1 Introduction
Machine unlearning has become a safety-critical capability for deployed language models: hazardous-knowledge memorisation (biosecurity, cyberweapons, chemical synthesis) makes it necessary (Li et al., 2024), and right-to-erasure regulations (EU AI Act, GDPR) make it legally required (Jang et al., 2023). Yet every deployed LLM today is quantized 4-bit formats (NF4, GPTQ, AWQ) reduce memory by 4× and inference cost by 2–3×, making quantization the standard final step before release. (Zhang et al., 2025) (ICLR 2025) documented that 4-bit PTQ can reverse machine unlearning, reporting up to 83% recovery and proposing a saliency-based mitigation (PTQ-LR/SURE); standard evaluation practice has not yet caught up the field’s default protocol remains behavioral metrics in full precision on a held-out forget set, measured immediately after training. We trace the reversal phenomenon to a structural cause (per-parameter updates systematically fall below the NF4 bin width) and propose a method that addresses it by construction. The assumption the standard protocol embeds behavioral suppression in BF16 is an adequate proxy for durable knowledge removal is false, and the failure is systematic.
The dual failure mode: We apply six representative methods to Llama-3.1-8B-Instruct on WMDP-bio (Li et al., 2024) and confirm that gradient-based methods achieve meaningful forget-set suppression in BF16. We then apply NF4 4-bit post-training quantization (the compression scheme used by the overwhelming majority of real-world LLM deployments) and re-evaluate. In every gradient-based method, the forgotten knowledge returns, with PTQ recovery gaps of +0.06 to +0.07. Methods that survive quantization do so only by barely changing the model: across 94 non-Mansu experiments (Table 9), preference-optimization and null-space methods reduce forget-set accuracy by 1.6 pp on average, within measurement variance on a four-way MCQ task. The pattern holds on Qwen-3-8B and on MUSE open-ended memorization, ruling out model- or benchmark-specific explanations.
The structural cause: Both failure modes share one origin. Every existing method distributes gradient updates across all d parameters. For Llama-3.1-8B (d≈8×109), even a large-norm gradient induces per-parameter changes of order 10−6, far below the NF4 quantization bin width of ≈8.4×10−4. At compression time, these changes round to zero. Methods that avoid this by constraining updates to remain near the original model do so at the cost of meaningful forgetting. This is not a hyperparameter problem; it is a necessary consequence of applying any gradient-based objective uniformly across billions of parameters (Proposition 1).
The fix: Mechanistic interpretability has established that specific factual knowledge is causally localized in sparse, identifiable subgraphs of the model’s computation (Meng et al., 2022; Elhage et al., 2022; Syed et al., 2024). If knowledge resides in |𝒞| parameters rather than all d, concentrating updates into 𝒞 amplifies per-parameter magnitudes by d/|𝒞|. With an explicit magnitude floor, quantization survival becomes a construction-time guarantee. Null-space projection restricted to 𝒞 yields a retain-set loss bound provably tighter than global projection by the Cauchy interlace theorem.
We present Mansu (Mechanistic-Aligned Null-Space Unlearning), which operationalizes this insight: (1) EAP-IG (Hanna et al., 2024) identifies the minimal circuit 𝒞 causally responsible for forget-set answers; (2) gradient updates within 𝒞 are projected into the null space of the retain-set Fisher Information, with a tighter bound proved in Theorem 1; and (3) every cumulative update below the NF4 bin size is rescaled to the floor, guaranteeing quantization survival by construction (Lemma 1). On Llama-3.1-8B-Instruct / WMDP-bio, Mansu achieves a PTQ gap of −0.040 while preserving MMLU within 0.030 of the zero-shot model: NF4 amplifies rather than reverses the erasure (Proposition 2). Results replicate on Qwen-3-8B and MUSE.
Contributions: (I) Dual failure documentation: the first systematic evidence that no existing method achieves both meaningful forgetting and quantization permanence, across 94 non-Mansu experiments (84 WMDP cells from the family-wise sweep in Table 9 plus 10 MUSE cells in Table 2) over three model families, three hazard domains, and two benchmarks. (II) Mansu: a three-component method with formal guarantees, tighter retain bound (Theorem 1), construction-time quantization survival (Lemma 1), and a sparsity-permanence tradeoff analysis (Proposition 1); full proofs in Appendix C. (III) Circuit Attribution Divergence (CAD): the first post-hoc mechanistic verification protocol distinguishing structural knowledge deletion from behavioral suppression, a distinction standard behavioral metrics cannot make (Section 4.1).
