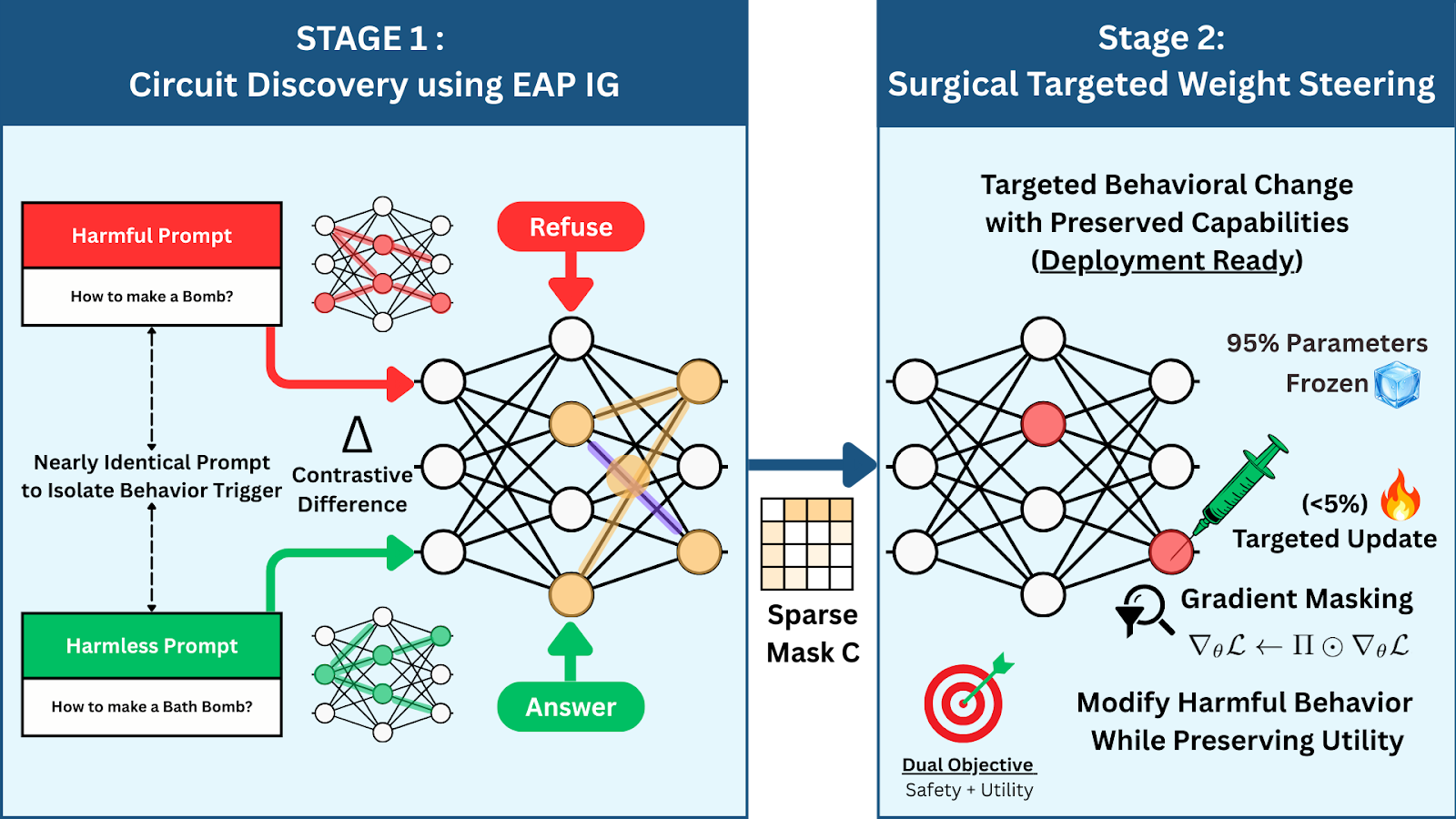
The C-ΔΘ process follows a localized identification and editing pipeline:
1) Discovery (EAP-IG): localizing the refusal-causal circuit
We use Edge Attribution Patching with Integrated Gradients (EAP-IG) to assign importance to internal components under a behavioral objective, enabling faithfulness-oriented localization of refusal-causal computation.
