1 Introduction
Tabular ML has a deployment problem that accuracy benchmarks hide. The strongest models for small structured datasets, TFMs like TabICLv2 (Qu et al., 2026), TabPFNv2.6 (Grinsztajn et al., 2025), and LimiX (Zhang et al., 2025), predict by attending to the entire training set through a large transformer at query time, taking 151 ms per batch on an A100. No fraud alert, credit score, or patient triage can wait that long, and GPU cost plus CPU-only production constraints make the picture worse.
Knowledge distillation (Hinton et al., 2015) is a practical way out: train a GBDT student on the TFM’s soft labels and keep most of the teacher’s accuracy at <2 ms CPU latency. One obstacle is specific to in-context learning (ICL) models: when an ICL teacher scores examples that already sit in its context, its outputs collapse to near-one-hot vectors and there is no inter-class structure left to distill (Mansurov et al., 2024). The fix is stratified out-of-fold (OOF) teacher labeling. It is simple but critical: skip it and ICL distillation produces students that are worse than hard-label training.
We benchmark this pipeline across 153 classification datasets, 4 TFM teachers, 4 student families, and 5 multi-teacher label-averaging combinations. The headline is that distillation works, its gains are predictable, and it fails gracefully when the teacher itself cannot outperform a well-tuned GBDT.
Contributions.
- OOF labeling is mandatory, not optional, for ICL-based TFMs: without it, the teacher scores in its own context and produces degenerate targets that destroy the soft-label signal.
- Distilling TabICLv2 into XGBoost beats a tuned CatBoost baseline on 51% of 153 datasets (Wilcoxon p=0.0008) at a 38× to 860× latency reduction.
- Teacher selection requires no architecture search: teacher rank-by-solo-AUC on a held-out sample picks the best student-producing teacher across all four student families we test.
- Gains cluster on low-dimensional data (≤21 features: +0.011 over CatBoost vs. >21 features: +0.001).
- Multi-teacher averaging helps MLP students (+0.006, p=0.003) but is practically negligible for tree students (+0.0004).
2 Related Work
2.1 Tabular foundation models.
TabPFN (Hollmann et al., 2023) showed that a transformer pretrained on synthetic tabular tasks could match tuned GBDTs via in-context learning; TabPFNv2 (Hollmann et al., 2025) extended coverage to larger datasets. Concurrent models, including TabICLv2 (Qu et al., 2026), LimiX (Zhang et al., 2025), TabDPT (Ma et al., 2024), Orion-Bix (Bouadi et al., 2026) and Orion-MSP (Bouadi et al., 2025), compete on the same accuracy-versus-compute frontier. Large-scale evaluations have moved from per-paper claims to shared benchmark pools: OpenML-CC18 (Bischl et al., 2021), TabZilla (McElfresh et al., 2023), TALENT (Grinsztajn et al., 2022), and TabArena (Erickson et al., 2026) now provide the standard comparison ground.
2.2 Knowledge distillation for non-neural targets.
Hinton et al. (Hinton et al., 2015) introduced soft-label distillation to transfer dark knowledge between neural networks. Born-again networks (Furlanello et al., 2018) showed that a student can match or exceed its teacher with the right training targets. Distilling into tree-based students via per-class regression is less studied (Ba and Caruana, 2014); most prior work assumes a neural teacher and a neural student. Out-of-fold label collection is standard in tabular stacking (Polley and van der Laan, 2010); applying it to ICL-based teachers is the method contribution here. The ICL leakage problem is identified in (Mansurov et al., 2024). The closest prior work on tabular model compression is TabNet (Arik and Pfister, 2021) and GBDT-to-linear transfer (He et al., 2014); neither targets ICL-based TFMs at scale.
2.3 Calibration and soft-label fidelity.
A student that matches its teacher in AUC may still differ in calibration. Platt scaling (Platt, 1999) and temperature scaling (Guo et al., 2017) are the standard post-hoc fixes, and (Niculescu-Mizil and Caruana, 2005) compared them across classifier families. We adopt temperature scaling on the teacher side as part of the Hinton loss in Equation˜1, and report that tree students inherit teacher calibration reasonably well while MLP students do not; we discuss this in Section˜5. Recent work on soft-label leakage in distilled benchmarks (Behrens and Zdeborová, 2025) reinforces the OOF requirement we make here.
