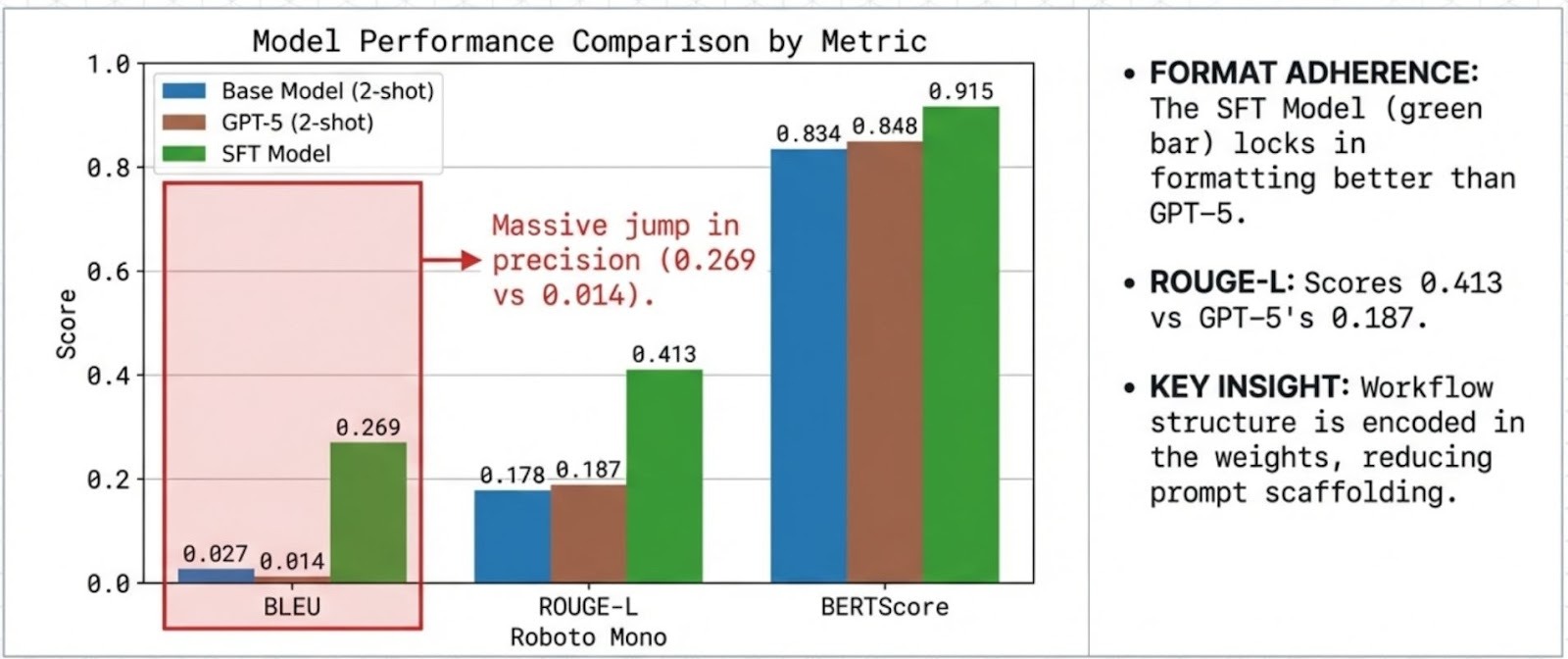
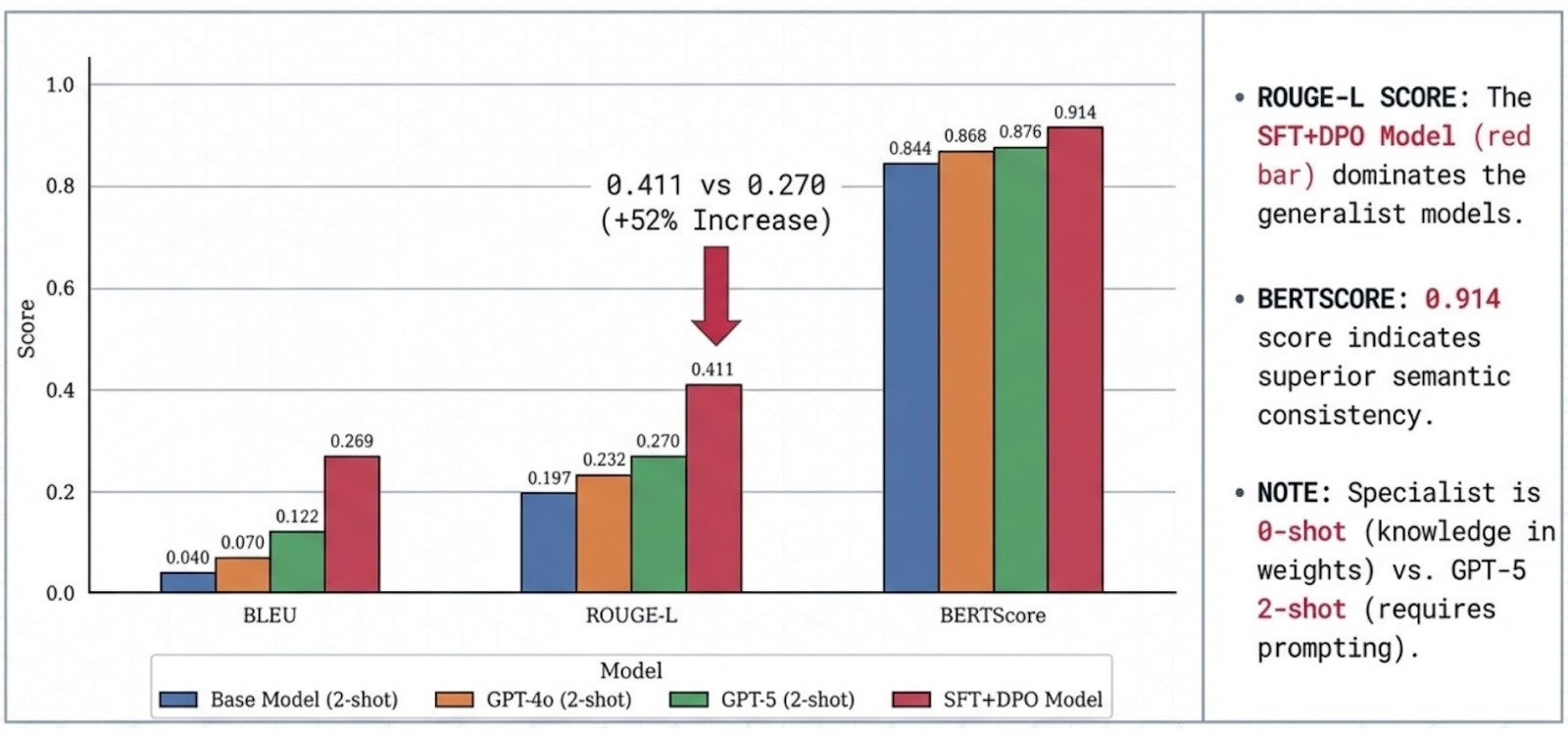
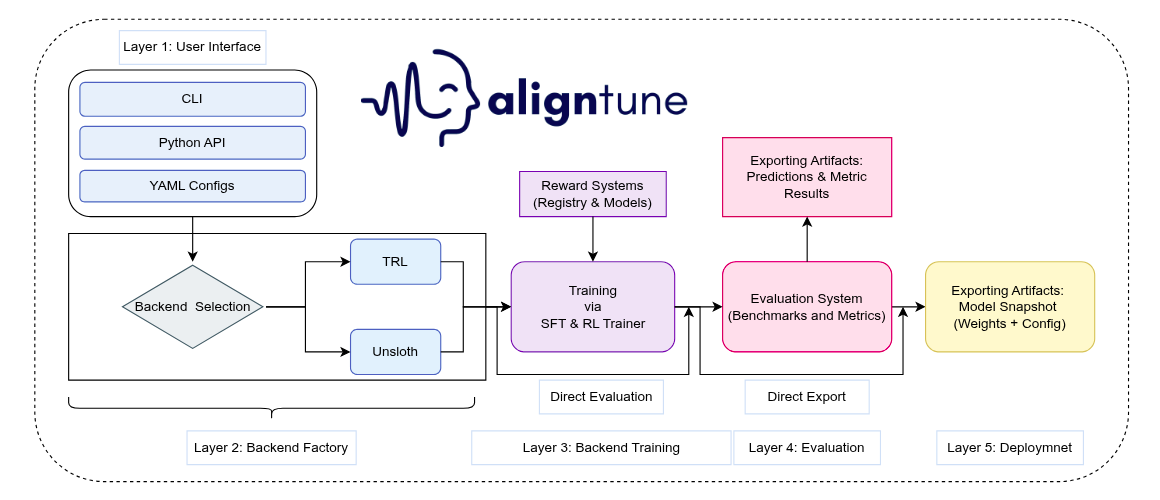
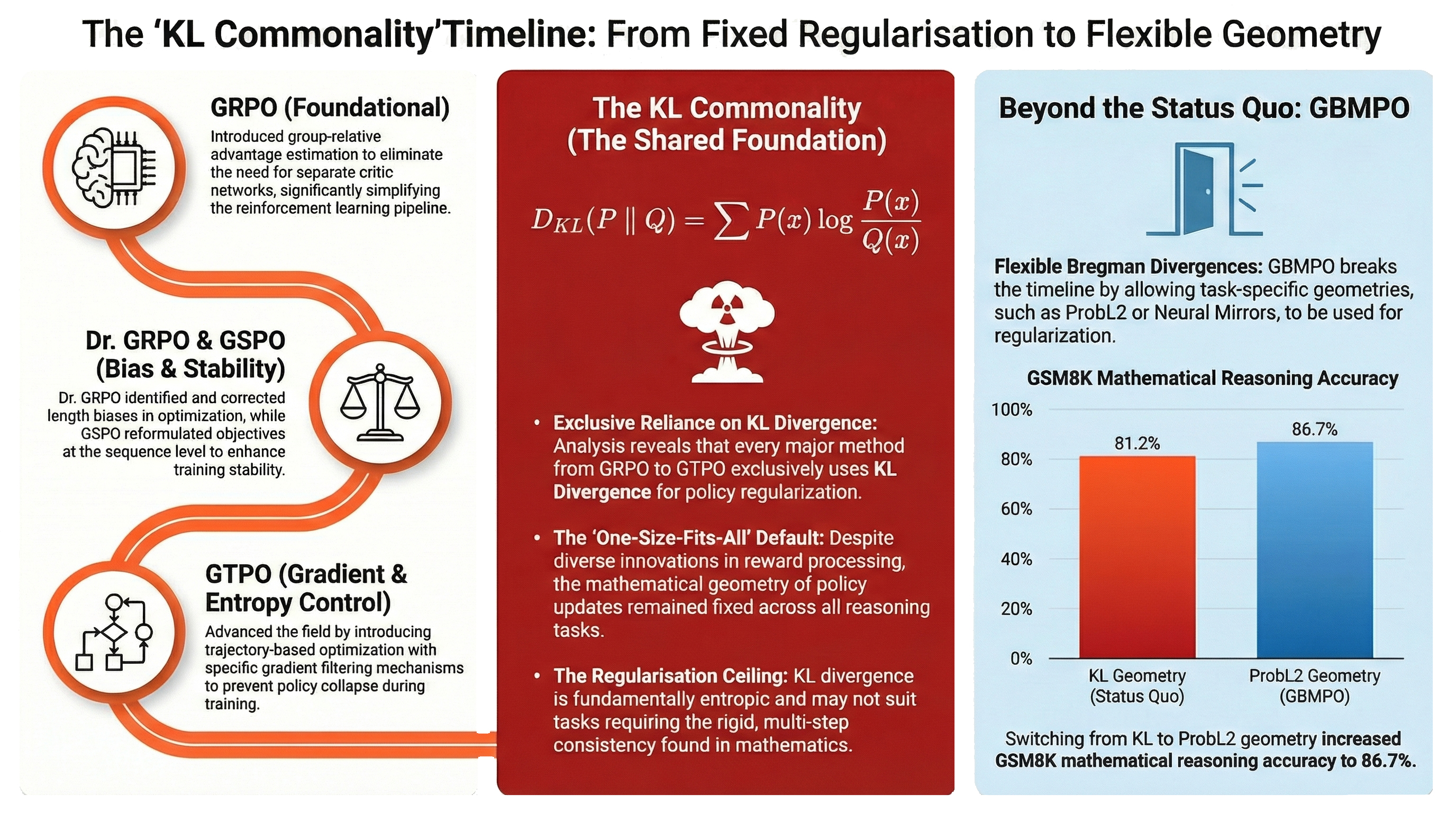
AlignTune is a modular post-training alignment toolkit that helps you take a base LLM and tune it into a dependable, policy-aware assistant. It brings the full alignment workflow under one roof, from supervised fine-tuning (SFT) to preference optimization and RL-style training (including methods like DPO, PPO, SimPO, and more), so you can improve instruction-following, reduce unwanted behavior, and shape responses to match your product voice. AlignTune ships with ready-to-run recipes, configurable trainers, and a rich library of reward functions (30+ choices) to steer tone, helpfulness, safety, and consistency without rewriting your training stack every time you try a new approach. Built for research-to-production iteration, it makes alignment experiments repeatable, comparable, and easy to scale, so teams can move from “it works on my notebook” to “it behaves reliably in production” with far less friction.