1 Introduction
Synthetic post-training pipelines filter generated samples with LLM-as-judge quality gates before fine-tuning. Judges in this setting typically follow preference rubrics covering helpfulness, instruction following, and truthfulness [3], but these rubrics do not verify whether a generated response is supported by the source passage that induced it. Source-grounded evaluation frameworks such as G-Eval [13] and CheckEval [12] derive their criteria directly from a source chunk and offer a more targeted faithfulness signal, yet none of the major synthetic data curation libraries, including distilabel [1] and AgentInstruct [15], preserve an explicit provenance record linking each generated sample back to its generation source. Without this record, faithfulness gating must operate on post-hoc retrieved evidence, which approximates rather than observes the original evidence relation.
A second gap concerns rejected samples. Existing pipelines treat rejection as terminal, discarding failures and spending generation budget on fresh samples. The rejection sampling literature, including RAFT [4] and ReSTEM [19], shows that regenerating from the same prompt under a quality filter substantially improves yield. These methods target iterative model self-improvement under a single global acceptance criterion, however, and whether structured failure diagnosis and targeted repair offers meaningful gains over naive regeneration in a source-grounded curation setting is an open question.
We study both problems in a controlled ablation, varying gate configuration, recovery strategy, and generator scale while holding corpus and judge family fixed. We find that exact-provenance gating outperforms both reward-only filtering and post-hoc retrieved evidence on faithfulness detection, that hallucination and reward gates reject largely disjoint failure populations and are thus both necessary, and that adaptive diagnose-and-repair outperforms naive regeneration on yield, recovery rate, and injection recall. Downstream fine-tuning quality is driven primarily by generator scale, with filtration and recovery conditions contributing meaningfully but secondarily.
Contributions:
- A provenance-grounded gating study showing that exact source evidence improves faithfulness detection for stronger judges, with reward-only filtering and post-hoc retrieval degrading gate quality in complementary ways.
- A controlled recovery ablation showing that adaptive diagnose-and-repair consistently outperforms naive regeneration in yield, recovery rate, and injection recall.
- A clean held-out evaluation corpus for source-grounded QA, released to support reproducible downstream evaluation of synthetic data curation pipelines.1
2 Methodology
Provenance-preserving generation. Each sample is generated from a source chunk c drawn from the corpus, and a provenance record linking the sample to c is attached at generation time. This record is append-only and persists through all downstream pipeline stages, making the exact generation evidence available to the hallucination gate without retrieval.
Gates. The HallucinationGate performs structured claim verification against the preserved source chunk (τhall=0.8), directly testing whether the generated response is entailed by the evidence that induced it. The RewardGate scores instruction-output quality following a preference rubric without source access (τreward=0.7). A sample must clear both gates to be accepted.
Adaptive recovery (primary). On hallucination failure, a DiagnosticProbe diagnoses the failure mode and applies a targeted configuration patch, such as lowering generation temperature or expanding context, before regenerating the sample. Probe-recovered samples re-enter the reward gate. On reward failure, a RewardRefiner rewrites the output for quality without altering the underlying claims. Both recovery steps operate against the same preserved provenance record.
Naive retry (ablation). On any gate failure, the generator produces a fresh response from the original prompt without diagnosis or repair. The new response must clear both gates with up to five retries before the sample is permanently rejected.
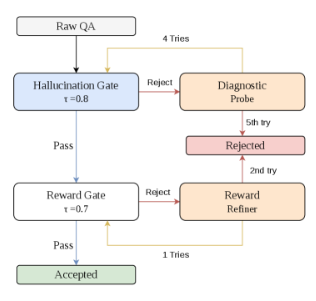
Figure 1:Adaptive recovery pipeline. Hall-rejected samples enter the DiagnosticProbe for up to 4 targeted repair attempts (blue path); reward-rejected samples enter the RewardRefiner for one rewrite (orange path). Samples clearing both gates are accepted.