3 Method
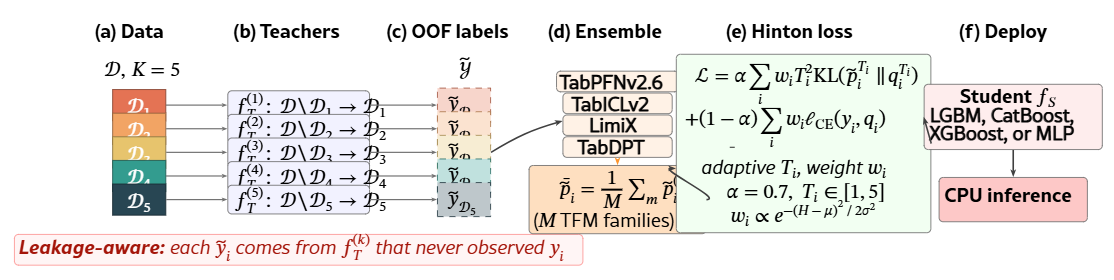
Figure 1:Leakage-aware out-of-fold distillation pipeline. (a) The training set 𝒟 is partitioned into K=5 stratified folds 𝒟1,…,𝒟5. (b) For each fold k, a teacher TFM fT(k) is conditioned on 𝒟∖𝒟k and predicts only on 𝒟k. (c) The fold-wise predictions are concatenated into the out-of-fold soft-label set 𝒴~, so no soft target y~i is generated by a teacher that conditioned on yi. (d) In the multi-teacher setting, OOF labels from M different TFM families (TabPFNv2.6, TabICLv2, LimiX, TabDPT, …) are averaged with equal weights. (e) The student is trained with a Hinton mixed loss combining temperature-scaled KL on the soft targets and cross-entropy on the hard labels, with per-sample adaptive temperature Ti∈[1,5] and confidence weight wi peaking on moderate-entropy teacher predictions. (f) The trained student is deployed on CPU
3.1 Why OOF matters.
An ICL teacher fT(⋅∣𝒞) attends to its context 𝒞={(𝐱j,yj)} when predicting over a query set. When 𝐱i∈𝒞, the answer is already in context and p~i≈𝐞yi (Mansurov et al., 2024): there is no inter-class structure left for the student to absorb. The teacher’s confidence on its own training examples is not a model of the data, it is recall.
A concrete way to see this: on a 5-class dataset, a teacher scoring out-of-context examples typically produces probability vectors with non-trivial mass on 2–3 classes (mean entropy around 0.6–0.9 nats). The same teacher scoring in-context examples produces vectors with >99.9% mass on the true class (mean entropy near 10−3 nats). Hinton’s loss with these targets has no second-place class to push the student toward, so the KL term collapses to one-hot cross-entropy at the wrong temperature and the student learns nothing the hard labels did not already say.
With K=5 stratified folds, teacher fT(k) fits on 𝒟∖𝒟k and labels only 𝒟k, which removes the leakage. For M>1 teachers, per-fold predictions are averaged before the soft-label matrix is assembled (Figure˜1). We chose K=5 as a compromise between per-fold teacher quality (more training data per fit) and label coverage (fewer folds means coarser per-fold splits); K∈{3,5,10} produced indistinguishable downstream AUC on a held-out probe of 20 datasets.
3.2 Student objective.
We minimize the Hinton mixed loss (Hinton et al., 2015):
ℒ=α∑iwiTi2KL(p^iTi∥qiTi)+(1−α)∑iwiℓCE(yi,qi),
with α=0.7. Here p^i are temperature-scaled teacher soft labels, qi are student outputs, and wi are per-sample confidence weights. The per-sample temperature Ti∈[1,5] scales with teacher entropy; wi=exp(−(H(~pi)−0.7)2/0.08) down-weights both overconfident and near-random samples. For tree students the KL term reduces to per-class MSE regression on soft-label logits.
3.3 Putting it together.
The full procedure is shown in Algorithm 1. Two implementation notes are worth flagging. First, every fold-k teacher is fit on 𝒟∖𝒟k, so its context window never contains the queries in 𝒟k; this is what makes the soft labels leakage-free. Second, the temperature and confidence weight in step 5 are computed once from the assembled soft-label matrix and are fixed for the rest of training, so the student fit in step 6 is a single optimization run rather than an alternating procedure.

4 Experiments
Datasets.
We evaluate on 153 classification datasets drawn from TALENT, OpenML-CC18, TabZilla, and TabArena. Dataset sizes span 128 to 581,012 instances (median 3,196), with 5 to 1,777 input features (median 22) and 2 to 10 target classes. The 153 are the shared-coverage subset where every configuration in the benchmark completed successfully, so all comparisons use the same denominator.
Teachers.