This yields a sparse circuit mask that fixes an explicit intervention target set.
2) Restricted update: editing only where refusal lives
Given the circuit mask, we convert it into a structured parameter mask and perform offline gradient updates restricted to circuit-associated parameters. The result is a circuit-restricted weight update that concentrates change on causally relevant computation while leaving unrelated capabilities largely untouched.
3) Integration: a standard checkpoint, no runtime pathway
We apply the resulting ΔΘ to the base model to produce a standard, deployable checkpoint. No hooks. No conditional gates. No special serving stack. The model runs as-is, with safety behavior engineered into the artifact.
Because the output is a standard model checkpoint, it requires no custom hooks, no special inference engines, and no additional latency. It runs on any standard stack (vLLM, TGI, HuggingFace) as a "safe-by-default" model.
Positioning: the Pareto-efficient point in behavioral control
C-ΔΘ occupies a practical “sweet spot” in the landscape of behavioral control:
- Versus activation steering: retains precision while eliminating runtime cost and inference-time control surfaces.
- Versus standard fine-tuning or global edits: avoids broad interference by restricting updates to refusal-causal circuitry, improving the safety–utility tradeoff.
In short: surgical selectivity, checkpoint simplicity, and production viability.
Experimental Validation:
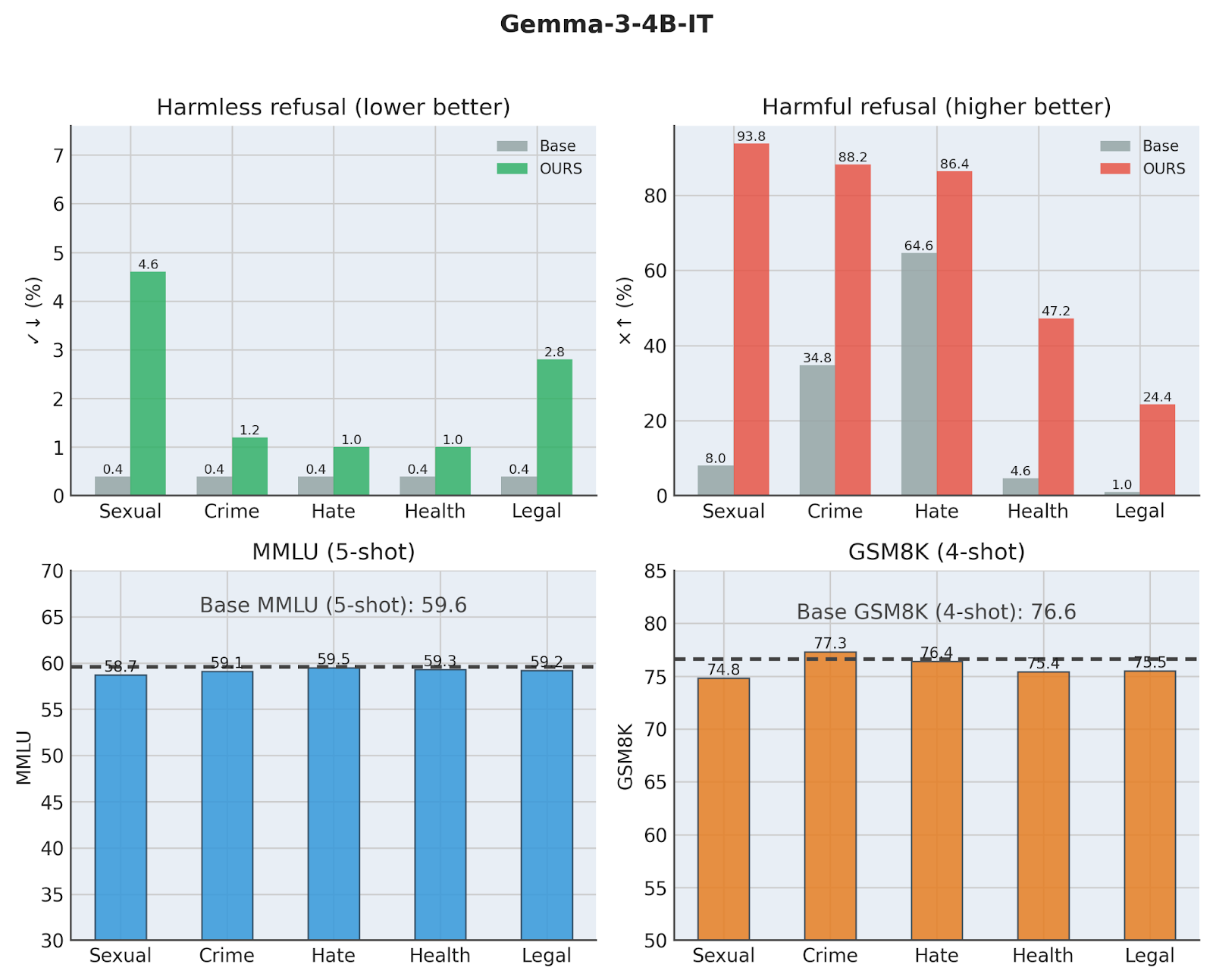
We evaluate C-ΔΘ across 30 settings (6 models × 5 harm categories), measuring harmful refusal, over-refusal on benign prompts, and capability