3 Experimental Setup
Source corpus. The corpus spans three domains: 1,500 source chunks (500 per domain) from CUAD [6] commercial contracts, PubMedQA [9] biomedical abstracts, and English Wikipedia 2023.2 Each chunk seeds three base QA pairs per training variant; across two training variants and post-generation filtering of malformed outputs, this yields approximately 8,000–8,500 raw candidates per generator.
Adversarial injections. Four failure types are injected into approximately 20% of samples: contradicts_source, parametric_drift, domain_mismatch, and instruction_quality, providing ground-truth labels for gate recall value of rejecting these samples and recovering them.
Generators and judges. Generators: Qwen3-1.7B, 4B, 8B [17]. Three judge sizes are used across experiments: Qwen3-14B, Qwen3.6-27B-FP8, and Qwen3.6-35B-A3B. Provenance gating experiments are evaluated across all three judges; adaptive recovery experiments use the 14B and 35B judges; the recovery ablation uses a single judge. All models run in non-thinking mode via vLLM.
Benchmarks and metrics. Provenance gating quality is evaluated on FaithDial [5] (n=3,507) against ground-truth faithfulness labels. Downstream evaluation uses a held-out test set of 1,400 instructions, generated independently of all training corpora and fixed before any pipeline experiments began. Metrics: ROUGE-L, BERTScore F1, and Faithfulness (BERTScore F1 between model output and source chunk).
Fine-tuning. Qwen3-4B base, LoRA (r=16,α=32) via Unsloth [21, 8], early stopping (patience =2, up to 4 epochs). Full hyperparameters in Table 11 (Appendix E).
4 Results and Analysis
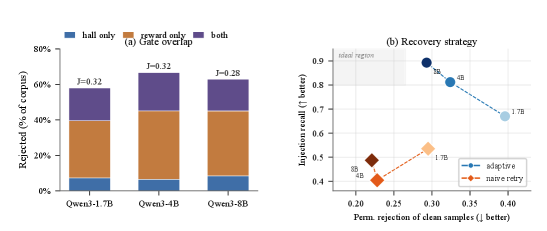
Figure 2:(a) Rejection-set overlap per generator as % of corpus (35B judge; Appendix B.3 for 14B numbers). Both hall-only and reward-only segments are substantial; Jaccard ∈[0.23,0.32], confirming the two gates target structurally different failure modes. (b) Recall-rejection tradeoff (shaded = better; ideal: lower-right). Adaptive improves with generator size (light to dark blue); by 8B (29.3% reject, 89.3% recall) it achieves lower rejection and higher recall than naive retry on 1.7B (29.5%, 53.5%; diamond), fully dominating on both axes.
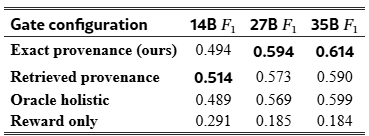
Table 1:Gate method comparison on FaithDial (n=3,507). Exact-provenance gating achieves the highest F1 at 27B and 35B; retrieved provenance leads marginally at 14B. Reward-only scoring catastrophically over-rejects faithful samples at every judge size. Full P/R results in Appendix B.1.
We evaluate the pipeline along three axes: whether exact-provenance gating detects faithfulness failures missed by reward-only filtering and whether the two gates are complementary, whether adaptive diagnosis-and-repair outperforms naive regeneration as a recovery strategy, and whether curation choices affect downstream fine-tuning quality independently of generator scale (Section 4.3).
4.1 Gate Characterization
We evaluate four gate configurations on FaithDial (n=3,507); results are in Table 1. Exact-provenance gating achieves the highest F1 at 27B and 35B, reaching 0.614 at 35B, while retrieved provenance leads marginally at 14B (0.514 vs. 0.494). Overall, post-hoc retrieval trails exact provenance for stronger judges, and oracle holistic scoring reaches 0.599 at 35B. Reward-only scoring is unusable as a faithfulness filter: only 14-45% of genuinely faithful samples pass depending on judge strength, making it a source of systematic over-rejection rather than quality control. The provenance signal transfers across judge families under both G-Eval and CheckEval scoring (Appendix B.2), confirming the finding is not an artefact of a particular judge model.