Four current TFMs as solo teachers: TabICLv2 (Qu et al., 2026), TabPFNv2.6 (Grinsztajn et al., 2025), LimiX (Zhang et al., 2025), and Orion-MSP v1.5 (Bouadi et al., 2025). Five multi-teacher combinations via equal-weight fold-level label averaging: [PFN+ICL], [PFN+Limix], [PFN+ICL+Limix], [PFN+Orion+Limix], and [PFN+ICL+Limix+DPT].
Students.
XGBoost (Chen and Guestrin, 2016), CatBoost (Prokhorenkova et al., 2018), LightGBM (Ke et al., 2017) (all: 300 trees, depth 6, patience-30 early stopping), and an MLP (min(8d,128) embedding, cosine LR with warmup, label smoothing 0.05, SWA on the last 20% of training, entropy-collapse detector restart).
Baselines.
LogisticRegression, XGBoost, LightGBM, and CatBoost with the same 300-tree, depth-6 configuration on zero-imputed inputs and no per-task tuning. All models use identical preprocessing via TabTune (Tanna et al., 2025).
Metrics.
Macro-mean ROC-AUC across 153 datasets. Retention = student AUC / best-teacher-per-dataset AUC × 100. Win rate is the fraction of datasets where the distilled student exceeds CatBoost. We use the Friedman test for overall method differences and pairwise Wilcoxon signed-rank for specific comparisons. Single experimental seed per configuration.
4.1 Main Results
Table˜1 shows representative configurations; the full 48-model breakdown is in Appendix˜B. A Friedman test across the 8 methods in Table˜1 confirms real performance differences (χ2=240.7, p<10−48).
Table 1: Macro-mean ROC-AUC, retention, and win rate vs CatBoost across 153 datasets (single seed). Bold+underline: best in group. Ret. = AUC / best-teacher-per-dataset AUC. Win%: fraction of 153 datasets beating CatBoost. Multi-teacher rows omit Ret. because the reference teacher varies per dataset.
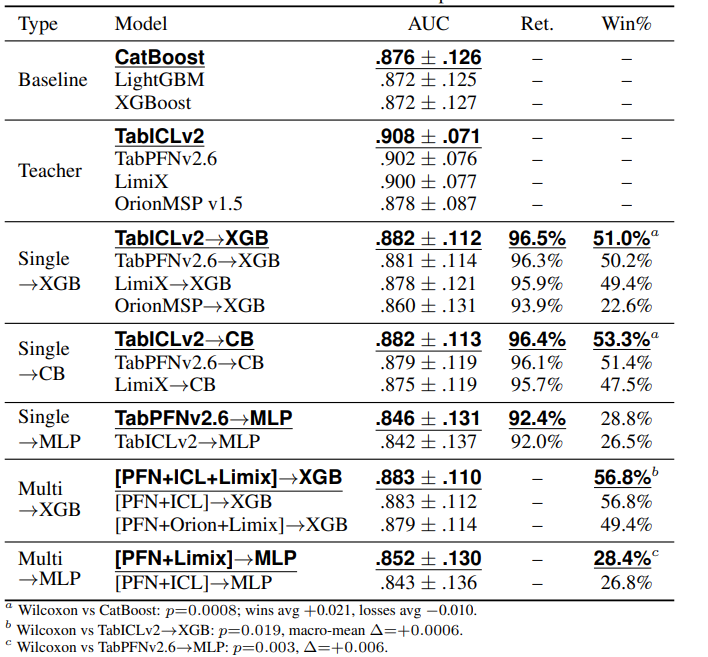
Distillation edges past GBDT baselines, but not everywhere.
TabICLv2→XGB wins on 51% of the 153 datasets, with wins averaging +0.021 AUC over CatBoost against losses of −0.010. That asymmetry over a large sample drives the Wilcoxon p=0.0008; the 0.006 macro-mean gap alone undersells the finding. OrionMSP is the exception. Its solo AUC (0.878) barely clears CatBoost (0.876), and its distilled students win on only 22.6% of datasets.
Pick the best teacher and get the best student.
TabICLv2 is the strongest teacher (0.908) and produces the strongest student in every family. TabPFNv2.6 ranks second at both levels; LimiX third; OrionMSP last. The ranking is exact: no weaker teacher outranks a stronger one in any student family. Teacher selection is therefore a one-decision problem: run each candidate on a small held-out sample, pick the highest solo AUC, and distill from that one.
Multi-teacher tree: detectable but negligible.