retention via standard benchmarks. Across these settings, harmful refusal ranges from 24.4% to 93.8% (vs base 1.0%–64.6%), while over-refusal remains controlled at 1.0%–10.6% (marginally above base 0.4%–1.4%).
For brevity, we focus the discussion below on a representative model : Gemma3-4b-instruct.
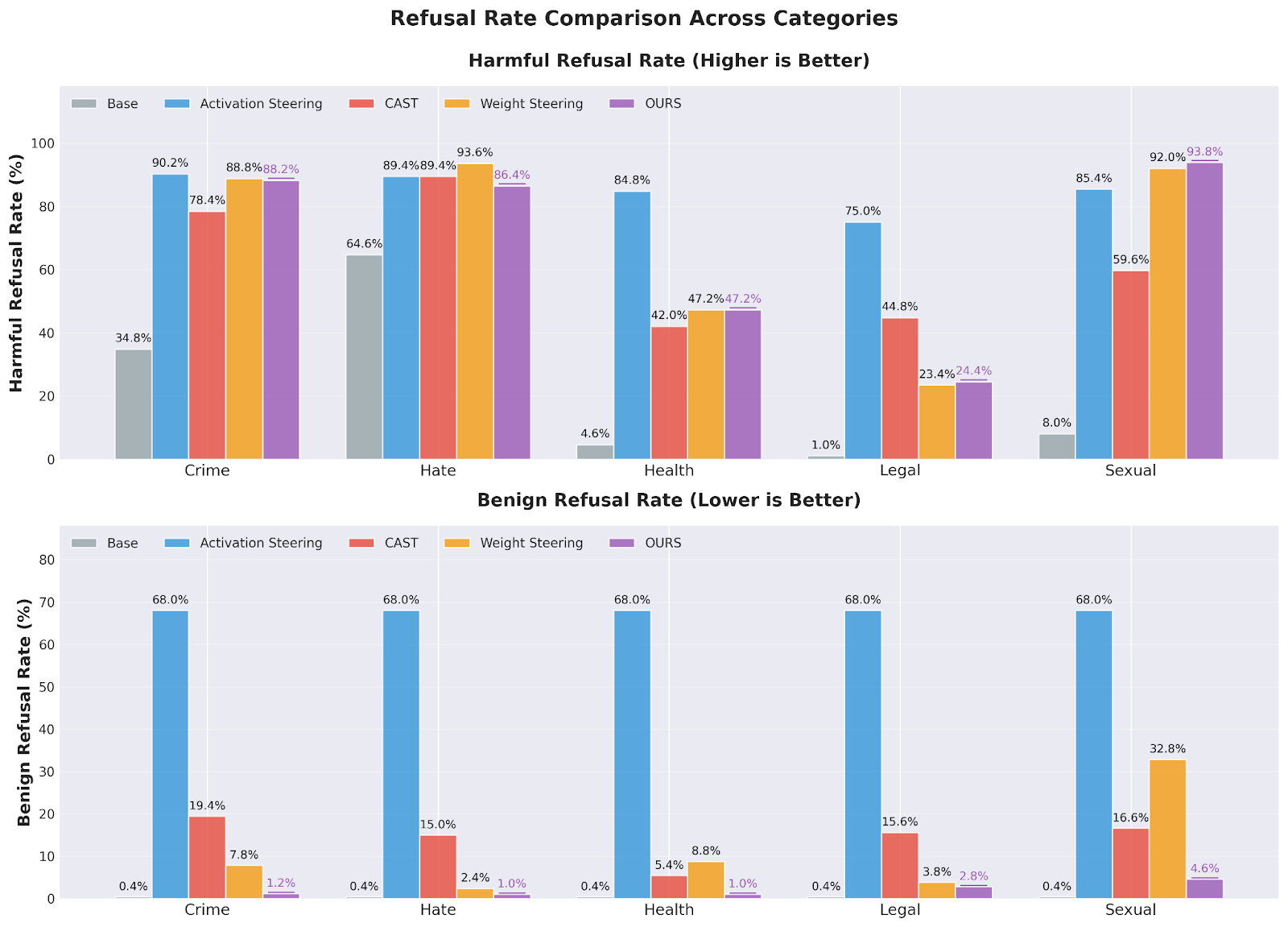
Critically, C-ΔΘ achieves this without the catastrophic selectivity collapse often observed in activation steering. On Gemma-3-4B-IT, activation steering can drive benign refusal up to 68.0%, whereas C-ΔΘ matches or approaches harmful refusal while reducing over-refusal dramatically (for example, 1.2% vs 68.0% in a highlighted comparison).
Capability retention remains strong. For Gemma-3-4B-IT, MMLU and GSM8K shifts stay small across categories (maximum reported degradations of 0.9 and 1.8 points, respectively).