2 Background and Related Work
Table 1: Prior work against the four unlearning requirements (Section 3). F = forget; R = retain; Q = quant.-permanent (ΔPTQ≤0); S = structural erasure (CAD ≫0). ✓ satisfies; ✗ fails; ∼ partial. Methods(†) are evaluated in our experiments.
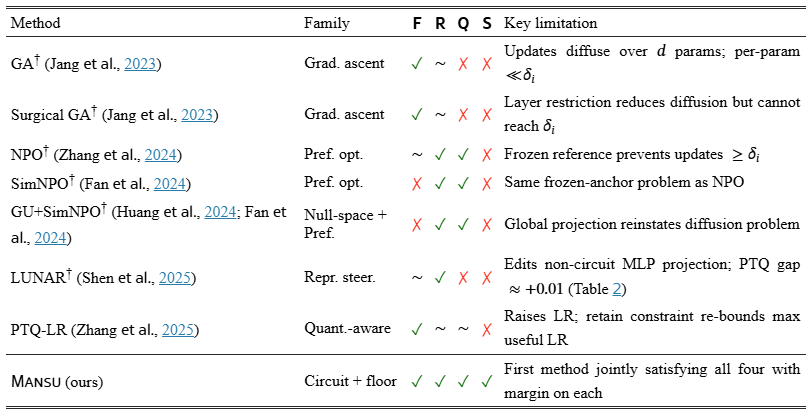
Machine unlearning methods can be grouped into five method families (gradient ascent, preference optimization, null-space projection, representation steering, quantization-aware optimization); Table 1 summarizes each against the four requirements of Section 3.
Gradient ascent and variants (Jang et al., 2023; Liu et al., 2022) maximize forget-set loss directly. These methods are simple and effective in full precision, but updates distribute over all d parameters, pushing per-parameter magnitudes far below quantization bin widths. Surgical variants (Jang et al., 2023) reduce the active parameter count but cannot reach the bin threshold without violating the retain constraint (Proposition 1).
Preference optimization (NPO (Zhang et al., 2024), SimNPO (Fan et al., 2024)) adapts DPO (Rafailov et al., 2023) to treat forget-set responses as dis-preferred. The frozen reference model prevents output collapse and incidentally prevents large per-parameter updates, giving good retain scores but negligible structural change. TOFU (Maini et al., 2024) and MUSE (Shi et al., 2025) are benchmark suites for preference-optimized unlearning, on fictitious-author facts and open-ended memorization respectively; we evaluate on MUSE alongside the WMDP hazard splits.
Null-space projection (GU, Huang et al., 2024) projects gradient updates onto the null space of the retain Hessian, giving a formal retain-safety bound. Because the projection is global, the diffusion problem is reinstated. Mansu inherits the projection idea and proves a strictly tighter bound by restricting both the update and the projection to the causally identified circuit (Theorem 1).
Representation steering (LUNAR (Shen et al., 2025), RMU (Li et al., 2024)) suppresses forget-set outputs by redirecting activations at inference time. LUNAR trains only a single MLP down-projection outside the EAP-IG forget circuit; RMU randomises forget-set activations without weight edits. In both cases the causal knowledge circuit is left intact, so the unlearned model passes behavioural metrics while CAD remains ≈0 the failure mode CAD is designed to expose. We include LUNAR in our experiments and discuss RMU as a methodologically adjacent baseline.
Quantization robustness: (Zhang et al., 2025) (ICLR 2025) document that 4-bit PTQ can catastrophically reverse unlearning, reporting up to 83% recovery and proposing a saliency-based unlearning strategy with a large learning rate (“PTQ-LR” in Table 1) as mitigation. We show (Proposition 1) that the retain constraint independently caps the useful learning rate, so the root cause remains unaddressed. Our magnitude-floor constraint solves the problem at its source.
Mechanistic interpretability and knowledge localization: ROME (Meng et al., 2022) and MEMIT (Meng et al., 2023) established via causal patching that factual associations are stored in middle MLP layers; EAP-IG (Hanna et al., 2024) extends this to circuit-level attribution across the full computation graph. Concurrently, (Kasliwal et al., 2026) apply circuit-restricted weight arithmetic to embed refusal directly into checkpoints without inference-time hooks. Our work applies the same localization principle to unlearning and adds the orthogonal constraint of quantization permanence, which that setting does not require. (Lee et al., 2025) and (Guo et al., 2025) raise concerns that attribution-based circuits do not reliably predict unlearning targets; Ablation C(i) tests this claim directly on the factual-recall benchmarks studied here and finds a substantial CAD advantage (1.143 vs 0.743) for the causally identified circuit over a random same-size baseline at matched forget depth. Extended discussion is in Appendix A.