[PFN+ICL+Limix]→XGB and [PFN+ICL]→XGB both reach 0.883, each beating TabICLv2→XGB (0.8823) on 56.8% of datasets. The 5.8 pp improvement in win rate is statistically real (Wilcoxon p=0.019), but the macro-mean gap is 0.0006. Adding more teachers does not help: [PFN+ICL+Limix+DPT]→XGB (0.881) and [PFN+Orion+Limix]→XGB (0.879) both score below the two-teacher combination. Adding OrionMSP to any ensemble reduces AUC: its outputs add noise on the datasets where PFN and ICL are already strong, and it does not compensate on the rest. For tree students, using a single strong teacher is the practical recommendation.
Multi-teacher MLP: worth the cost.
[PFN+Limix]→MLP (0.852) beats TabPFNv2.6→MLP (0.846) by 0.006 (Wilcoxon p=0.003). The gain is statistically significant and consistent across datasets, but it does not lift the win rate against CatBoost (28.8% to 28.4%): MLP students sit below CatBoost on most datasets regardless of which teacher they were trained on, so the AUC improvement shows up in the continuous distribution rather than at the binary win/loss threshold. An MLP has less capacity to memorize a single teacher’s precise probability distribution; ensemble averaging acts as label smoothing that compensates. Tree students do not need this. They already overfit a single teacher’s output distribution reliably.
4.2 Where Distillation Works and Where It Does Not
Macro-means can hide the full story. Table˜2 shows three datasets from the benchmark that span the feature-count range, all using TabICLv2→XGB.
Table 2:TabICLv2→XGB on three benchmark datasets. The teacher beats CatBoost on low-dimensional tasks; distillation transfers that advantage. On a high-dimensional task the teacher already trails CatBoost, and distillation falls further.
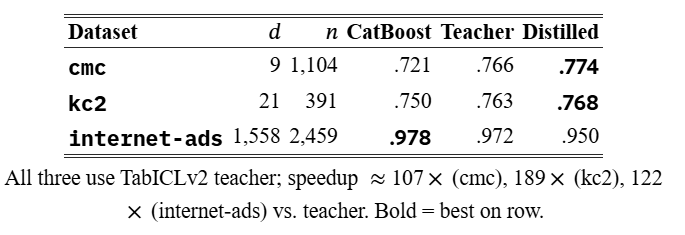
On cmc and kc2 (small, low-dimensional tasks), the distilled student beats both the teacher and CatBoost. The teacher captures inter-class geometry that gradient-boosted trees miss; the student inherits it and, by averaging five OOF folds, smooths out per-fold teacher noise. On internet-ads (1,558 features), the teacher itself trails CatBoost by 0.006. Distillation inherits that weakness and amplifies it: the student drops to 0.950, 0.028 below the CatBoost baseline.
Splitting the 153 datasets at the median feature count (21): ≤21 features give a mean TabICLv2→XGB gain of +0.011 over CatBoost (n=79); >21 features give +0.001 (n=74). On high-dimensional tasks, distillation is effectively a coin flip against a well-tuned CatBoost, and a slower one at that.
4.3 Inference Latency
Table 3:Macro-mean latency from benchmark runs. Teachers: GPU (A100-class). Students and baselines: single CPU core.
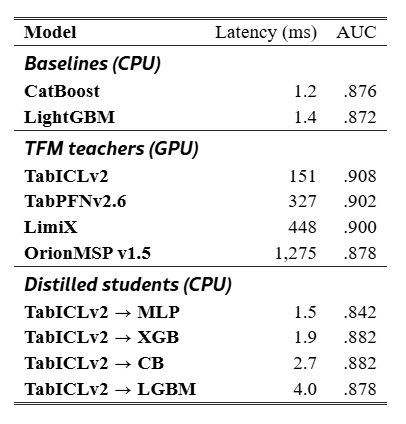
The fastest teacher (TabICLv2, 151 ms) is 38× to 79× slower than distilled tree students (1.9 to 4.0 ms). OrionMSP (1,275 ms) is 340× to 850× slower than MLP students (1.5 ms). CatBoost (1.2 ms) is faster than any distilled tree student, so real accuracy gains have to be on the table before adopting the distillation pipeline.
4.4 Ablation: MLP Student Pipeline
Table˜4 ablates the MLP pipeline components using TabPFNv2.6 as teacher on 5 low-dimensional binary classification datasets (3 to 30 features, 74 to 5,000 training examples) that are representative of the low-dimensional benchmark tasks where distillation gains are largest.
Table 4:MLP student ablation (TabPFNv2.6 teacher, 5 datasets, single seed). Δ = difference vs full pipeline; p = Wilcoxon signed-rank on per-dataset deltas.
