1 Introduction
Domain fine-tuning degrades safety alignment. A medical specialist trained on patient notes will comply with pharmacology abuse questions framed as clinical queries; a finance specialist will help plan fraud once the harm is framed as a portfolio problem. System prompts offer no reliable fix: a system-prompted Llama-3.1-8B achieves 14.3% refusal, below the unprompted draft’s 16.9% (§5).
Post-generation classifiers can flag harmful outputs but cannot steer generation away from them, and RLHF/DPO retraining is undone by as few as 100 benign fine-tuning steps Qi et al. (2024). A more direct fix is to mix logits from a small, well-aligned anchor model during generation, but existing methods Xu et al. (2024); Liu et al. (2024); Li et al. (2023) require both models to share a vocabulary. This rules them out for the cross-family specialists where safety is most degraded.
Safety alignment concentrates in the first few output tokens and is fragile to domain shift Qi et al. (2025), which is why mixing only a short prefix is enough. AlignBeam is inspired by SafeDecoding Xu et al. (2024) and extends it to the cross-vocabulary setting: when the two models share a tokeniser, 𝒱d=𝒱s, LBM reduces to a construction analogous to SafeDecoding, with the difference that the support is selected via beam search rather than token-level intersection. A full comparison with LlamaGuard Inan et al. (2023), RAIN Li et al. (2024), hard-prefix priming, and recent decoding-time methods Fei et al. (2025); Huang et al. (2025); Zhang et al. (2025) is in Appendix D.
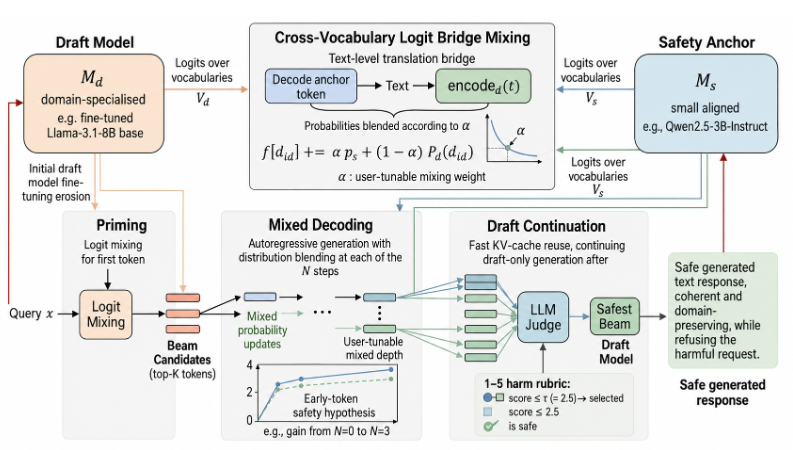
We introduce AlignBeam, a training-free method that works as follows. At each decoding step, the anchor model’s top predicted tokens are decoded to text and re-encoded in the draft model’s tokeniser, projecting the anchor’s next-token distribution into draft vocabulary space. A mixing weight α blends this translated distribution with the draft model’s own, steering early tokens toward safe completions without any shared vocabulary requirement. Three candidate continuations are scored by a small LLM judge, and the safest is returned. Mixing depth N, weight α, and beam count K are all tunable at deployment without retraining (§3).
Code will be released at https://github.com/Lexsi-Labs/alignbeam.
We evaluate across five model pairs covering three SFT-eroded domain specialists, one unaligned base model, and a same-vocabulary control, and find consistent, large gains on adversarial benchmarks with minimal accuracy cost(§5).
Contributions.
- Cross-vocabulary logit bridge mixing (LBM). A text-bridge construction (decode anchor token, re-encode under the draft tokeniser) that enables probability mixing across heterogeneous tokenisers without shared token IDs, in three multi-token fallback variants (§3).
- Three-phase beam pipeline with deployment-time knobs. Mixing depth N trades safety against speed and weight α trades safety against utility, both tunable without retraining (§3).