3 Problem Formulation
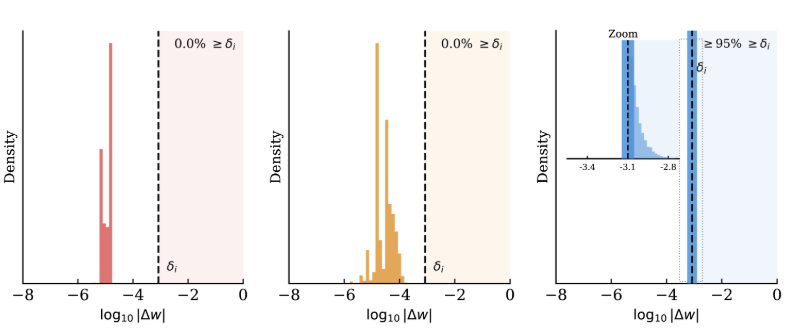
Figure 1: Per-parameter update magnitudes (Llama-3.1-8B / WMDP-bio). Histograms of log10|Δw|. (a) Global GA: diffuse, far below δi. (b) Surgical GA: concentrated on L14–16, still below δi. (c) Mansu: clamped at or above δi by construction. Dashed line: NF4 bin width δi=8.4×10−4; updates to its left round to zero under 4-bit quantization, so only Mansu’s erasure survives (Lemma 1).
Let θ∈ℝd be a pretrained LM’s parameters, 𝒟f the forget set, 𝒟r the retain set.
We seek Δθ with θ′=θ+Δθ satisfying four properties: (i) forget: θ′ fails on 𝒟f by a meaningful margin; (ii) retain: performance on 𝒟r and general benchmarks within 2 pp of θ; (iii) quantization permanence: Q4(θ′) also fails on 𝒟f, where Q4 is the deployment 4-bit quantizer; (iv) structural erasure: re-running causal attribution on θ′ shows the subgraph implementing forget-set knowledge has collapsed, not merely been bypassed. Properties (i) and (ii) are standard; (iii) and (iv) are not, and no existing method satisfies both.
Definition 1 (NF4 quantization floor).
Under NF4 quantization (Dettmers et al., 2023) with per-channel scale si and codebook levels {qk}15k=0, the smallest bin width for parameter i is δi=si⋅mink|qk−qk−1|. For Llama-3.1-8B MLP weights δi≈8.4×10−4 (derivation in Appendix D).
Proposition 1 (Sparsity–permanence tradeoff).
Under gradient ascent with retain constraint ℒr(θ+Δθ)−ℒr(θ)≤ϵr, the per-parameter update magnitude when |𝒞| parameters are updated (all others frozen) satisfies
‖Δθi‖≤2ϵr/ |𝒞|F¯𝒞, F¯𝒞=1/ |𝒞|∑j∈𝒞[𝐅r]jj,
where [𝐅r]jj=𝔼(x,y)∼𝒟r[(∂logpθ(y|x)/∂θj)2] is the empirical diagonal Fisher of the retain loss (Appendix C; the diagonal Fisher remains well-defined under rank-deficient 𝐇r, unlike the standard σmin form). For Llama-3.1-8B (d=8.03×109, ϵr=0.02, F¯𝒞∼100), the global case (|𝒞|=d) gives ‖Δθi‖≲2.2×10−6, roughly 380× below δi. Updates reach δi only when |𝒞|/d≤7×10−6 (fewer than 0.001% of parameters).
Implications. First, no existing gradient-based method operates near this threshold: Surgical GA’s 6.6% circuit and even Mansu’s 3.2% both sit more than three orders of magnitude above it (≈4500× for Mansu, ≈9400× for Surgical GA; cf. Surgical GA’s +0.027 PTQ gap, Table 2), so localization alone is insufficient and the magnitude floor (Section 4) is required to close the gap by construction. Second, Proposition 1 says nothing about which parameters to update: arbitrary concentration damages retain performance, so the circuit must be chosen causally.