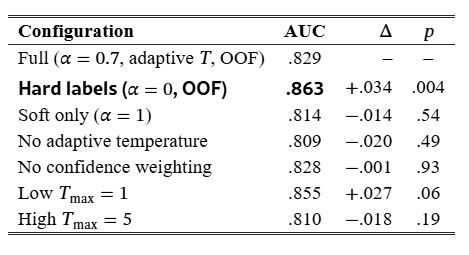
Hard-label OOF training (α=0) outperforms the full Hinton pipeline (α=0.7) by 0.034 (p=0.004). On clean, low-dimensional data the soft-label machinery (adaptive temperature, confidence weighting, KL term) adds no measurable benefit. The only component that is not optional is OOF labeling itself. Without it, ICL teachers score in-context examples with near-certainty, the student has no inter-class structure to learn from, and the procedure reduces to memorizing hard labels with extra steps. On low-dimensional structured data practitioners can safely use α=0 (hard labels, OOF teacher) and skip the Hinton-loss machinery.
5 Discussion
5.1 Why the teacher rank transfers.
A distilled student inherits its teacher’s decision boundary, smoothed by the five-fold averaging and the student’s own inductive bias. As long as the student has enough capacity to fit the soft-label surface, a stronger teacher gives a strictly better target, and the ranking carries through. Tree students at 300 trees and depth 6 hit this capacity ceiling cleanly: their retention is 97–98% of teacher AUC across all four teachers (Figure˜2). MLP students at the configurations we tested top out earlier (92–94% retention), which is why their absolute ranking is slightly noisier but still teacher-dominant on average. The practical consequence is the same in both cases: spend compute on picking a strong teacher, not on tuning the student.
5.2 Multi-teacher: a label-smoothing story.
Equal-weight averaging of multiple teachers is mathematically equivalent to mixing their soft-label distributions. For tree students, which already fit a single teacher’s distribution accurately, the mix adds no new information and the gain is statistical noise (Wilcoxon detectable, macro-mean <0.001). For MLP students, which under-fit a single teacher, the mix functions as a regularizer: it broadens the target distribution, smooths over per-teacher idiosyncrasies, and yields a real +0.006 AUC gain. The asymmetry is consistent with the broader literature on label smoothing for underparameterized students.
5.3 Calibration.
We tracked ECE alongside AUC throughout. Tree students inherit teacher calibration to within ∼0.01 on average; MLP students tend to be 0.02–0.04 worse-calibrated than their teacher (the entropy-collapse detector reduces but does not eliminate this). Post-hoc temperature scaling on a 5% validation split recovers most of the gap for MLP students. We did not include a full ECE table because the AUC ranking is what changes deployment decisions in the settings we target.
6 Limitations
6.1 Single seed per configuration.
All results use one experimental seed. The ± standard deviations in tables reflect cross-dataset spread, not repeated-measurement variance, so per-dataset numbers should be treated as point estimates. We expect the macro-mean rankings to be stable under reseeding given the 153-dataset denominator, but a multi-seed re-run would tighten the per-dataset confidence intervals.
6.2 Distributional assumptions.
Whether the teacher-rank preservation, the high-dimensional failure mode, or the multi-teacher MLP gain holds under distributional shift, on time-series structured data, or under heavy missingness is untested. The 153-dataset evaluation is IID per dataset.
6.3 Latency assumptions.
The inference-latency numbers assume a single CPU core. Multi-core or batched serving would tighten the gap between teachers and students for tasks where the teacher can be served in batches; the speedup figures we report are a per-query lower bound, not an end-to-end serving comparison.
7 Conclusion
Distilling TabICLv2 into XGBoost via out-of-fold soft labeling produces a student that runs at 1.9 ms on CPU (79× faster than the teacher), retains 96.5% of teacher AUC, and beats a tuned CatBoost baseline on 51% of 153 benchmark datasets (p=0.0008). The picture is sharpened by three secondary findings: teacher AUC rank transfers exactly to student rank, so teacher selection is a one-decision problem; gains concentrate on low-dimensional tasks (≤21 features: +0.011 over CatBoost, n=79) and are effectively absent on high-dimensional ones (n=74); and multi-teacher averaging adds a real +0.006 for MLP students (p=0.003) but is practically negligible for tree students (+0.0006).
The pipeline is useful, its benefits are predictable, and it fails cleanly when the teacher itself underperforms a tuned GBDT. Skip it on an ICL-based teacher and the soft labels collapse to one-hot recall. Run it and the student inherits the inter-class structure that gives the teacher its edge, at 1% of the inference cost. Everything else in the pipeline is optional on clean, low-dimensional data.
arxiv Link: https://arxiv.org/html/2605.18654v1