- Early-token safety, confirmed. Beam priming with three mixed steps (N=0→3) captures +61.9 pp of the HB+AB safety gain, after which returns diminish sharply (§5).
- Five-pair empirical validation. Medical, financial, math, and general drafts in base/instruct and same/cross-vocabulary regimes, with additional 70B-scale, LoRA-degradation, and anchor-size studies (§4).
2 Related Work
Alignment erosion under fine-tuning. As few as 100 benign fine-tuning samples can substantially reduce refusal Qi et al. (2024), and authority and domain framing provide potent soft jailbreaks against aligned models Yang et al. (2023). Domain-specialist training is far more extensive than these small-scale demonstrations, and our five-pair evaluation correspondingly observes baseline refusal rates ranging from near-zero to moderate across domains.
Inference-time safety steering. SafeDecoding Xu et al. (2024) is our closest prior work: it blends draft and safety-model probabilities at their shared vocabulary intersection and so does not apply to cross-family pairs. AlignBeam relaxes this assumption via the text bridge and additionally targets base models without chat-template conditioning; when 𝒱d=𝒱s it reduces to a construction analogous to SafeDecoding (differing in support selection: beam search vs. token-level intersection). Nudging Fei et al. (2025) performs a binary swap to a smaller aligned guide on high-entropy steps, where we instead use a continuous α-weighted blend with beam search and LLM-judge selection. Proxy Tuning Liu et al. (2024) and top-k contrastive decoding Li et al. (2023) apply the same logit arithmetic but presume a shared vocabulary; on the same-vocabulary Qwen3-8B-Base pair AlignBeam outperforms both, most sharply on contextual and Sorry-Bench categories (Appendix G.4). RAIN Li et al. (2024) self-aligns via rewindable generation but needs a safety prior in the draft to produce the signals that drive rewinding, which is exactly what domain fine-tuning removes.
Early-token safety concentration. Safety alignment concentrates in the first few token positions and is therefore brittle to prompt and decoding shifts Qi et al. (2025). Our depth ablation corroborates this directly and motivates the small mixed depths (N∈{3,6}) used throughout. A fuller treatment, covering post-hoc guard classifiers Inan et al. (2023) and recent decoding-time methods Huang et al. (2025); Zhang et al. (2025), is in Appendix D.
3 Method
Let Md be a domain-specialist draft model with vocabulary 𝒱d and Ms a small aligned safety anchor with vocabulary 𝒱s; in general 𝒱d≠𝒱s. Given a query x, we seek a response that is both safe and useful. Neither model is modified; AlignBeam runs at inference time (Figure 1).
Cross-vocabulary logit bridge mixing (LBM). Because Md and Ms use different vocabularies, token IDs cannot be mixed directly. LBM bridges them by translating the anchor’s top-B predicted tokens (we use B=50) into draft vocabulary space.
Let Ps, Pd denote the next-token distributions and 𝒯B⊂𝒱s the anchor’s top-B tokens. For each sid∈𝒯B with probability ps=Ps(sid), we decode it to a string and re-encode under the draft tokeniser: t=decodes(sid), dids=encoded(t). Whenever the result is a single draft token (|dids|=1), we accumulate it into a buffer f via
f[did]+=αps+(1−α)Pd(did), (1)
where α∈[0,1] is a deployment-time safety-utility knob: higher α steers more aggressively toward the anchor’s distribution; at α=0 the anchor contributes no logit signal, though the text-bridge mapping still executes. When the string decodes to multiple draft tokens, a variant-specific fallback applies: LBM-Drop skips them entirely, LBM-First keeps only the first sub-token, and LBM-Exact discards.
Renormalising f gives the blended distribution ~f. On same-vocabulary pairs all three variants agree (>98% single-token match); on cross-family pairs roughly 12% of anchor tokens hit the fallback. When 𝒱d=𝒱s, LBM is analogous to SafeDecoding Xu et al. (2024); the construction differs in that LBM selects support via beam search over continuations rather than by token-level top-k intersection.