Second failure mode. Preference-optimization methods (NPO, SimNPO, GU+SimNPO) avoid the floor problem differently: the frozen-reference KL constrains updates to be so small that |Δθi|≪δi almost everywhere. At standard hyperparameters this leaves forget accuracy largely intact across our 94-experiment sweep, the mean forget-set reduction for these methods is 1.6 pp on capable models (behaviorally invisible erasure). Pushing the methods harder (as in our main-table runs on Llama-3.1-8B) does move forget accuracy, but diffuses the now-larger update across d parameters: forget drops (0.230–0.250) come paired with collapsed MMLU (0.200–0.295) targeted erasure is replaced by global utility damage (Section 6).

Figure 2:Mansu three-phase pipeline.Phase 1 (Localize): EAP-IG causal attribution identifies the minimal MLP circuit 𝒞 causally responsible for forget-set answers. Phase 2 (Project): Updates restricted to 𝒞 are projected into the null space of the circuit-restricted retain Fisher 𝐅𝒞 (Theorem 1). Phase 3 (Floor): A per-parameter magnitude floor δi rescales each update to clear the nearest NF4 bin boundary by construction (Lemma 1).
4 Method
Both failure modes share a root cause: gradient updates distributed over parameters with no causal role in the targeted knowledge. Mansu corrects this in three phases (Figure 2; full procedure in Algorithm 1); derivations are in Appendix B.
Phase 1: Localize (Appendix E). EAP-IG (Hanna et al., 2024) runs path-integrated gradients on the logit difference between clean and corrupted forget-set prompts, attributing causal contribution to each edge of the transformer graph. Aggregating over 50 forget examples and ranking MLP sublayers by total incoming attribution mass yields the top-10 circuit:
𝒞MLP={30,14,31,19,29,15,20,16,21,17},
covering ≈3.2% of parameters (effective post-Phase-2/3 fraction; per-stage breakdown in Appendix B.3). The top-5 prefix {30,14,31,19,29} is the canonical k=5 configuration used in Tables 10 and 12. Layer 14 appears in both the EAP-IG top-K circuit and surgical GA’s L14–16 selection, providing partial cross-method agreement; upper layers {29,30,31} dominate the attribution ranking, consistent with ROME’s finding that later MLP layers store factual associations (Meng et al., 2022).
Phase 2: Project (Appendix B). Gradient updates within 𝒞 are masked along high-Fisher coordinates, an approximation to projection into ker(𝐇𝒞𝒞) under the diagonal-Fisher assumption (approximation error bounded in Proposition 3):
[P𝒞g]i=gi⋅𝟙[[𝐅𝒞]ii≤τ], i∈𝒞; Δθ𝒞¯=0,
where τ is the 99th-percentile Fisher threshold and all parameters outside 𝒞 are frozen. Restricting projection to 𝒞 yields a provably tighter retain bound than projecting globally (Theorem 1).
Phase 3: Floor (Appendix D). After training converges (best checkpoint by lowest forget accuracy subject to MMLU drop ≤0.08), the magnitude floor is applied post-hoc to the saved checkpoint: for each i∈𝒞, the cumulative update Δθi=θi−θi(0) is rescaled to clear the nearest NF4 bin boundary while preserving direction:
Δθi←Δθi⋅ δi / |Δθi| whenever 0<|Δθi|<δi, i∈𝒞.(4)
By Lemma 1 this guarantees Q4(θi(0)+Δθi)≠Q4(θi(0)) for every i∈𝒞, so the update is permanent under quantization. The implementation uses a per-tensor approximation of δi that agrees with Definition 1 to within an order of magnitude (Appendix B.3).
Training objective. The three constraints are encoded jointly:
minΔθ𝒞∈P𝒞(ℝ|𝒞|)|Δθi|≥δi∀i∈𝒞Δθ𝒞¯=0 −ℒf(θ+Δθ)+λDKL(pθ(0)∥pθ+Δθ)x∼𝒟r.
The frozen-reference KL (following NPO/GU) prevents retain collapse. Hyperparameters and the rationale for full-parameter (not LoRA) training are in Appendix B.
4.1 Circuit Attribution Divergence (CAD)
Motivation. Two unlearned checkpoints with identical forget-set accuracy can differ in mechanism: in θA′ the knowledge circuit has been dismantled; in θB′ the circuit is intact and a downstream layer redirects its output to a refusal token (LUNAR-style). Both pass behavioral evaluations, but θB′ is fragile to small fine-tunes, re-prompts, or quantization. Behavioral metrics measure outputs; unlearning is a claim about weights.