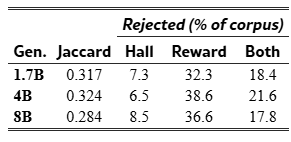
Figure 2(a) breaks down rejection sets when both gates run on the unfiltered generated corpus. Jaccard overlap sits in [0.23,0.32] across all generators and both judges (Appendix B.3), confirming the two gates target structurally different failure modes. The split is not random: contradicts_source and domain_mismatch are caught reliably (82-90% recall for the 4B and 8B generators), while instruction_quality resists both gates (24-42% recall; Table 8, Appendix B.4). Neither gate catches what the other misses; both are necessary.
Table 2:Gate rejection-set overlap on the generated corpus (35B judge). Hall-only and reward-only segments are both substantial; Jaccard ∈[0.28,0.32] confirms the two gates target structurally different failure modes. 14B numbers in Appendix B.3.
4.2 Recovery: Structured Repair Outperforms Naive Retry
Structured adaptive repair outperforms naive retry on total yield, pass rate, and injection recall across all three generator sizes. The full stage-by-stage breakdown including the +42% yield gain over hard filtering is in Appendix B.5.
Table 3:Adaptive recovery vs. naive retry (14B judge). Adaptive leads on pass rate, recovery rate, and injection recall at every generator size, with the injection recall gap widening substantially with scale. Naive retry permanently discards fewer clean samples (lower uninjected rejection), but adaptive recovers enough of its initial rejects to end with higher total yield despite this disadvantage.
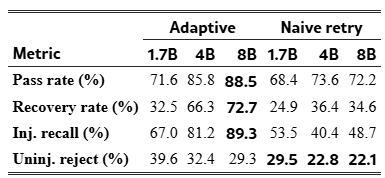
Adaptive accepts more samples and recovers a larger share of total rejects at every generator size, with the recovery rate advantage growing from +7.6 points at 1.7B to +38.1 points at 8B. The injection recall gap is the starkest signal: 89.3% vs 48.7% at 8B, nearly double, with the widest within-type gap on instruction_quality (74.4% vs 51.3%) and parametric_drift (71.7% vs 58.1%) at 1.7B (Table 8, Appendix B.4). Naive retry permanently discards fewer samples from the non-injected pool, which we term the natural rejection rate. We note that non-injected samples are not guaranteed to be high quality; they simply did not receive a controlled adversarial perturbation, and natural gate failures among them may reflect genuine faithfulness or quality deficiencies rather than over-rejection. Adaptive’s higher natural rejection rate therefore does not straightforwardly imply worse precision (see Section D). Figure 2(b) shows the recall-rejection tradeoff: adaptive improves on both axes as generator size increases, and by 8B fully dominates naive retry on both dimensions simultaneously.
4.3 Downstream: Generator Size Dominates
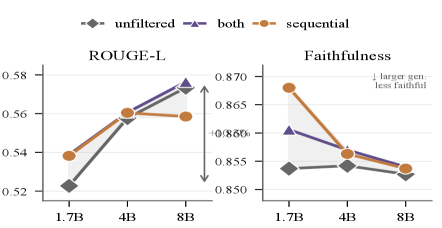
Figure 3:Downstream metrics by generator and condition. Each line shows one filtration condition across generator sizes; the shaded band spans the within-generator spread. The steep cross-generator slope (+6.6% ROUGE-L, 1.7B→8B) dwarfs the within-generator spread, confirming generator scale dominates downstream quality.
Table 4:Downstream fine-tuning (Qwen3-4B base, LoRA, n=1,400). Three representative conditions are shown; full results across all five conditions in Table 10 (Appendix B.5). Generator scale drives ROUGE-L (+6.6%, 1.7B→8B); within-generator spread across all conditions is at most 0.016 (1.7B), 0.007 (4B), 0.018 (8B). Bold = best per generator per metric.
