1 Introduction
Structured data is central to health machine learning [21]. Tasks such as risk stratification, disease screening, readmission prediction, and mortality estimation are often defined over EHR, laboratory values, demographics, and other tabular variables [11]. These datasets are frequently small, heterogeneous, and sparse, making data-efficient prediction essential. Healthcare deployment also requires more than high accuracy. Hospital systems are often CPU-based, air-gapped, and constrained by data-residency policies, limiting the use of cloud-GPU inference. Models must produce calibrated probabilities that support clinical decisions [7] and avoid amplifying demographic disparities that can affect access to care [17, 8].
Tabular foundation models (TFMs) have recently emerged as a promising approach for such clinical datasets. Models such as TabPFNv2.5 [6], TabICLv2 [20], TabDPT [13], LimiX [25], and Orion-MSP [2] often match or outperform tuned gradient-boosted trees on datasets with fewer than ten thousand rows, without per-task tuning.
However, the TFM inference paradigm conflicts with the practical constraints of clinical deployment. Predictions require conditioning on a task-specific context set and running large neural models on dedicated GPU hardware. Many hospital systems are CPU-based, air-gapped, or constrained by data-residency rules, and these requirements rule out direct deployment. Even where GPU inference is available, latency on the order of hundreds of milliseconds limits the use of TFMs in high-throughput batch scoring (whole-hospital risk surveillance, registry sweeps, retrospective audits) and in real-time alert pipelines that must integrate with existing monitoring and auditing infrastructure.
We therefore ask whether TFMs’ predictive behavior, including accuracy, calibration, and fairness, can be transferred to standard ML models that are easier to deploy. We study this question through knowledge distillation [9] from TFMs into lightweight students. Since TFM teachers condition on labeled training examples at inference time, teacher outputs for examples included in the context can produce biased soft targets [14]. We mitigate this using stratified out-of-fold teacher labeling. We run extensive experiments across 19 health datasets (16 binary, 3 multiclass), using 6 TFMs as teachers, 4 standard models—LightGBM [12], CatBoost [19], XGBoost [4], and an MLP—as students, and 4 multi-teacher ensembles. We find that: (i) distilled students retain more than 90% of teacher AUC, outperforming teachers on some datasets; (ii) MLP students are 2× faster than LightGBM but are miscalibrated and amplify fairness gaps; (iii) Multi-teacher settings tend to be outperformed by the best single teacher.
Contributions.
We summarize our contributions as follows:
- We study knowledge distillation as a practical route for transferring TFM predictions into deployable healthcare tabular models.
- We propose a stratified out-of-fold teacher-labeling scheme to prevent teacher identity leakage from ICL-based TFMs.
- We benchmark TFM distillation across 19 healthcare datasets, 6 teachers, 4 student families, and multi-teacher ensembles.
- We show that tree-based students provide the strongest accuracy–calibration–fairness tradeoff, while MLP distillation and naive multi-teacher averaging are less consistently beneficial.
2 Related Work
Tabular foundation models.
TFMs pretrain on synthetic or curated real tables and then use in-context learning at inference time. TabPFN [10] and its v2.5/v2.6 update [6] are prior-fitted networks trained on synthetic Bayesian-style data. TabICLv2 [20] focuses on context length and inference throughput. TabDPT [13] pretrains on a large corpus of real tables. LimiX [25], Orion-Bix [3] and Orion-MSP [2] extend the approach with multi-scale or sparse attention. Despite the architectural variation, the deployment profile is essentially the same: a GPU forward pass conditioned on the labeled training set, with cost that scales with context size and memory in the tens to hundreds of megabytes on accelerator hardware.
Knowledge distillation.
Distillation transfers a teacher’s predictive distribution to a student through softened probability targets [9]. Follow-up work has examined when soft labels actually help [22, 26] and when ensemble averaging adds noise rather than signal [5]. The technique is widely used in vision, language, and speech, but the tabular setting has received much less attention. Two recent findings are directly relevant here: soft labels can carry held-out information from the teacher, including memorised training points [1], and benchmark scores can be inflated through indirect distillation chains [14].
In-context teachers and leakage.