We use LBM-Drop as the default: it carries the full anchor distribution at each mixed position, suppressing harmful token mass and producing standard refusal phrases. LBM-First injects only the first sub-token per step, steering the output toward safety without triggering the string-match refusal list (stealth safety; Appendix J.1).
Table 1:The three LBM variants and their multi-token fallback rules. LBM-Drop is the default, LBM-First gives stealth safety and leads on DeepSeek-Math-7B-Instruct, and LBM-Exact is a conservative ablation. On same-vocabulary pairs all three coincide (>98% single-token match).

Three-phase beam pipeline.
- Phase 1 runs both models on query x (chat template for instruct models; Q:{x}\nA: for base) and picks the top-K tokens of f~ as starting beams.
- Phase 2 extends each beam greedily for N−1 further steps under LBM, requiring O(K⋅N) paired forward passes in total.
- Phase 3 completes all K beams using Md alone with KV-cache reuse; a small LLM judge J scores each beam on a 1–5 harm rubric and returns the safest one (score≤τ=2.5).
Phase 3 is the main computational cost, so total overhead scales with K, not N. We offer two settings: K=1 (no judge, lowest overhead) and K=3 (default), both within the latency range of existing inference-time defenses (Appendix K.2).

4 Experiments
Model pairs. We evaluate five drafts ranging from 7B to 8B parameters: three domain-fine-tuned specialists where SFT degraded safety (MedLlama-3-8B, Finance-Llama3-8B, DeepSeek-Math-7B-Instruct), one unaligned base model used as reference control (Llama-3.1-8B), and one same-vocabulary control (Qwen3-8B-Base, which shares a tokeniser with the anchor). DeepSeek-Math-7B-Instruct uses N=20 rather than the default N=6: at N=6 it produces a refusal prefix and then continues with the harmful answer, so a longer mixing window is needed (Appendix J.1). The safety anchor is Qwen2.5-3B-Instruct, fixed across all pairs (Table 2).
Table 2:The five draft/anchor pairs in our evaluation. The safety anchor is Qwen2.5-3B-Instruct for every pair. Defaults: α=0.5, K=3 (safety) / K=1 (utility), seed 42. DeepSeek-Math-7B-Instruct uses N=20 to suppress a refuse-then-comply pattern seen at N=6; Qwen3-8B-Base is the only same-vocabulary pair.
Datasets. We use five complementary evaluation axes (sample counts in parentheses). Safety: HarmBench-Standard (167) Mazeika et al. (2024), HarmBench-Contextual (62), AdvBench (520) Zou et al. (2023), Sorry-Bench (440) Xie et al. (2025), WildJailbreak-Eval-Harmful (1,105–1,315) Jiang et al. (2024). Calibration (benign): XSTest (450) Röttger et al. (2024), OR-Bench-Hard (855) Cui et al. (2025), JBB-Benign (100) Chao et al. (2024). Utility: GSM8K Cobbe et al. (2021) for DeepSeek-Math-7B-Instruct, MedQA Jin et al. (2021) for MedLlama-3-8B. HarmBench-Contextual and WildJailbreak probe domain-framed and multi-sentence attacks respectively; calibration sets measure benign over-refusal. Supplementary harmful sets (JailbreakBench-Harmful Chao et al. (2024)) are reported only in the appendix.
Hyperparameters and judging. All runs use: N=6 (DeepSeek-Math: 20), K=3 for safety benchmarks and K=1 for utility, α=0.5, judge threshold τ=2.5, temperature T=0.7, bridge width B=50, repetition penalty 1.15, seed 42. Each benchmark is scored by its own official judge (Appendix E). All numbers reported in the paper are string-match refusal rates, a conservative primary metric whose rationale is in Appendix C. The LLM judge in Phase 3 is used only to pick between beams during generation; it never scores the results reported here, avoiding any self-evaluation circularity (full per-benchmark setup in Appendix E).