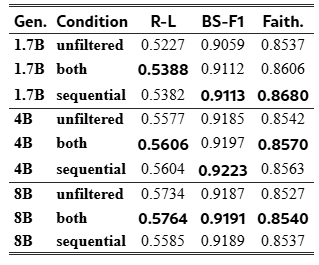
Generator scale is the dominant signal: ROUGE-L rises from 0.523 (1.7B, unfiltered) to 0.576 (8B, both-filtered), a cross-generator gain of +6.6% that dwarfs any within-generator spread. The practical contribution of filtration shrinks with generator capacity: the gain from unfiltered to best-filtered is +0.016 ROUGE-L for 1.7B but only +0.003 for 4B and 8B, a fivefold reduction. For the two larger generators, all conditions including unfiltered cluster within 0.007 of each other, indicating that stronger generators produce data of sufficient baseline quality that curation adds marginal downstream value.
Sequential recovery provides its clearest benefit at 1.7B, where it achieves the global best faithfulness score (0.868, +0.007 over both-filtered for the same generator). This advantage does not transfer to larger generators: for 4B and 8B, sequential recovery is comparable to hard filtering on faithfulness and slightly lower on ROUGE-L at 8B, suggesting that recovered samples from stronger generators are structurally different from their native output. Faithfulness decreases marginally with generator scale (−0.007 absolute, 1.7B→8B under both-filtered), a consistent but small trade-off against the lexical quality gains. Full results across all five conditions are in Table 10 (Appendix B.5).
5 Conclusion
We presented a controlled study of LLM-as-judge curation pipelines across gate configurations, recovery strategies, and generator scales. Exact-provenance hallucination gating outperforms reward-only filtering and post-hoc retrieved evidence, and hallucination and reward gates reject largely disjoint failure populations, confirming both are necessary. Reward-only scoring alone catastrophically over-rejects faithful samples regardless of judge strength. Structured adaptive repair outperforms naive retry on yield, recovery rate, and injection recall across all generator sizes, with the injection recall advantage growing to nearly double at 8B (89.3% vs 48.7%), and the DiagnosticProbe’s failure-mode telemetry surfaces diagnostic signal that naive retry discards. Generator scale is the dominant quality driver, though curation provides its clearest benefit when smaller generators are non-negotiable, where exact-provenance gating with adaptive recovery closes a meaningful fraction of the quality gap. A genuine but small faithfulness trade-off with scale (−0.007 absolute) can be addressed using the HallucinationGate when source fidelity is a hard requirement.
Limitations
All generators, judges, and the fine-tuning base are from the Qwen3 family; cross-family replication is needed to confirm generality. Provenance gating is validated on a single benchmark (FaithDial, n=3,507). The downstream benefit of filtration conditions diminishes with generator scale: within-generator condition spreads (0.002–0.010 ROUGE-L) are plausibly within noise at n=1,400, suggesting that structured repair is most valuable when baseline generator quality is low. Downstream fine-tuning uses a single base model (Qwen3-4B with LoRA). The three-domain corpus (legal, biomedical, Wikipedia) may not represent specialized or low-resource domains. The DiagnosticProbe is inherently sequential, as each sample requires up to six chained LLM calls whose outputs determine the next step, and although the pipeline overlaps independent samples via asyncio with bounded concurrency, per-sample probe latency remains a bottleneck.
Ethics Statement
This work uses LLM-as-judge systems as quality filters. Such judges inherit biases from their training data; the quality of any curated corpus depends on judge quality and should be validated against ground-truth labels on domain-representative samples before deployment. No new pretraining is performed; all inference uses existing publicly available checkpoints. Data curation experiments ran on an NVIDIA A100 (80 GB) and fine-tuning on an RTX Pro 6000 (96 GB); total compute was approximately 26 GPU-hours across both stages. All source corpora are derived from publicly licensed datasets (CUAD: Apache 2.0, PubMedQA: MIT, Wikipedia: CC BY-SA, FaithDial: MIT) and contain no personally identifiable information.
arxiv Link: https://arxiv.org/html/2606.11127v1