Because TFM teachers condition on the training set at inference, scoring those same training points returns predictions on examples the model has effectively seen. We refer to this as teacher identity leakage. The standard remedy in stacking is K-fold out-of-fold prediction, and we adopt it here. To our knowledge, the only published TFM distillation pipeline is the closed-source engine packaged with TabPFNv2.5 [6]; we cannot benchmark directly against it. Our pipeline is open-source, model-agnostic across multiple TFM families, and supports multi-teacher ensembles.
Clinical tabular machine learning.
Healthcare prediction tasks routinely operate on tabular inputs derived from EHR data [11, 21]. Two requirements distinguish this domain from generic tabular benchmarks. Probabilities need to be calibrated so they can be plugged into threshold-based decision rules [7, 18, 15]. Group fairness has to be evaluated alongside accuracy, since miscalibrated or biased models can affect care decisions [8, 17]. Recent tabular fine-tuning work [24] and tabular ICL architectures [3] have begun adapting TFMs to such settings; our work is complementary, focused on what happens after a strong TFM is available and the bottleneck is deployment. The TabTune library [23] provides a unified evaluation surface for accuracy, calibration, and fairness, and is the basis for our experimental harness.
3 Methodology
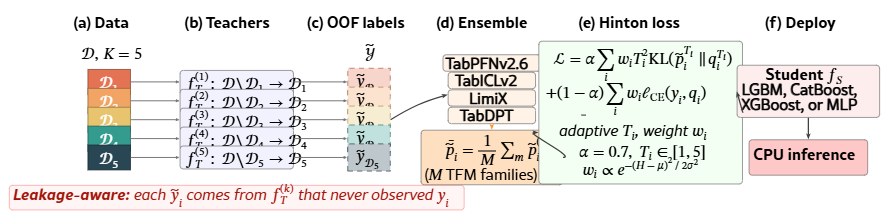
Figure 1:Leakage-aware out-of-fold distillation pipeline. (a) The training set 𝒟 is partitioned into K=5 stratified folds 𝒟1,…,𝒟5. (b) For each fold k, a teacher TFM fT(k) is conditioned on 𝒟∖𝒟k and predicts only on 𝒟k. (c) The fold-wise predictions are concatenated into the out-of-fold soft-label set ~𝒴, so no soft target ~yi is generated by a teacher that conditioned on yi. (d) In the multi-teacher setting, OOF labels from M different TFM families (TabPFNv2.6, TabICLv2, LimiX, TabDPT, …) are averaged with equal weights. (e) The student is trained with a Hinton mixed loss combining temperature-scaled KL on the soft targets and cross-entropy on the hard labels, with per-sample adaptive temperature Ti∈[1,5] and confidence weight wi peaking on moderate-entropy teacher predictions. (f) The trained student is deployed on CPU
Formalization.
In this work, we consider a set of tabular datasets 𝒟={(𝐱i,yi)}ni=1 where 𝐱i∈ℝli×ci and yi∈ℝli;
li is the sequence length and ci is the number of features for the i-th dataset. We also consider a Tabular Foundation Model (TFM) as a teacher fT that predicts the labels using a function fT(⋅):ℝl×c→ℝl.
Given a set of datasets 𝒟 and a TFM fT, we aim to find a student fS:ℝl×c→ℝl that approximates fT without duplicating the teacher’s weights, gradients, or hidden states.
Distillation approach.
To transfer the predictive behavior of fT to fS, we employ knowledge distillation [9], training fS to match the outputs of fT rather than hard ground-truth labels. This choice is motivated by recent empirical works showing that distillation leads to stronger student generalization [22, 26].
We define the student objective as the Hinton mixed loss:
ℒ=α∑iwiTi2KL(p^iTi∥qiTi)+(1−α)∑iwiℓCE(yi,qi),
with α=0.7. For the three tree-based students, the soft loss reduces to a per-sample weighted MSE on soft-label logits.
Adaptive temperature.
Per-sample Ti∈[Tmin,Tmax] scales each ~pi as a function of teacher entropy H(~pi): confident predictions get Ti≈Tmin=1, ambiguous ones get Ti≈Tmax=5, following [7]. Confidence weight wi=exp(−(H(~pi)−μ)2/2σ2) peaks on moderate-entropy predictions ((μ,σ)=(0.7,0.2)).
Teacher soft labels.
In our work, all teachers are TFMs. While all these models rely on in-context learning for predictions, the teachers condition on the training set as part of their input context. More formally, we denote the teacher as fT(⋅∣C) where C={xi,yi} is the context set. Predictions over the samples xi are therefore produced by a teacher that has already observed their targets yi, yielding soft labels that are overconfident compared to the predicted distribution on unseen data.