Why string-match refusal is conservative. Base models sometimes emit incoherent or repetitive text on adversarial prompts, which official judges correctly score as non-harmful; this inflates the apparent baseline (on Llama-3.1-8B, string-match refusal is 16.9% against 49.1% judge accuracy, a ≈32 pp gap from degenerate outputs counted “safe”). AlignBeam’s outputs are non-degenerate by construction, since the judge filters incoherent beams, so the gap between Base and AlignBeam under string-match is a lower bound on the true safety gain. We report string-match refusal as the primary metric and benchmark-judge accuracy as secondary; the full analysis is in Appendix C.
5 Results
5.1 Headline Results
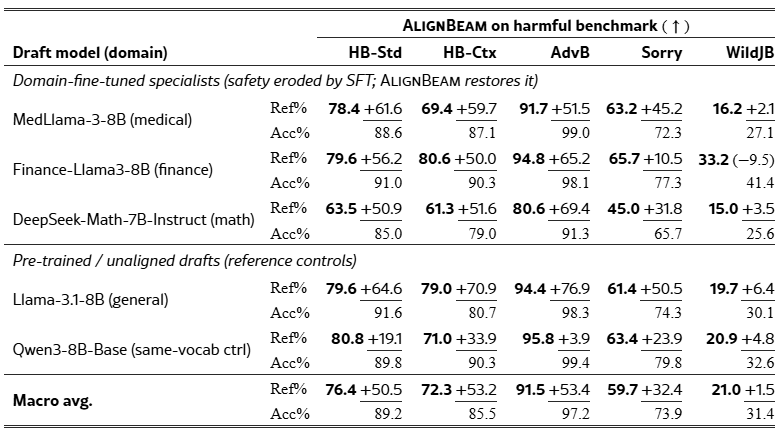
Across five pairs, AlignBeam raises string-match refusal on AdvBench from 38.1% to 91.5% (+53.4 pp macro avg.) and on HarmBench-Std from 25.9% to 76.4% (+50.5 pp macro avg.) (Table 3; both share the HarmBench-Mistral judge). Four pairs reach 91–96% on AdvBench and 78–81% on HarmBench-Std; DeepSeek-Math-7B-Instruct gains +64.9 pp, bringing the macro average to 76.4% (median 79.6%). Benign over-refusal (refusal on non-adversarial prompts; lower is better) rises across all pairs as the anchor’s tendency to refuse carries over (Llama-3.1-8B: OR-H 11.0%→22.3%, XSTest 5.6%→40.0%; per-pair details in Appendix G.1). Task utility falls by −0.4 pp on both GSM8K and MedQA (Appendix K.1).
Table 3:AlignBeam raises string-match refusal by +35–74 pp on cross-vocabulary pairs and holds benign over-refusal within the LlamaGuard band. Ref% = string-match refusal (bold, primary); Acc% = benchmark-judge accuracy (secondary); underlined = improvement over the unmodified draft. Config: LBM-Drop, α=0.5, N=6 (DeepSeek-Math: N=20), K=3, seed 42. Full Base/AlignBeam grid in Appendix B.