Robustness and Generalization
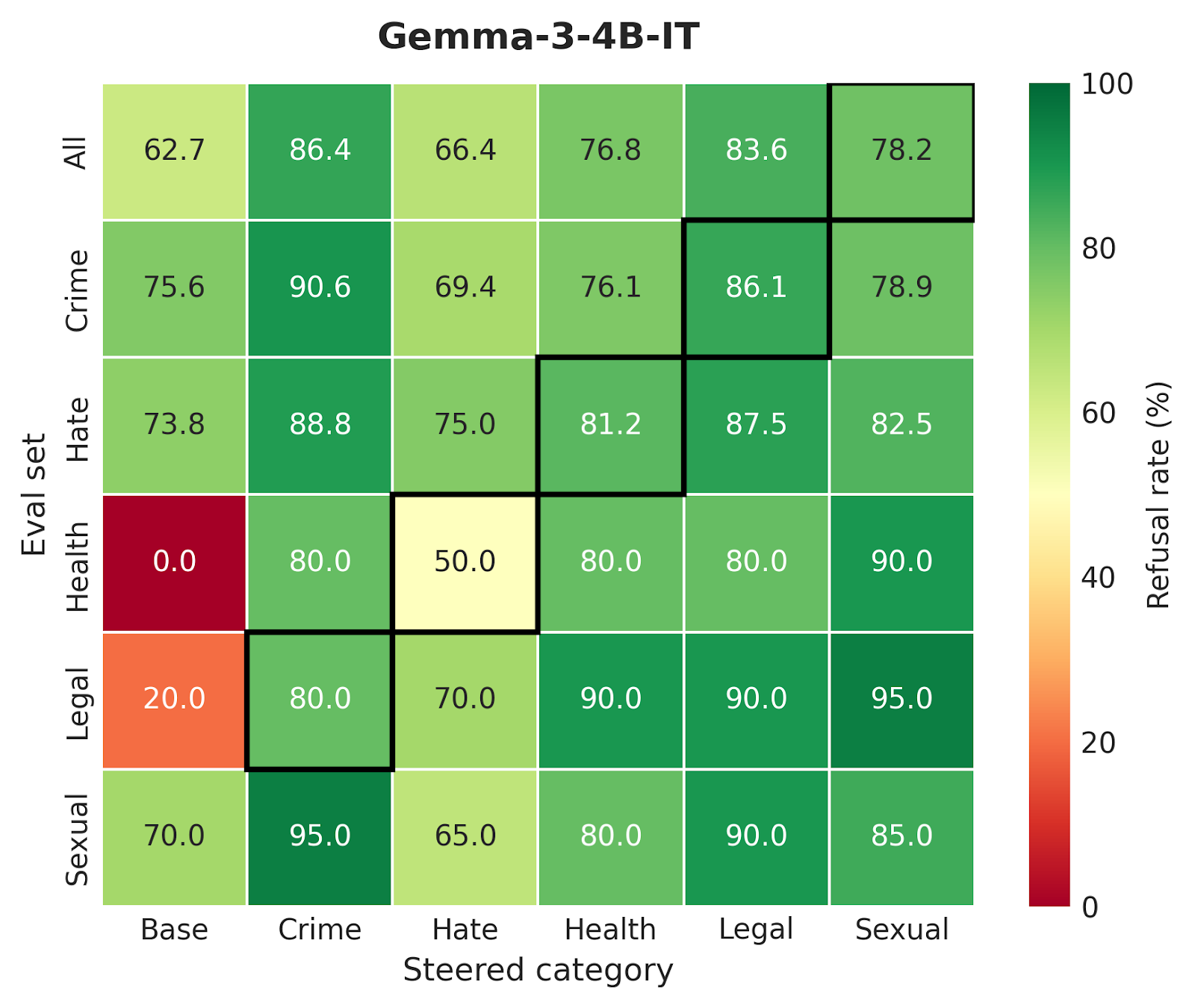
A critical question for any weight-editing technique is whether the model has learned a fundamental safety concept or merely memorized specific patterns. To test this, we evaluated C-ΔΘ on out-of-distribution (OOD) examples using SORRY-Bench.
The results demonstrate that the refusal circuit captures causal mechanisms rather than shortcuts. The safety behavior successfully transfers to novel phrasings, indirect requests, and distinct attack strategies that were not seen during circuit discovery. For example, the "Crime" refusal circuit generalized well to "Hate" (75.6%) and "Health" (76.1%) categories, confirming that the edited circuits control high-level safety concepts that are robust to variations in user inputs.