To mitigate this, we apply k=5 stratified cross-validation, fitting each teacher fT(k) on 𝒟∖𝒟k and predicting only over 𝒟k, ensuring that no sample’s soft target is produced by a fT that conditioned on it.
Multi-teacher averaging.
When more than one TFM family is available, we run the OOF labeling pipeline independently for each teacher and then average the resulting soft labels with equal weights: ~¯pi=1/M∑Mm=1~pi(m), with the multi-teacher case shown in Figure˜1(d). We did not learn ensemble weights or stack the teachers in a second-stage model. The goal here is the cleanest possible baseline for the question does the student get more accurate when you give it more teachers? Section˜4 reports results for several subsets of {TabPFNv2.6, TabICLv2, LimiX, TabDPT, Orion-MSP}.
We treat OOF prediction as a correctness requirement rather than a tunable hyperparameter: every standard distillation pipeline assumes labels generated on points the teacher has not seen. The choice of K=5 follows the stacking convention. Pilot runs at K∈{3,10} moved AUC by less than 0.005 at 0.6× and 2× the teacher cost, respectively, so we did not tune this further.
4 Experiments
4.1 Setup
Datasets.
We use 19 health datasets, of which 16 are binary and 3 multiclass, covering cardiology, oncology, nephrology, dermatology, and critical care, with sample sizes from 299 to 9105 (bigger datasets were sampled from) and feature counts from 4 to 40. Full details are in Table˜6.
Teacher TFMs.
We consider 6 TFMs: TabPFNv2.5 [10], TabPFNv2.6 [6], TabICLv2 [20], TabDPT [13], LimiX [25], and Orion-MSP v1.5 [2], each with its built-in missing-value handler. For multi-teacher (M>1) settings, we average per-fold soft labels with equal weights.
Students.
We use LightGBM [12], CatBoost [19], XGBoost [4] (300 trees, depth 6, patience-30 early stopping) and an MLP (embedding min(8d,128), cosine LR with warmup, label smoothing 0.05, SWA on final 20% of training, collapse-detector restart at higher dropout).
Baselines.
We use LogisticRegression, XGBoost, and LightGBM with a fixed configuration on zero-imputed inputs. These baselines reflect how each model class is typically used out of the box.
Metrics.
We report (i) average AUC; (ii) retention, defined as AUC(Student)/ AUC(Teacher)×100; (iii) model latency and memory consumption; (iv) calibration (ECE, Brier) and fairness (DP-diff, EO-diff). All reported results are aggregated over 5 simulations. All models and runs use identical pre-processing and evaluation as implemented in TabTune [23].
4.2 Empirical Results
Accuracy.
Table˜1 shows the average AUC and retention on LGBM and MLP on the 16 binary datasets. Results for the other student models are in Table˜7, and the corresponding multiclass numbers are in Table˜8.
Table 1:Avg AUC and retention on LGBM and MLP over the binary datasets.
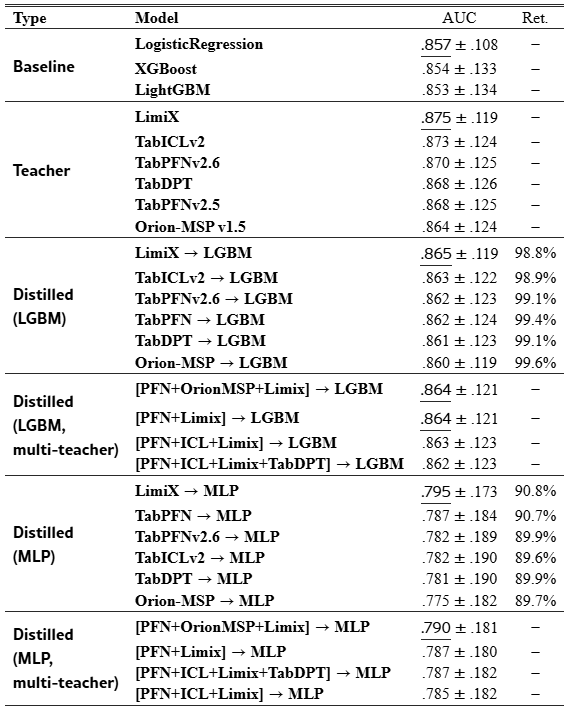
Distillation is strongly student-dependent. Tree-based students benefit most: LightGBM retains 98.8–99.6% of teacher AUC and improves over the default LightGBM baseline, while Table˜7 shows that CatBoost and XGBoost can reach or exceed 100% retention. This suggests that distilled students can sometimes outperform their teachers, consistent with distillation acting as a regularizer through softened targets rather than only as compression. In contrast, MLP students retain only 89.6–90.8% and remain below the default baselines. The tree–MLP retention gap is consistent with what tabular ML has long observed: tree splits handle heterogeneous feature scales without preprocessing, while MLPs need careful regularization to compete. On our small-cohort benchmark, the MLP student is asked to regularize and distil at the same time; Section˜5 discusses the specific failure modes we observed. Multi-teacher distillation also gives limited gains: except for CatBoost, the best multi-teacher student does not outperform the best single-teacher student, suggesting that uniform averaging can add noise when teachers disagree [5].