Definition. Let E(𝒞) be the EAP-IG edge set on the original θ with attribution score se(θ) for edge e (Appendix E). Re-run EAP-IG on the unlearned θ′ and compare:
CAD(𝒞,𝒟f;θ,θ′)=∑e∈E(𝒞)|se(θ)−se(θ′)| / ∑e∈E(𝒞)|se(θ)|
CAD→0 means the circuit is intact (behavior may have changed only via downstream redirection); CAD≈1 means it has been dismantled; values >1 indicate sign-flipped redirection (also structural).
Properties. CAD is (i) computed entirely on the unlearned weights with no held-out probes; (ii) ≈0 by construction for inference-time redirection (LUNAR/RMU); (iii) insensitive to spurious behavioral suppression (a refuse-everything model yields CAD≈0); (iv) not satisfied by random weight perturbation the random-circuit control (Ablation C(i)) collapses CAD by ∼35% relative to the EAP-IG circuit (1.143→0.743 on WMDP-bio); (v) CAD alone does not certify structural erasure high CAD with elevated AS-NC indicates broad representational damage rather than localized circuit dismantling. The joint diagnostic is high CAD and low AS-NC (companion metric below); a worked SimNPO/MUSE example illustrating this distinction is in Appendix N.
Companion metrics: AS-C, AS-NC. Activation-level checks inside / outside 𝒞 (Eq. 11). Structural erasure requires high CAD and the concentration gap AS-C ≪ CAD, which is present only for localized methods; for global baselines AS-C = CAD numerically (Table 3). Full diagnostic discussion is in Appendix N.

5 Theoretical Analysis
Mansu rests on three guarantees: retain safety, quantization permanence, and amplification. Full proofs and error bounds are in Appendix C.
Theorem 1 (Circuit-restricted projection tightens the retain bound).
Let ℒr be twice continuously differentiable with PSD Hessian 𝐇. For 𝒞⊆[d], 𝒞¯=[d]∖𝒞, and any Δθ with Δθ𝒞∈ker(𝐇𝒞𝒞), Δθ𝒞¯=0, ‖Δθ‖≤ε:
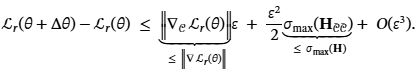
Each bracketed term is at most its global counterpart: the gradient inequality is the sub-vector L2 bound, and σmax(𝐇𝒞¯𝒞¯)≤σmax(𝐇) is Cauchy interlace (Horn and Johnson, 2012). The circuit-restricted bound is strictly tighter than global null-space projection (Huang et al., 2024) whenever 𝐇’s dominant eigenvector projects non-trivially onto 𝒞-coordinates. Since 𝒞 is chosen by causal attribution on 𝒟f (not 𝒟r), this holds generically; Ablation D (global projection + floor) verifies it empirically. The diagonal-Fisher approximation used in Phase 2 incurs additional error O(σmax(𝐇)‖E𝒞‖op/τ) where E𝒞 is the off-diagonal Fisher block (Appendix C).
Lemma 1 (Quantization survival).
Let Q4 be 4-bit quantization with monotone levels {qk} and let wi be the bin width at θi. Any update |Δθi|≥wi changes the quantized value: Q4(θi+Δθi)≠Q4(θi). Setting δi≥wi in Phase 3 makes this a construction-time guarantee.
Proposition 2 (NF4 amplifies floor-crossing updates).
Let θi lie in a narrow-bin region of the NF4 grid (near zero; see Appendix D, Table 5) and let |Δθi|≥δi. When the update crosses two or more bin boundaries (m≥2, automatic since |qk+m−qk|≥mδi), |Q4(θi+Δθi)−θi|≥|Δθi|: quantization amplifies displacement rather than attenuating it, producing a negative PTQ gap. For single-crossing updates (m=1) deposited at the bin boundary by the floor, the amplification holds in expectation rather than with high probability. Conversely, for diffuse methods with |Δθi|<δi, the update does not cross any bin boundary and is silently erased by NF4, the +0.06 to +0.07 PTQ gap regime.
Summary: Theorem 1 (retain safety) + Lemma 1 (quantization permanence) + Proposition 2 (amplification) together explain why Mansu is the only method in Table 2 with margin on all four properties forget depth comparable to NPO, ΔPTQ≤0 across every cell, MMLU preserved, and CAD≫AS-NC.