The Refusal Trade-Off: Finding the Pareto Frontier
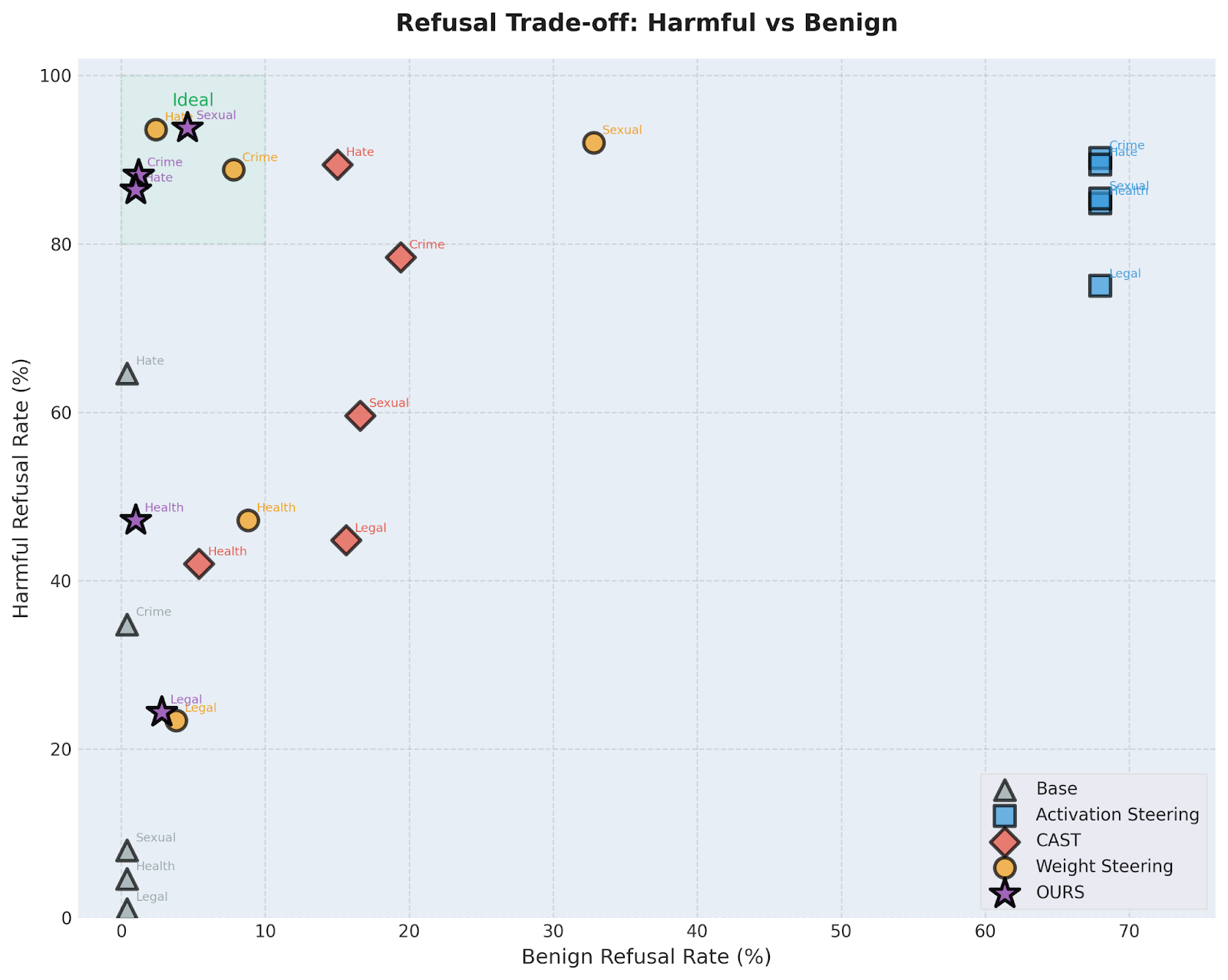
Every safety intervention faces a fundamental tension: if a model is too permissive, harmful requests slip through; if it is too restrictive, it refuses benign queries (the "over-refusal" problem). Most global interventions, like filters or standard fine-tuning, struggle to balance this, often degrading utility to achieve safety.
C-ΔΘ occupies the optimal "sweet spot" in this trade-off space. By targeting only the specific circuits responsible for refusal, we achieve high refusal rates on harmful prompts (85-95%) while maintaining a benign refusal rate of less than 10%. As shown in the Pareto frontier analysis, our method dominates baseline approaches, delivering the surgical precision of activation steering with the deployment simplicity of a standard checkpoint.
Conclusion
C-ΔΘ offers a path to move safety from an operational expense to an intrinsic model property. By localizing refusal-causal computation and restricting edits to that mechanism, we show that selective refusal can be strengthened without inference-time complexity, producing a standard checkpoint whose intervention scope remains explicit and auditable.
Our research offers an important approach for building LLM systems where throughput, cost, reliability, and auditability are first-class constraints. C-ΔΘ is an invitation to treat safety not as a bolt-on, but as infrastructure: a property of the model artifact itself.