Latency and memory.
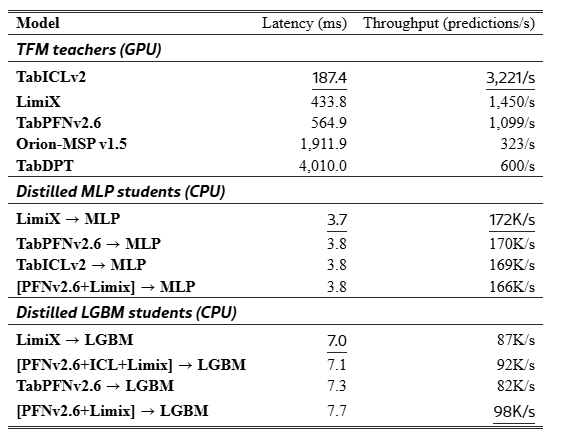
Table˜2 reports latency on 6 datasets; full results are in Table˜9. Students run on CPU, while TFM teachers run on GPU. Distilled LGBM and MLP students require about 7 ms and 3.8 ms, respectively, versus 187.4 ms for the fastest teacher, yielding roughly 26× and 49× lower latency while staying under 1 MB. This makes distilled students suitable for CPU-only, high-throughput healthcare deployment: batch retrospective scoring across millions of records, or ICU streaming inference where every millisecond counts, become straightforward at 49K–80K predictions per second per CPU core.
Table 2:Inference latency and throughput across datasets
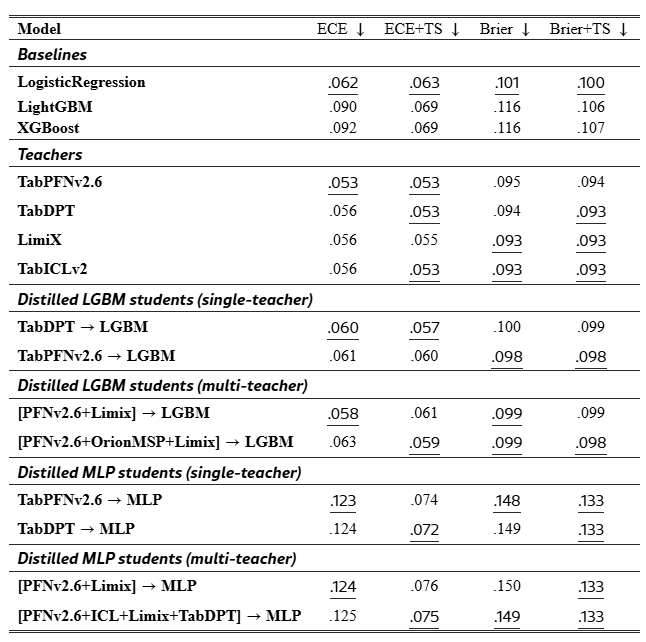
Calibration.
Table˜3 reports ECE and Brier scores on 12 binary datasets, with and without global temperature scaling (TS) [7, 18]. Distilled LGBM students preserve much of the teachers’ calibration, with ECE around .058-.063, substantially better than default LightGBM and XGBoost. TS provides only small additional gains for LGBM students, suggesting that they are already reasonably calibrated. In contrast, MLP students are poorly calibrated before TS, with ECE above .12, but improve markedly after scaling. Thus, calibration quality is strongly student-dependent: distilled trees are reliable without much post-hoc correction, whereas MLP students require calibration.