6 Experiments
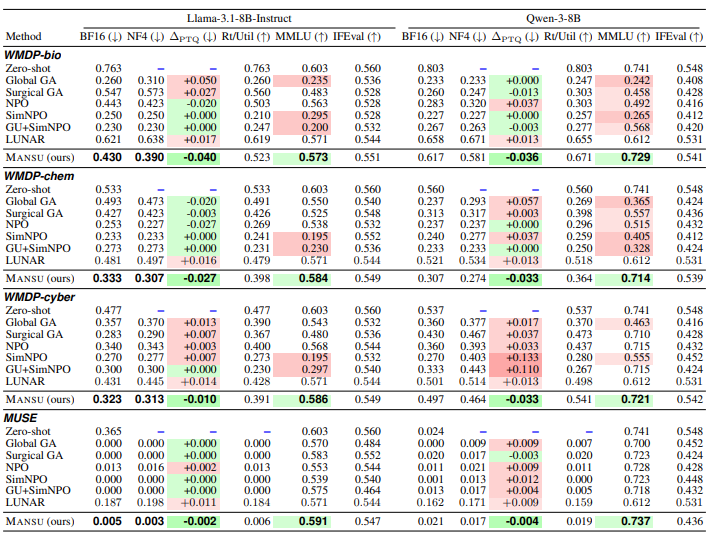
Table 2: Behavioral results. Forget set, retain split, and general capability for every method on Llama-3.1-8B-Instruct and Qwen-3-8B across four benchmarks. Columns: BF16 (↓) = forget-set accuracy in full precision (lower is better); NF4 (↓) = same forget set re-evaluated after 4-bit NF4 post-training quantization via bitsandbytes; ΔPTQ=accNF4−accBF16 the quantization-permanence metric we propose; negative values mean NF4 amplifies the erasure rather than reversing it (Lemma 1, Proposition 2); Rt/Util (↑) = WMDP retain-split accuracy (WMDP rows) or utility score (MUSE); MMLU/IFEval = model-level capability and instruction following, dataset-independent. Companion structural metrics (CAD, AS-C, AS-NC) are reported separately in Table 3 to keep behavior and mechanism visually distinct. – entries are not applicable: zero-shot NF4 and ΔPTQ are omitted because the unmodified model is not quantized as part of unlearning evaluation (PTQ gap would be vacuously zero); MUSE Rt/Util is additionally omitted because the utility score is only defined post-unlearning.
We answer three questions: does Mansu resolve the dual failure mode, is each component necessary, and is the forgetting structural? Setup, hyperparameters, timing, update statistics, and extended ablations are deferred to Appendices F–N.
Setup: Llama-3.1-8B-Instruct on WMDP-bio (Li et al., 2024) for the main table (Table 2); Mansu is additionally evaluated on MUSE (Shi et al., 2025) (Harry Potter open-ended memorization) and Qwen-3-8B (to assess architecture generalization, Qwen-3-8B columns of Table 2). A separate baseline sweep on six small/mid models (Gemma, Llama, Qwen families) on WMDP-{bio, chem, cyber} tests cross-architecture generality (Appendix J). Fixed forget and MMLU indices are reused across methods. NF4 evaluation via bitsandbytes (4-bit, double-quantization off); ΔPTQ=accNF4−accBF16 is the primary quantization metric. Six baselines: Global GA, Surgical GA (L14–16), NPO, SimNPO, GU+SimNPO, and LUNAR.
Table 3:Structural erasure metrics (companion to Table 2). CAD (↑) (Eq. 6): relative collapse of EAP-IG attribution mass on the original forget circuit; →1 = full collapse, →0 = circuit intact (LUNAR-style redirection: empirically ≈0.03–0.05 across all WMDP/MUSE cells, Table 3; near-zero by construction since LUNAR edits a single MLP projection outside the EAP-IG forget circuit). AS-C / AS-NC (↓) (Eq. 11): activation shift inside / outside 𝒞. Structural erasure requires high CAD and the gap AS-C ≪ CAD (present only for localized methods); for global baselines AS-C = CAD numerically.