5.2 Early-Token Safety and the Depth/Weight Trade-off
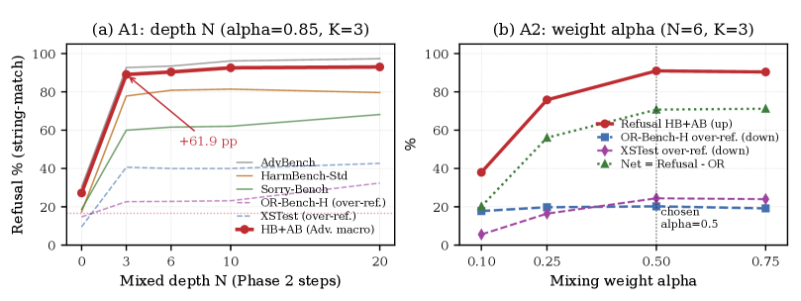
The depth ablation (Llama-3.1-8B, α=0.85, K=3) confirms that safety is concentrated in early tokens Qi et al. (2025): beam priming alone (N=0) lifts AdvBench refusal from 17.5% to 30.4%, the first three mixed steps add +62.3 pp (reaching 92.7%), and going deeper than N=6 adds only ≈3.9 pp more on HB+AB (Figure 2(a)). The weight ablation (N=6, K=3) shows refusal saturating by α=0.50 (AdvBench 94.4%, HarmBench-Std 80.2%) while OR-Bench-Hard over-refusal stays flat at ≈20% across all α (§Limitations). The α knob thus controls where on the refusal/over-refusal curve to operate (Figure 2(b)). We use α=0.50, N=6 as defaults; full sweeps are in Appendices I.1–I.2.
5.3 Beam Count K
K is set once at deployment. K=1 (no judge, lowest cost) captures ∼80% of the safety gain at roughly 2× overhead, comparable to hard-prefix priming. K=3 (default, with LLM judge) recovers the remaining gain at ∼5× overhead. Per-pair latency breakdowns are in Appendix K.2.
5.4 Anchor Alignment vs. Beam Search
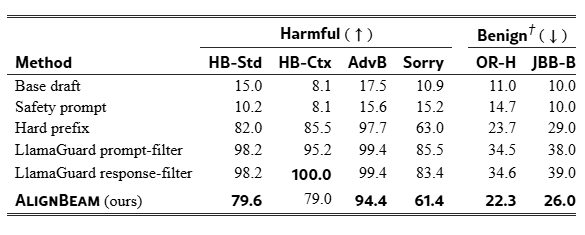
On Llama-3.1-8B, beam search and anchor alignment each contribute roughly half the safety gain. Replacing the aligned anchor with its unaligned base counterpart leaves ∼25–52 pp refusal from beam search alone; swapping back to the aligned version adds another +25 pp for free (Figure 3). A separate anchor-size sweep (Qwen2.5-7B-Base draft) shows that alignment quality matters more than model size: a 0.5B aligned anchor reaches 80.2% HB-Std judge accuracy versus 98.2% for the 7B anchor, with the gap driven by calibration rather than parameter count (Appendix J.5).
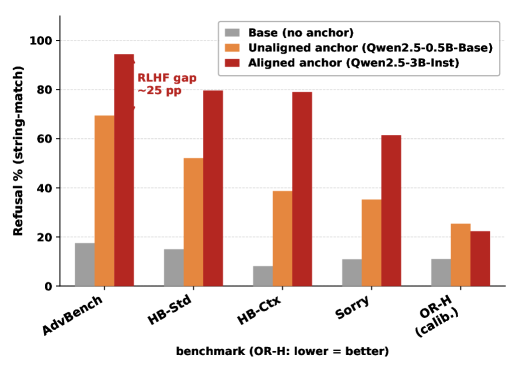
Table 4:AlignBeam matches LlamaGuard on adversarial safety (78–94% refusal) while keeping benign over-refusal below 27% vs. LlamaGuard’s 34–39%. String-match refusal%; harmful: ↑; †benign / calibration (over-refusal): ↓. All rows: same Llama-3.1-8B draft. Hard-prefix at K=1; AlignBeam at K=3.