Two further observations are worth noting. First, the default GBDT baselines (XGBoost, LightGBM) show the largest absolute ECE drop from temperature scaling (0.090→0.069), consistent with the well-known tendency of tree models to be overconfident at the leaves [16]. Any deployment that uses raw GBDT scores as risk probabilities will therefore need a calibration step. Second, the MLP miscalibration is dominated by overconfidence on the larger cohorts (support2, sick); on reliability diagrams the high-confidence bins consistently overshoot, which TS rescales globally but does not fix per-region.
Table 3:Avg ECE and Brier on 12 binary datasets w/o global temperature scaling (TS).
Fairness.
Table˜4 reports DP- and EO-difference across 8 datasets and 4 sensitive attributes. Negative Δ values mean the student has a smaller fairness gap than its teacher. Distilled LGBM students reduce DP gaps and EO gaps in most cases, with average ΔDP =−0.013 and ΔEO =−0.014, consistent with soft-label smoothing in a smaller hypothesis class. MLP students reduce DP more strongly (ΔDP =−0.034), but often increase EO gaps (ΔEO =+0.041). Thus, LGBM provides a more stable fairness tradeoff, while MLP can improve parity in prediction rates at the cost of subgroup error disparities.
Table 4:Group fairness across 8 datasets and 4 attributes. In multi-teacher settings, Δ are computed with TabPFNv2.6.
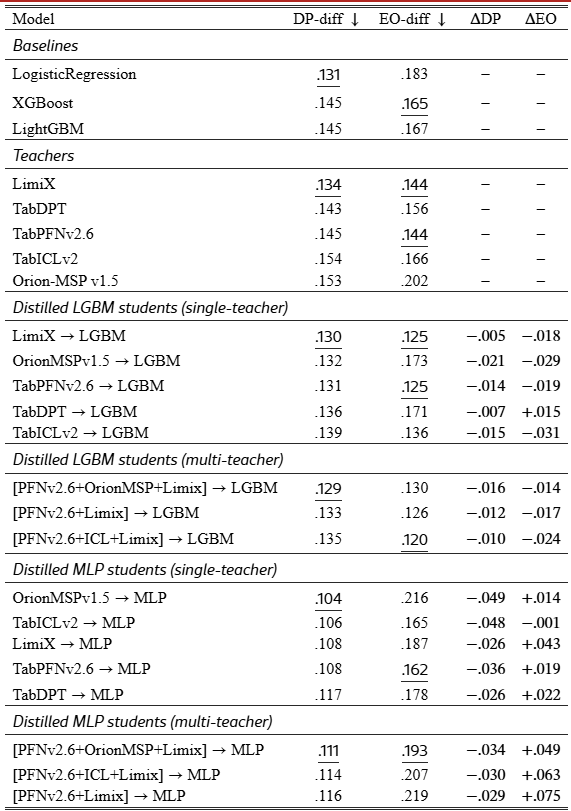
The pattern is consistent with a smaller hypothesis class plus soft-label smoothing acting as a fairness regularizer for the LGBM student. The MLP shifts in the opposite direction on EO: smaller prediction-rate gaps, but larger subgroup error disparities on pima_diabetes, sick, and a few of the larger cohorts. Practitioners should treat the EO regression as a real concern and audit it on the actual sensitive attributes of their deployment, not extrapolate from the table alone.
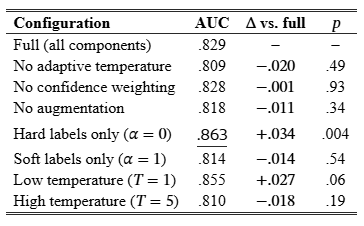
Component ablation.
Table˜5 ablates MLP distillation with TabPFNv2.6 on 5 datasets. Hard-label training outperforms the full setup by 0.034 AUC (p=0.004), while removing adaptive temperature, confidence weighting, or augmentation changes AUC by at most 0.02. Thus, for MLPs, the soft-label machinery adds little on this benchmark; we leave tree-student ablations to future work.
Table 5:Ablation on the MLP student with TabPFNv2.6 teacher on 5 datasets. Δ is the paired difference vs. full; p from a Wilcoxon signed-rank test on per-(dataset, simulation) deltas.
5 Discussion and Limitations
In this section, we discuss the main limitations of our work and a few design decisions worth flagging for practitioners.