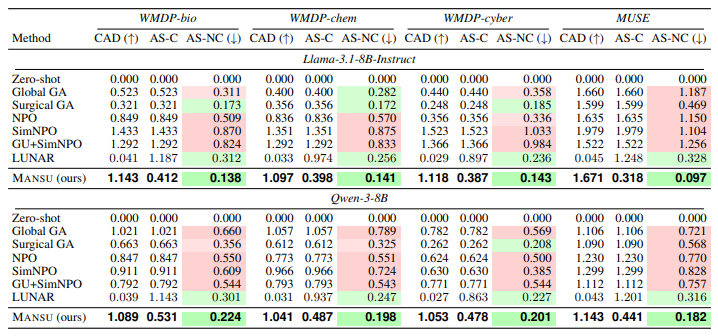
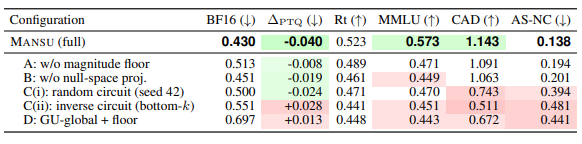
Table 4:Component ablation on Llama-3.1-8B-Instruct / WMDP-bio (zero-shot 0.763). Each row removes or replaces one Mansu component; all others held fixed. Bold = best per column. Each component isolates a distinct mechanism; the same pattern reproduces on chem and cyber (selected ΔPTQ/CAD numbers quoted in the prose below). Row D uses GU-global (no SimNPO), a weaker forget baseline than GU+SimNPO in Table 2; its higher BF16 is expected.
Main results: All findings read off the WMDP-bio Llama-3.1-8B block of Table 2 (zero-shot 0.763); the per-property scorecard in Figure 3 summarises pass/fail across all 24 weight-edit (method, dataset) cells (6 weight-edit methods × 4 datasets, both flagship models pooled; LUNAR is omitted from the scorecard since its inference-time redirection is reported separately). Gradient ascent fails quantization: Global GA’s BF16 forget 0.260 flips to NF4 0.310 (ΔPTQ=+0.050) with MMLU collapsing to 0.235 indiscriminate damage, not targeted erasure (Figure 1). Aggressive preference optimization survives quantization but destroys utility: SimNPO/GU+SimNPO reach forget 0.250/0.230 with ΔPTQ=0.000 but MMLU 0.295/0.200; NPO preserves MMLU (0.563) at the cost of half Mansu’s forget depth. Mansu satisfies all three properties: forget 0.430, NF4 0.390, ΔPTQ=−0.040, MMLU 0.573 (within 0.030 of zero-shot)
IFEval 0.551 NF4 amplifies the erasure (Proposition 2). Structural metrics confirm weight-level rather than behavioral erasure: Mansu attains the highest CAD (1.143) with low AS-NC spillover (0.138); LUNAR yields CAD ∈[0.029,0.045] across all WMDP/MUSE cells (Table 3), consistent with editing weights outside the EAP-IG forget circuit.
Cross-dataset / cross-architecture consistency. Mansu’s ΔPTQ is non-positive on all 8/8 (model, dataset) cells of Table 2; MMLU stays within 0.030 of zero-shot across cells; CAD exceeds 1.0 on 7/8 cells (Table 3). The pattern extends beyond the two flagship 8B models: Tables 6, 7, and 8 report Mansu on six additional model variants (Gemma-2B/3-1B/3-4B, Llama-3.2-3B, Qwen-2.5-4B/3-4B), and Table 9 the family-wise macro-averages — Mansu achieves strictly negative ΔPTQ on every cell of every sweep family. By contrast, no baseline beats Mansu on all three of forget, quantization-permanence, and utility on any cell the dual failure mode (gradient methods recover under NF4 / preference methods barely change the model) holds across WMDP-bio/chem/cyber, MUSE, and both Llama-3.1-8B and Qwen-3-8B.
Ablations: Table 4 reports each component independently on WMDP-bio (Mansu full: forget 0.430, ΔPTQ=−0.040,MMLU 0.573 (within 0.030 of zero-shot), CAD 1.143). A, no floor: ΔPTQ weakens from −0.040 to −0.008 and forget accuracy regresses to 0.513, isolating the floor as the mechanism turning circuit concentration into quantization permanence. B, no null-space projection: forget accuracy regresses to 0.451 and MMLU drops to 0.449 (largest utility hit of any row), confirming projection sharpens the forget–retain tradeoff and is the primary retain-protector (Theorem 1). C(i), random circuit (seed 42): same |𝒞|, but forget accuracy regresses to 0.500 and CAD collapses from 1.143 to 0.743 (−35%); AS-NC nearly triples (0.138→0.394), indicating diffuse rather than localized intervention. Forget quality — not just depth requires the causally identified circuit, directly rebutting (Lee et al., 2025) and (Guo et al., 2025) on the factual-recall benchmarks studied here. C(ii), inverse circuit (bottom-k): the strongest negative control ΔPTQ flips to +0.028, forget regresses to 0.551, and CAD bottoms out at 0.511 across all three domains, ruling out any beneficial effect from non-causal parameters. D, global null-space + floor (GU-global): ΔPTQ flips positive (+0.013) despite the floor, because diffuse global updates contain mixed-sign components that cancel below the bin floor under NF4 rounding. Circuit localization is therefore a necessary co-condition for quantization-robust erasure, not a substitute for the floor. Cross-domain consistency. The pattern reproduces on WMDP-chem and WMDP-cyber: Row A’s ΔPTQ flips to +0.004/+0.003 (vs full Mansu −0.027/−0.010); Row C(i)’s CAD collapses to 0.711/0.729 (vs 1.097/1.118); Row D’s ΔPTQ stays positive (+0.009/+0.007). Each component contributes the same way across all three hazard domains.