5.5 Comparison to Baselines
LlamaGuard filters reach near-ceiling on adversarial benchmarks but push benign over-refusal to ≈34.5% on OR-Bench-Hard and 38–39% on JBB-Benign. AlignBeam achieves 79.6% HarmBench-Std and 94.4% AdvBench refusal while keeping OR-Bench-Hard at 22.3% and JBB-Benign at 26.0%, a substantially better safety/over-refusal balance (Table 4; Appendix H.2). The safety-prompt baseline is actively counterproductive: 14.3% refusal, below the unprompted draft’s 16.9%. On the same-vocabulary Qwen3-8B-Base pair, AlignBeam beats both Proxy Tuning Liu et al. (2024) and top-k contrastive decoding Li et al. (2023) on five of six adversarial benchmarks, with the widest gap on contextual attacks (Appendix G.4); results hold at 70B scale (Llama-3.1-70B, Appendix J.3).
5.6 Robustness
Results are stable across seeds {42, 2, 3} (±0.7 pp HB+AB; Appendix J.2.1) and across different Phase 1 prompt formats (Appendix I.3.2). Dropping the LLM judge altogether (K=1, Appendix J.2.2) leaves adversarial refusal unchanged or slightly higher; the only cost is +6.4 pp XSTest over-refusal, confirming that logit mixing provides the safety signal and the judge’s role is primarily to reduce over-refusal on benign inputs. Full ablations and per-pair breakdowns are in the appendix.
5.7 Task Utility
Under AlignBeam’s K=1 utility mode, task accuracy drops by −0.4 pp on both domain pairs: GSM8K (DeepSeek-Math-7B-Instruct) 77.0% → 76.6% and MedQA (MedLlama-3-8B) 13.1% → 12.7%. Full per-strategy MedQA similarity metrics (ROUGE-1/2, BERTScore-F1, SentSim; all within ±1.5 pp) are in Appendix K.1.1.
6 Conclusion
Safety alignment is not an intrinsic property of a model’s weights: it can be loaned at inference time from a separately maintained anchor, decoupling safe deployment from the fine-tuning pipeline. AlignBeam instantiates this principle via a cross-vocabulary text bridge, recovering near-complete AdvBench refusal on cross-vocabulary specialist pairs and substantially lifting count-weighted HB+AB refusal, while holding task accuracy within a fraction of a percentage point and fitting within the latency band of existing defenses. Immediate extensions include multi-anchor ensembles, adaptive-prefix decoding, and a benign-prompt calibration head to reduce over-refusal.
Limitations
Compute overhead. Inference cost is comparable to other inference-time defenses (LlamaGuard, Proxy Tuning, hard-prefix, RAIN); K and N are deployment-adjustable without retraining (Appendix K.2).
Calibration ceiling. Both safety limits stem from the anchor, not the mixing parameters: the anchor’s over-refusal on ambiguous benign prompts is inherited (OR-Bench-H ≈20%, XSTest ≈40% on Llama-3.1-8B), and the mixed prefix covers only the first N tokens, so attacks that embed harm past the prefix are only partially blocked (WildJailbreak-H: +2–6 pp vs. +51–77 pp on AdvBench). A better-calibrated anchor, longer prefix, or per-prompt α schedule could close the gap.
Evaluation scope. All prompts are single-turn and ≤200 tokens; multi-turn jailbreaks and adaptive attacks are out of scope. Experiments use a single Qwen2.5-3B-Instruct anchor; the alternative-anchor study (Appendix I.3.3) shows results depend on anchor refusal style. Multi-anchor ensembles, multilingual evaluation, and human judging are natural next steps. Truncation and “sorry-but-continues” artefacts that affect verbose drafts and understate true safety are discussed in Appendix L.
Ethics Statement
AlignBeam is designed to reduce harmful outputs from domain-fine-tuned language models. Because it raises refusal rates rather than suppressing them, direct misuse is limited, though the method relies on a well-aligned anchor: a misaligned one could itself steer generation toward harm. The main benefit is allowing organisations to deploy specialised models without compromising their safety. Inference overhead can be adjusted via K and N to fit a deployment budget (Appendix K.2); all experiments ran on a single RTX 6000 Pro Blackwell (96 GB, bfloat16). All evaluation is automated and English-only.
arxiv Link: https://arxiv.org/abs/2606.12342