MLP instability on small low-dimensional inputs.
The MLP student is unstable on small low-dimensional inputs. On three datasets with under 750 samples and 4–8 features (blood_transfusion, indian_liver_patient, pima_diabetes), it showed high seed-to-seed variance and occasionally collapsed to near-random predictions. The library has a collapse detector that restarts training with higher dropout, but the underlying issue is that a residual MLP is overparameterised for these inputs. The LGBM student does not have this problem. Recommendation: use LGBM by default and consider an MLP student only when inference latency under 2 ms is a hard requirement.
Multiclass distillation gap.
TabPFNv2.5 scores 0.985 AUC on the kidney disease dataset (3 classes, 400 rows), while its distilled TabPFN→LGBM version scores only 0.749. The reason is that the soft-label distillation breaks for problems in the 3+ class due to the LGBM regressor formulation we use. A multinomial-loss formulation would be the proper fix; until that lands, multiclass distillation should be treated as experimental.
Why uniform multi-teacher averaging did not help.
Table˜1 shows the best multi-teacher LGBM student tied, rather than beat, the best single-teacher student at three decimal places. Two factors are likely at work. The TFM teachers are themselves close in AUC (0.864–0.875), so the headroom for ensemble gain on these datasets was small to begin with. And equal-weight averaging treats teacher disagreement as additional information even when the disagreement is closer to noise; [5] formalises this for distillation. A learned or accuracy-weighted scheme could plausibly close the gap, especially in regimes where one teacher is meaningfully stronger than the others. We leave that for follow-up work.
Hard-label ablation.
Table˜5 shows that hard-label training (α=0) outperforms the full pipeline (α=0.7) by 0.034 AUC (p=0.004, Wilcoxon) on the MLP. This does not affect the need for out-of-fold labeling: for ICL teachers, scoring examples that appear in the context can produce overconfident soft targets and leakage. Rather, the result suggests that, on small relatively clean datasets, the added soft-label components do not improve MLP training. Soft targets may be more useful in noisier or higher-dimensional clinical settings, where hard labels are less reliable. The matching LGBM ablation is left to future work; on partial LGBM ablation runs we have completed, the components again contribute less than the per-dataset variance.
6 Conclusion
In this work, we argued that TFMs predict well on small health datasets but are costly to deploy in inference-constrained health settings. We proposed a methodology around knowledge distillation to transfer predictive behavior from TFMs to simpler standard models, and ran extensive experiments on 19 healthcare datasets. Our results show that distilled models run, on CPU, at least 26× faster than the best TFMs on GPU. While knowledge transfer recovers at least 90% of TFM accuracy, it also preserves calibration and fairness. As a practical recommendation: use an LGBM student by default, and consider an MLP student only when sub-2 ms latency is a hard requirement.
More broadly, this paper argues that TFM inference cost reflects how TFMs do inference (context-conditioned GPU forward passes) rather than something intrinsic to their accuracy. Out-of-fold distillation moves that cost off the deployment surface without losing the accuracy.
7 Impact and Ethical Considerations
Lowering the deployment bar.
The practical effect of this work is that TFM-quality predictions on small clinical datasets no longer require a GPU. A 7 ms LightGBM student that fits in under 1 MB can run inside hospital systems that today cannot host a TabPFN forward pass: CPU-only nodes, air-gapped environments, registry-scale batch jobs, embedded scoring at the point of care. This widens the set of settings where recent TFM accuracy is reachable, particularly in resource-limited deployments or those with data-residency constraints.
Bias inheritance.
A distilled student inherits whatever bias the teacher carries. On the 8-dataset, 4-attribute fairness benchmark we report, distilled LGBM students stayed close to teacher DP- and EO-difference, with average ΔDP of −0.013 and average ΔEO of −0.014. MLP students cut DP-difference more strongly but increased EO-difference on several datasets, meaning prediction rates equalised at the cost of subgroup error rates. Any deployment should audit the specific student-teacher pair on the actual sensitive attributes that matter for the use case. Generalising from our table to a different cohort or attribute is not safe.
Calibration and decision support.
A clinical model whose probabilities are off cannot be plugged into a threshold-based decision rule without a calibration step. Distilled LightGBM students preserve teacher calibration without much post-hoc correction; MLP students need temperature scaling before deployment. Practitioners should not skip this step.