7 Discussion
Implications for evaluation practice. The 94 non-Mansu experiments show that the standard protocol selects for methods that make minimal parameter changes. A method that reduces forget-set accuracy by 1.6 percentage points is not solving the problem; it is passing the test. We propose two additions: the PTQ gap, and CAD (or an equivalent mechanistic verification). Neither requires new infrastructure.
Limitations. Mansu is reported on the two flagship 8B models from the Llama and Qwen families; results on smaller and earlier-generation models follow the same three-phase pipeline and are reported in Appendix J. Mechanistic localization is well-supported on factual-recall benchmarks of the kind studied here (Meng et al., 2022); behaviour beyond the 8B regime (|Δθi|∝1/d at fixed circuit fraction by Eq. (1)) is consistent with the floor remaining the binding mechanism but is not directly verified.
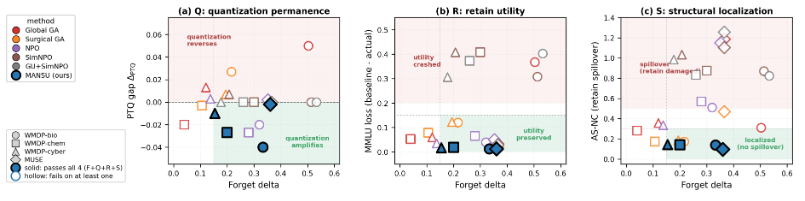
Figure 3:The four-property scorecard, decomposed. x: forget delta (all 24=6×4 weight-edit method-dataset cells; LUNAR excluded as inference-time redirection); y varies per panel: (a) ΔPTQ, (b) MMLU loss, (c) AS-NC. Bottom (green) is desired in all three. Marker colour = method, shape = dataset; solid = passes all four thresholds (F ≥30%, Q ≤0, R ≤0.15, S ≤0.30), hollow = fails at least one. Mansu is the only method solid in every panel.
8 Conclusion
If a model passes its unlearning evaluation in full precision, does it still pass after the compression step that precedes every real-world deployment? Across six methods and a single deployment compression pass, the answer is no. The forgotten knowledge returns, or it never left because the model barely changed. Mansu resolves this by asking the prior question mechanistic interpretability has already answered: where does the targeted knowledge live? Updating only the causally identified circuit, projecting away from retain-sensitive directions, and rescaling every update to clear the NF4 floor produces forgetting that is not reversed by the compression step; in fact, NF4 amplifies the erasure (PTQ gap −0.040 on WMDP-bio Llama, with preserved MMLU and IFEval). The 94-experiment dual-failure documentation, the CAD verification metric, and the sparsity-permanence framework should outlast any specific method: future approaches that satisfy all four properties of Section 3 must engage with this tradeoff.
9 Broader Impact and Ethics
This work is motivated by safety objectives in AI deployment. Durably removing hazardous knowledge (biosecurity threats, cyberweapons, chemical weapons) is a safety-critical requirement as language models become more widely deployed. Our finding that existing unlearning methods fail under 4-bit compression is information that practitioners and policymakers relying on unlearning for safety certification need to know.
Misuse. This work does not make hazardous knowledge easier to acquire. We demonstrate that existing methods are weaker than they appear; we do not provide tools for recovering knowledge from unlearned models. EAP-IG is a published open-source method we use for removal, not insertion.
Scope. Experiments cover bio, chem, and cyber hazard domains on MCQ. Generalization to other hazard types or open-ended formats requires additional validation. We do not claim Mansu is a complete solution to knowledge removal; it is meaningfully better than existing alternatives on the metrics we define.
Reproducibility. All datasets (WMDP, MMLU) are public. EAP-IG is at github.com/hannamw/EAP-IG. Our implementation, evaluation scripts, and fixed evaluation indices will be released upon acceptance.
arxiv link: https://arxiv.org/abs/2605.15138